-
-
Architecture diagram
-
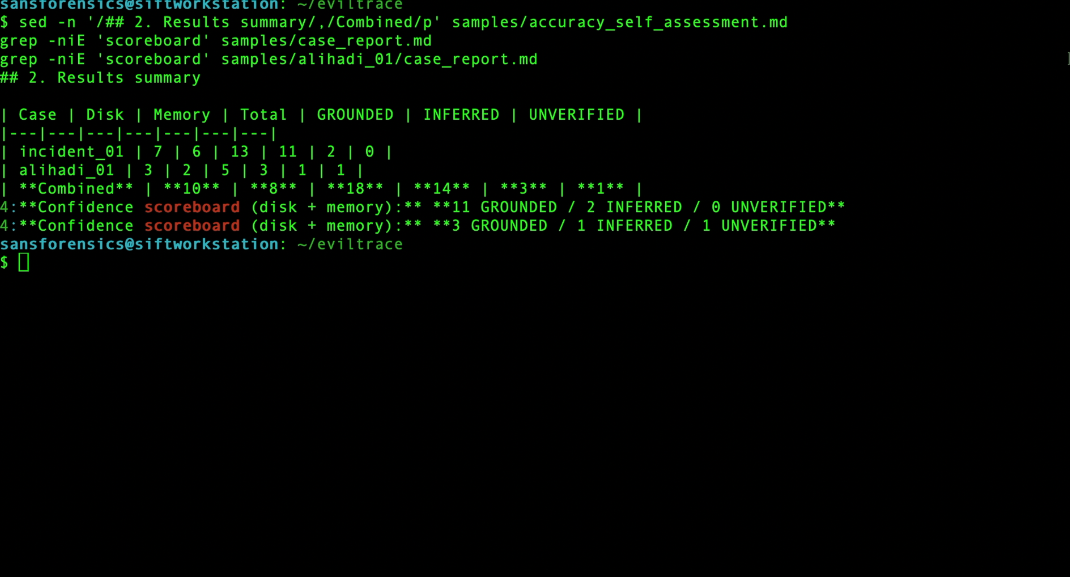
Scoreboard table (18 · 14/3/1)
-
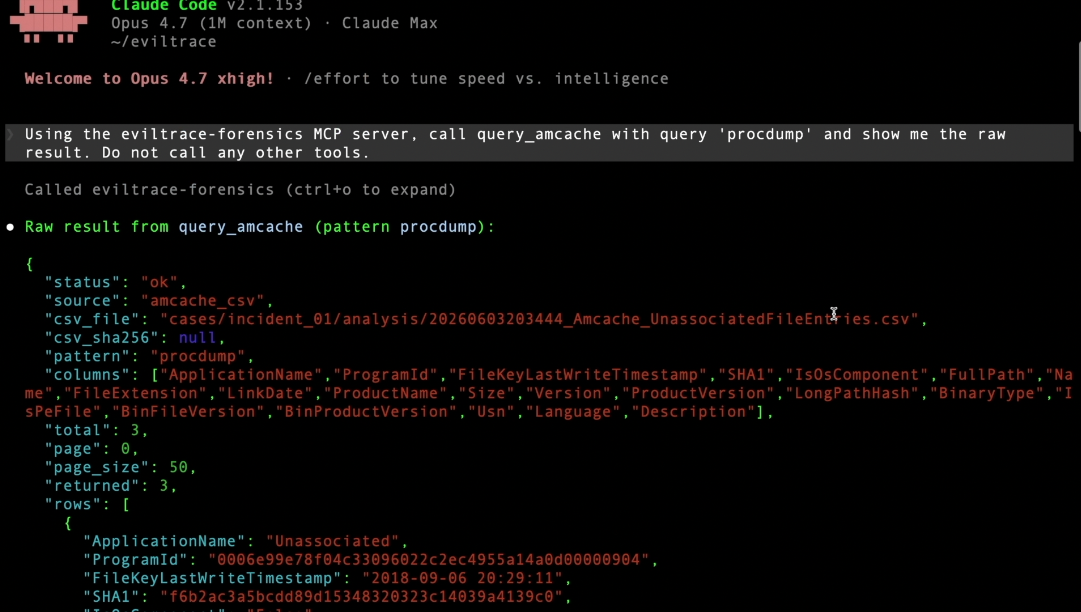
MCP frame (csv_sha256: null)
-
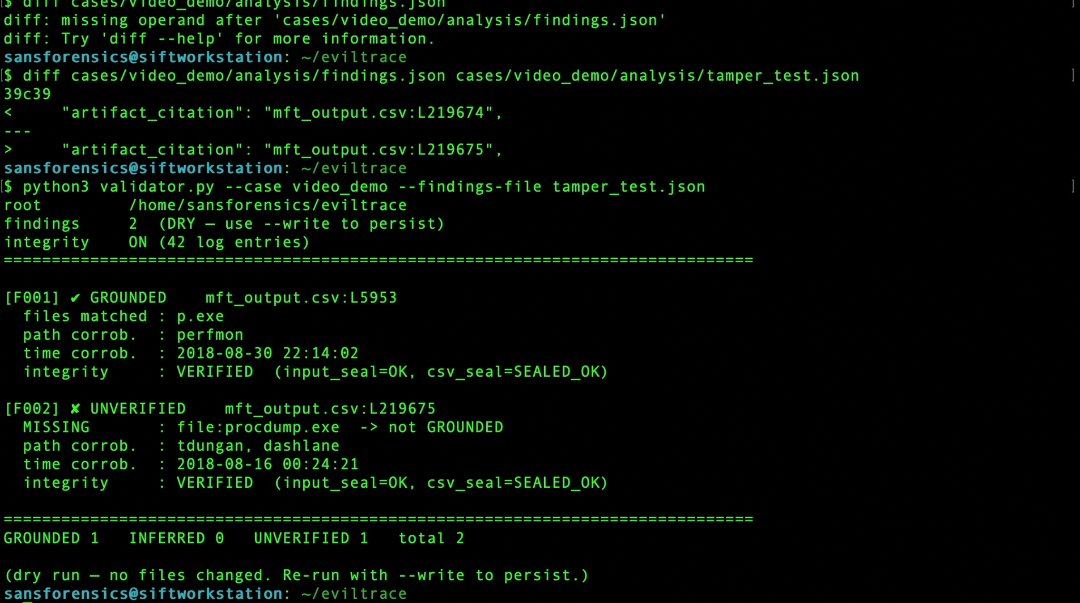
Tamper frame (UNVERIFIED claim + VERIFIED integrity)
-
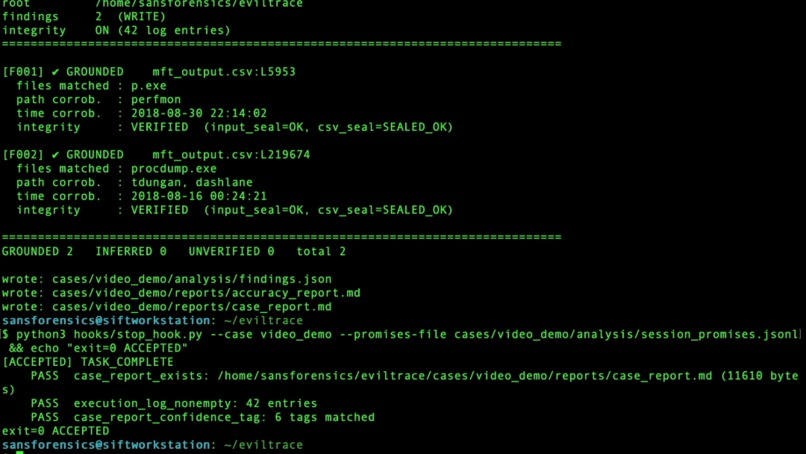
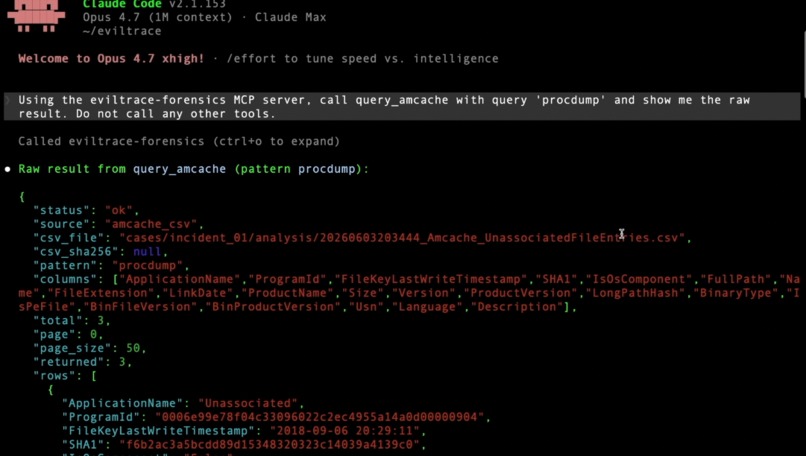
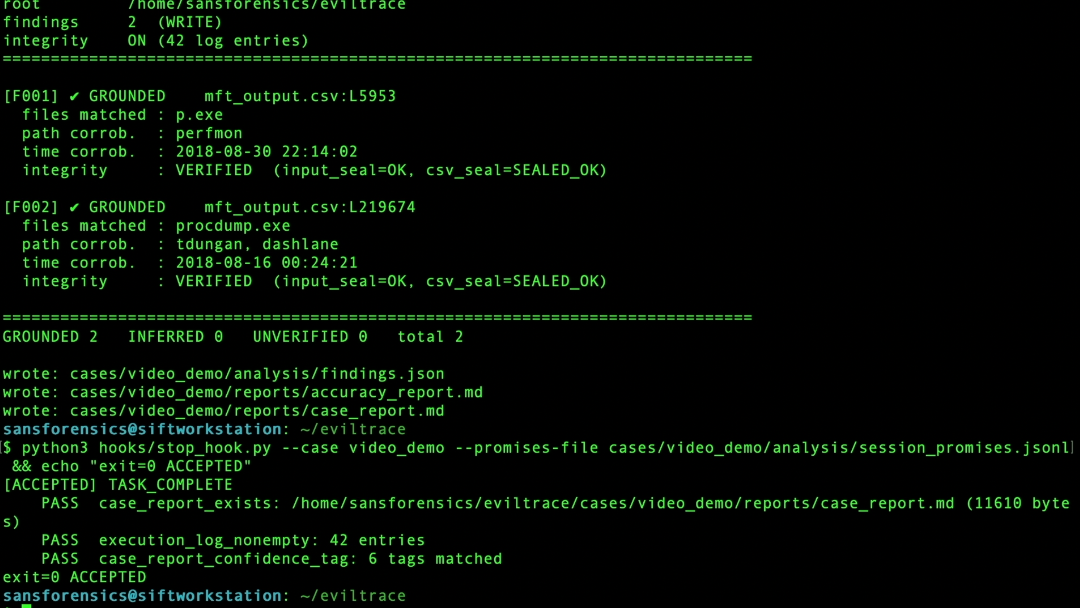
Deterministic validator grounds each finding (p.exe, ProcDump) against SHA-256-sealed tool output
-
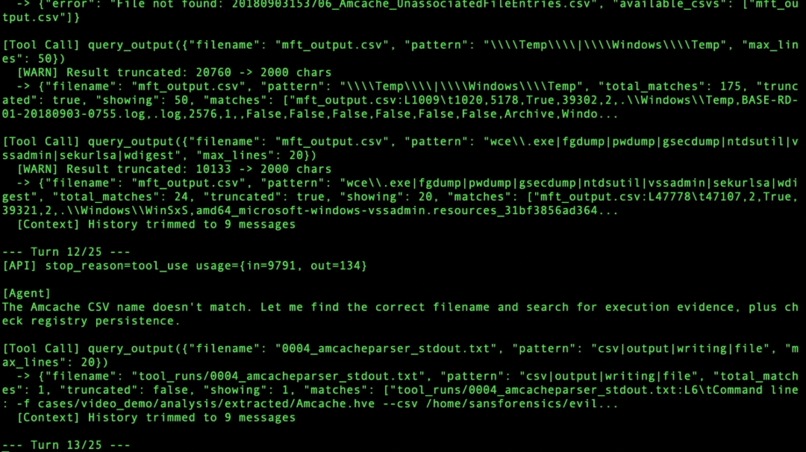
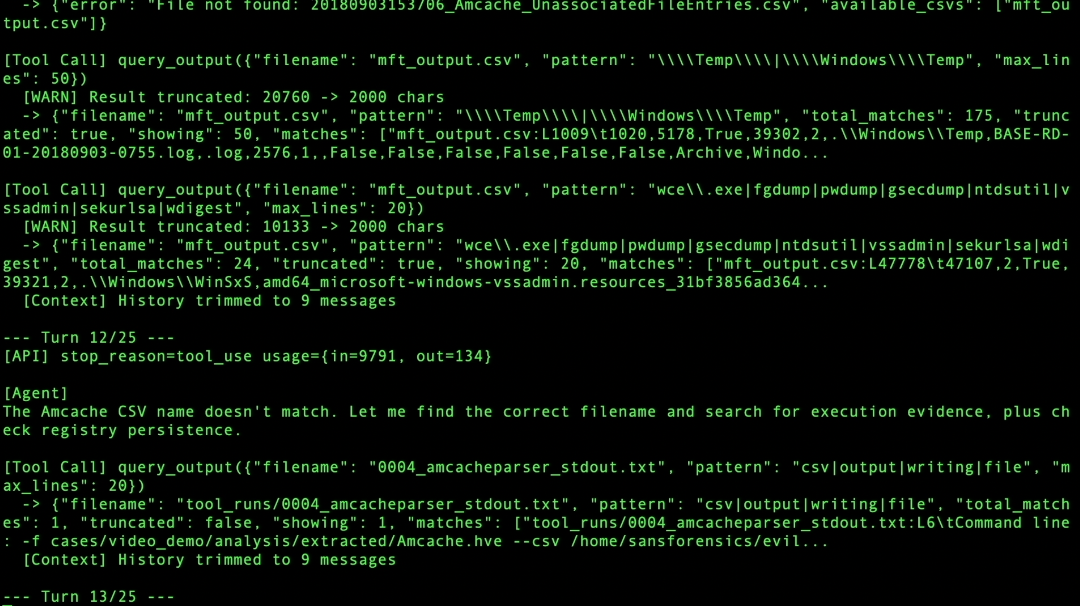
Self-correction (Turn 12/25
