-
-

-
-
braintrust

Inspiration
Everyone talks about self-improvement, but most people don't have access to a coach — and the apps that exist are just text boxes with motivational quotes. We kept coming back to the same observation: when you talk to a good coach or therapist, they're not just listening to your words. They're reading your tone, your energy, the hesitation in your voice. That's where the real signal is.
We asked ourselves: what if an AI coach could do the same thing? Not just process what you say, but how you say it — and adjust in real-time? That gap between text-based chatbots and emotionally-aware voice interaction became the core idea behind Project Evo.
What it does
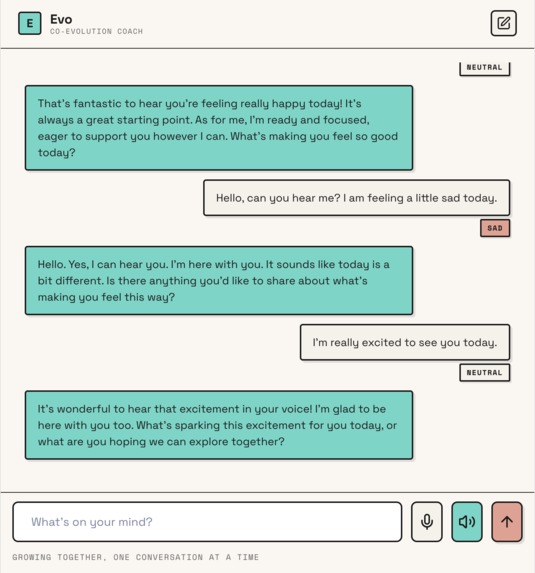
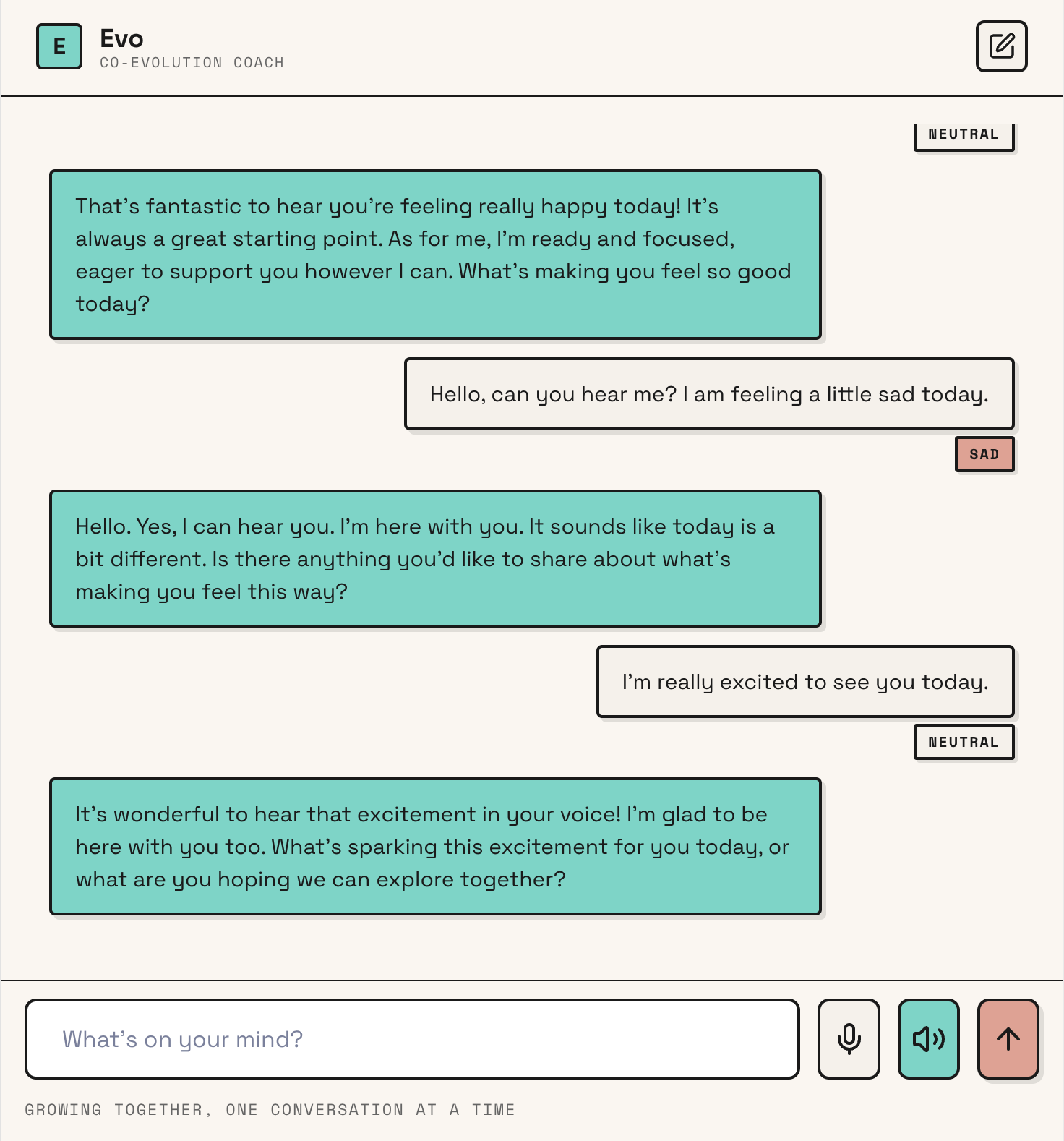
Evo is a voice-first self-improvement coach that listens to both your words and your vocal patterns. When you speak to Evo, it detects your emotional state — stress, energy, anxiety, calm — through voice analysis powered by Modulate AI's Velma model. That emotional context gets fed directly into Google Gemini, so the coaching response adapts to how you're actually feeling, not just what you said.
The coaching itself isn't generic. Evo offers four distinct personas built on proven frameworks:
- Growth Coach — Carol Dweck's growth mindset methodology with the GROW model
- Accountability Partner — direct habit tracking using implementation intentions
- Stoic Mentor — Marcus Aurelius, Seneca, and Epictetus applied to modern life
- CBT Coach — cognitive behavioral techniques for reframing thought patterns
Users can set and track goals that persist across sessions. The coach references your active commitments, surfaces patterns in your behavior, and holds you accountable over time. Switch personas mid-session when the conversation calls for a different approach.
How we built it
We developed Evo in Cursor, Claude Code, and SolveIt which let us iterate fast with AI-assisted coding across the full stack. The core architecture:
- Reflex Dev for the full-stack application — frontend and backend in pure Python, no JavaScript. Reflex compiles to React/Next.js under the hood while keeping us in one language. State management runs over WebSockets so voice sentiment, chat streaming, and goal tracking stay in sync reactively.
- Google Gemini as the coaching intelligence — we use Gemini's large context window and instruction-following capabilities to power the coaching personas. Each persona has a carefully engineered system prompt built on real therapeutic frameworks, and Gemini handles the nuance of adapting tone based on the voice sentiment context we inject. We route calls through LiteLLM for provider flexibility.
- Modulate AI for voice intelligence — their Velma model analyzes vocal patterns to detect emotion, stress levels, and energy in real-time. We built an integration client that sends audio segments to their API and returns structured sentiment data that enriches every coaching interaction.
- Braintrust AI for evaluation and observability — we use Braintrust to trace every coaching interaction, score response quality, and catch regressions when we tweak prompts or switch personas. It turns what would otherwise be vibes-based prompt iteration into measurable experiments. We built eval datasets from real coaching scenarios to validate that emotional adaptation actually works — does a stressed user get a gentler response? Does the accountability partner actually track commitments? Braintrust gives us the signal.
- Web Speech API for browser-native speech-to-text and text-to-speech — zero infrastructure cost, works in Chrome and Edge out of the box.
Challenges we ran into
Modulate AI is enterprise-first. Their Velma API isn't a self-serve developer product — it's built for gaming studios and contact centers with custom integrations. We had to design our integration layer against their documented capabilities and build a mock analyzer that approximates their output using basic audio signal processing (RMS energy for engagement, zero-crossing rate for stress). The architecture is ready for their full API the moment we get access.
Getting Gemini to genuinely adapt, not just acknowledge. Early versions would say "I can hear you're stressed" and then respond exactly the same way. The model acknowledged the emotion without changing its behavior. We solved this by embedding voice sentiment directly into the system prompt with behavioral instructions rather than just data labels — and used Braintrust evals to measure whether the response tone actually shifted across emotional states.