EvilTrace — it doesn't just find the evil. It proves how it found it.
Inspiration
Autonomous DFIR agents are fast — but they hallucinate, confidently reporting artifacts, paths, or hashes that were never in the evidence. Protocol SIFT names hallucination as its primary unsolved risk, and Brian Carrier, creator of The Sleuth Kit, has documented an AI inventing evidence during triage. An incident responder cannot act on a finding they cannot trust. EvilTrace is that fix, automated: a fast autonomous investigator that is structurally incapable of quietly reporting something the evidence does not support.
What it does
EvilTrace is an autonomous incident-response agent for the SANS SIFT Workstation. It runs forensic tools against real disk and memory evidence, reasons about what to do next, recovers from its own errors, and then — before any finding ships — validates it against SHA-256-sealed raw tool output using a deterministic, LLM-free verifier.
Every finding carries a confidence tag assigned by code, never by the model:
- GROUNDED — the cited line literally contains the claimed evidence (filename, hash, size, offset, IP).
- INFERRED — a defensible deduction across grounded facts, but not a single literal line.
- UNVERIFIED — no backing line; excluded from conclusions.
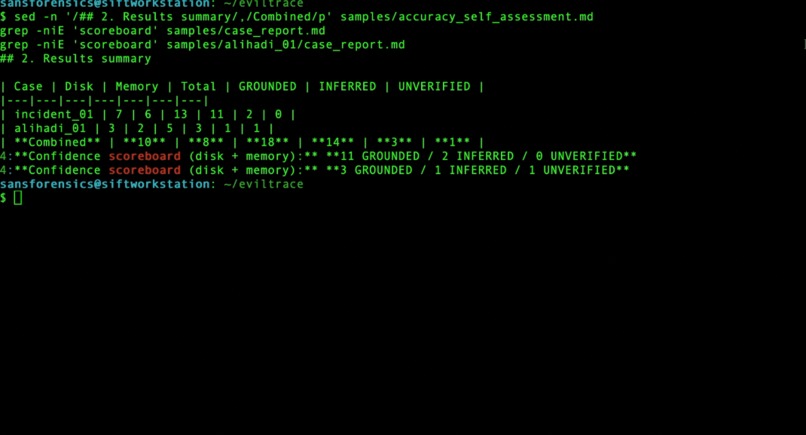
Across two hosts it produced 18 findings — 14 GROUNDED / 3 INFERRED / 1 UNVERIFIED, every count reproducible from committed files in the repo. Its standout autonomous discovery: ProcDump, a credential-dumping tool, masquerading inside the user's Dashlane password-manager directory — never named in the case briefing; the agent surfaced it on its own. The output is a structured investigative narrative with inline confidence tags, not a raw execution log — so a responder reads conclusions, with the proof one click away.