Evaluating subjective coaching quality. How do you score whether a coaching response is "good"? We built custom Braintrust scorers that measure: response length adaptation (voice mode should be concise), emotional tone matching (stressed input → gentler output), goal reference accuracy (does the coach cite the right commitments), and framework adherence (is the CBT coach actually using the ABC model?). Getting these scorers calibrated was harder than writing the prompts.
Voice-to-coaching latency. The pipeline is: speak → STT transcription → voice analysis → Gemini prompt construction → streaming response → TTS playback. Every millisecond matters for a conversational experience. We optimized by running voice analysis in parallel with STT, using async streaming to start TTS before the full response completes, and keeping the context window lean with a 20-message sliding history.
Reflex Dev with real-time browser APIs. Reflex is powerful for Python developers, but wiring up browser-native APIs (Web Speech, audio capture) required bridging into JavaScript via rx.call_script and hidden input elements for state sync. Cursor's AI assist helped us navigate the undocumented patterns here.
Accomplishments that we're proud of
- The emotional feedback loop actually works. When you speak to Evo stressed and then speak again calmer, the coaching tone shifts noticeably. Braintrust evals confirm this isn't just perception — the response characteristics measurably change.
- Four coaching personas with real depth. These aren't prompt templates with different adjectives. Each persona uses a distinct therapeutic framework with specific techniques (GROW model, ABC model, dichotomy of control, implementation intentions). They coach differently, and we can prove it through evals.
- Eval-driven prompt development. Every prompt tweak runs through Braintrust before we ship it. We know exactly which changes improved coaching quality and which introduced regressions. No more shipping on vibes.
- Pure Python, top to bottom. No JavaScript, no separate frontend repo, no REST API glue code. One language, one codebase, clean separation of concerns. Cursor made this even faster.
- The mock voice analyzer. Even without full Modulate AI API access, the heuristic analyzer provides a working development experience that demonstrates the complete emotional adaptation pipeline.
What we learned
Voice carries more signal than text. This sounds obvious, but building around it changes everything. A typed "I'm fine" and a spoken "I'm fine" with a shaky voice are completely different inputs — and the coaching response should be completely different too. Modulate AI's approach of analyzing voice natively rather than just transcribing to text is the right architecture.
Evals are the unlock for AI coaching quality. Without Braintrust, we were guessing whether prompt changes made the coaching better or worse. With it, we have a feedback loop: change a prompt, run the eval suite, see the score. That discipline turned subjective "does this feel right?" into engineering. The biggest quality jumps came after we built good scorers, not after we wrote better prompts.
Gemini's context window is a coaching advantage. Keeping 20 turns of conversation plus goals plus voice sentiment plus a detailed system prompt requires serious context capacity. Gemini handles this without degradation, which means the coach gets better the longer the session runs — it has more history to draw patterns from.
Cursor accelerates the right kind of iteration. The value wasn't in generating boilerplate — it was in rapid experimentation. We could try a new persona prompt, wire up the Braintrust eval, run it, and iterate in minutes instead of hours. The tight loop between writing code and seeing eval results was the real productivity multiplier.
Prompt architecture matters more than prompt engineering. The difference between Evo and a chatbot wrapper isn't one clever prompt — it's the system that assembles the prompt dynamically from persona config, active goals, conversation history, and real-time voice sentiment. The architecture makes every individual prompt better.
What's next for Evo
- Production Modulate AI integration — move from mock analyzer to Velma's full API for clinical-grade emotion detection and longitudinal voice biomarker tracking
- Deeper Braintrust eval coverage — expand scorers to measure long-term coaching outcomes across multi-session arcs, not just single-turn quality
- ElevenLabs TTS upgrade — replace browser speech synthesis with natural, emotionally-expressive voice output that matches the coaching persona
- Session persistence — database-backed conversation history and goal tracking with progress analytics over weeks and months
- Guided exercises — breathing exercises, thought records, gratitude journaling, and evening reflections triggered contextually by the coach
- Multi-modal input — camera-based facial expression analysis layered alongside voice sentiment for richer emotional context
- Outcome measurement — track self-reported wellbeing scores over time correlated with coaching engagement patterns to prove efficacy

Log in or sign up for Devpost to join the conversation.