How I built it
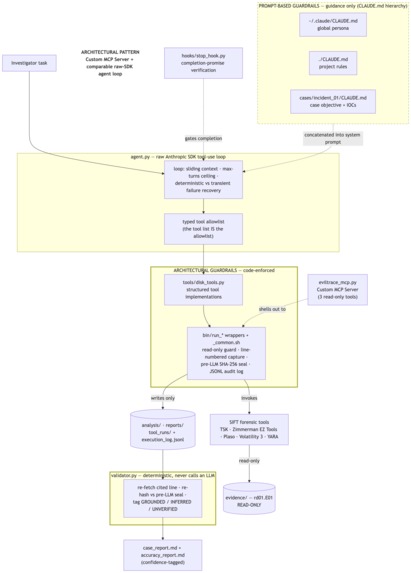
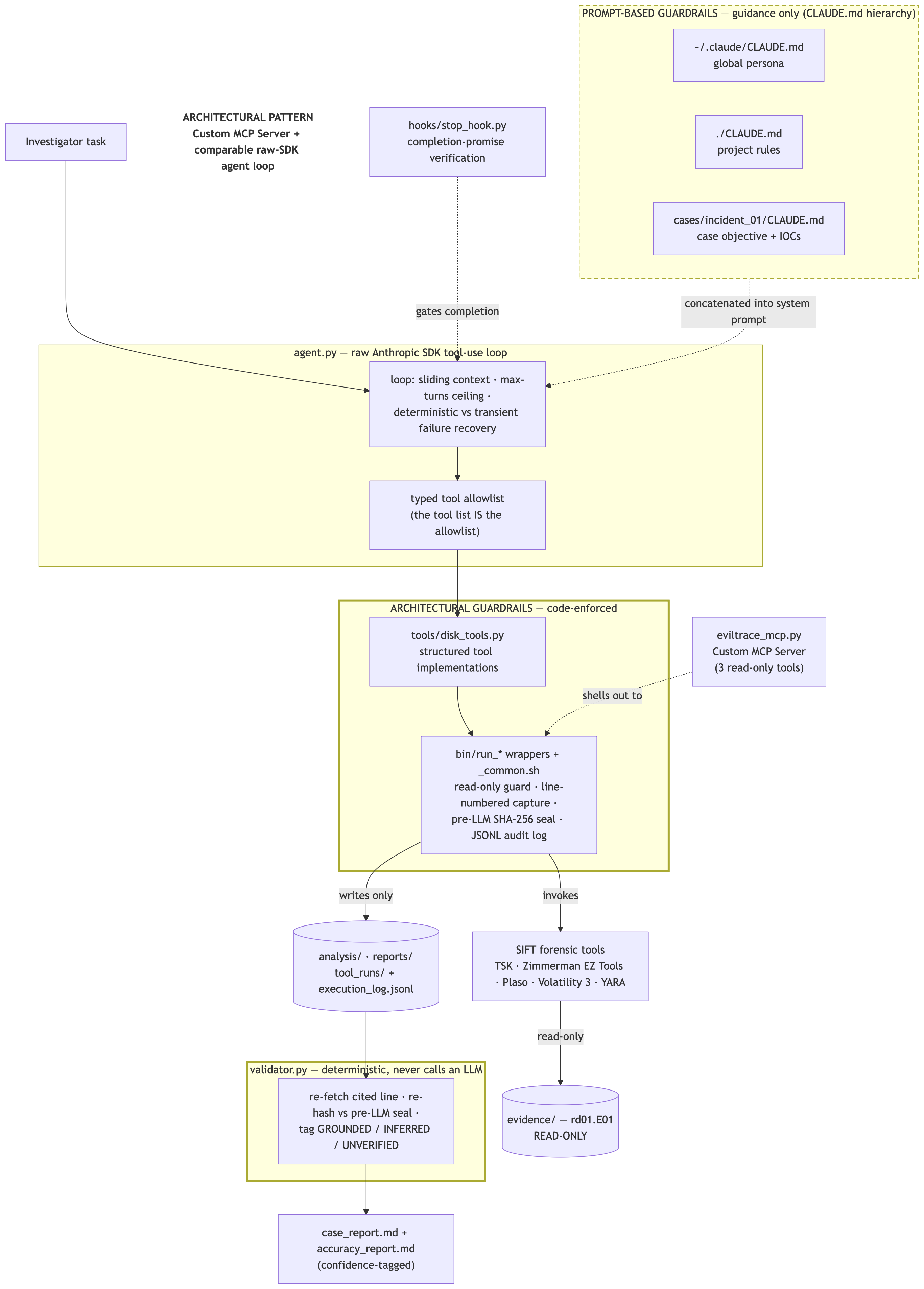
The orchestrator is a raw Anthropic SDK tool-use loop (agent.py, Claude claude-sonnet-4-6) — a comparable agentic architecture permitted by the rules — paired with a first-class Claude Code Custom MCP Server (eviltrace_mcp.py) that exposes the same sealed tool layer to an interactive session.
The design separates two kinds of guardrail, and that separation is the heart of the project:
- Architectural guardrails (code-enforced). The agent has no raw shell. It can only call tools on a typed allowlist, and every tool shells through a read-only
bin/run_*wrapper that refuses to write inside the evidence tree, captures line-numbered output, and SHA-256-seals the raw bytes before any model sees them. A bypass test (tests/test_guardrail.sh) probes this with five paths — including a..traversal and a protected-mount write — and refuses every one. - Prompt-based guardrails (advisory only). The layered
CLAUDE.mdhierarchy shapes how the agent reasons. It is guidance, never the thing that decides what can physically execute.
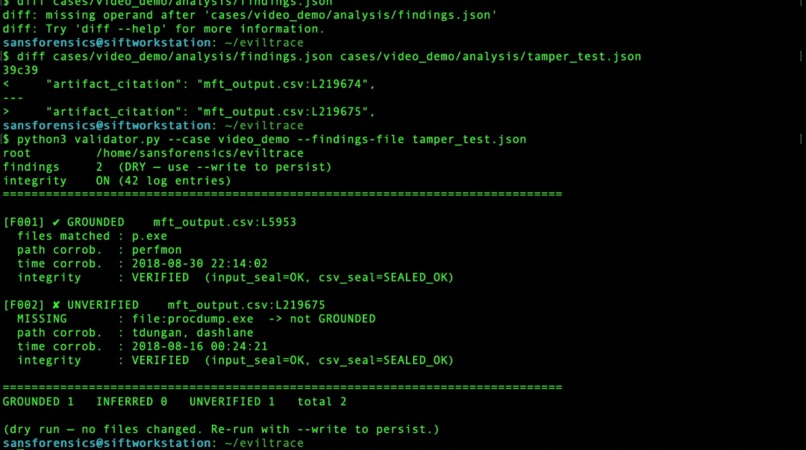
Findings flow into a standalone validator.py — no LLM, no network — which re-opens every cited line and re-hashes the source against the pre-LLM seal. Integrity can only ever lower confidence, never raise it. A completion stop_hook.py rejects "task complete" unless the report exists and carries validated tags, and an append-only execution_log.jsonl records model, prompt, tool, raw output, hash, citation, and confidence — so any finding traces to the exact execution that produced it. Forensic muscle comes from The Sleuth Kit, Volatility 3, Zimmerman EZ Tools, Plaso, and YARA. It was validated on two independent hosts: Operation SHIELDBASE (disk + memory) and the Ali Hadi web-server case (a second host with no answer key, to prove it generalizes).
Challenges
Context amnesia in long runs caused churn loops. The fix was a deterministic per-turn status ribbon — a structural fix, not a prompt tweak — which reduced run length from 25 turns to 8.
Silent success was another challenge. Three independent artifact tells once proved that a run that looked successful had never actually executed. That lesson pushed the validator discipline beyond findings and into the process itself.
The hardest challenge was resisting the temptation to weaken the validator when a finding looked true but did not meet the grounding threshold. EvilTrace keeps the verifier strict and adjusts the claim instead.
What I learned
The most important lesson was that forensic AI should not be judged only by what it finds. It should also be judged by what it refuses to overclaim.
When a finding comes back INFERRED or UNVERIFIED, the correct response is not to lower the evidence standard — it is to tighten the claim until it matches the artifact line. The validator is the source of truth, not the agent.
I also learned that auditability must be designed into the architecture from the beginning. A finding is only useful if a responder can trace it back to the exact command, raw output, hash, citation, and confidence decision that produced it.
What's next
Next, I would expand EvilTrace across more public DFIR benchmark cases and add broader artifact coverage — EVTX, browser history, prefetch, services, scheduled tasks, and additional Linux artifacts.
I would also improve the Claude Code MCP interface so investigators can query validated findings interactively, pivot from a finding to its raw evidence line, and compare confidence across disk, memory, and timeline evidence.
The longer-term goal is multi-host intrusion reconstruction: connecting disk, memory, network, and timeline evidence across an enterprise case while preserving the same SHA-256-sealed grounding model.

Log in or sign up for Devpost to join the conversation.