-
-
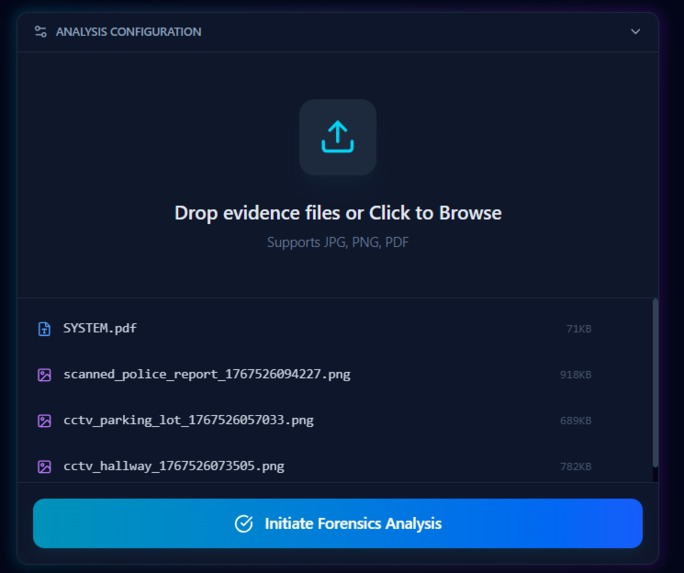
Evidence files
-
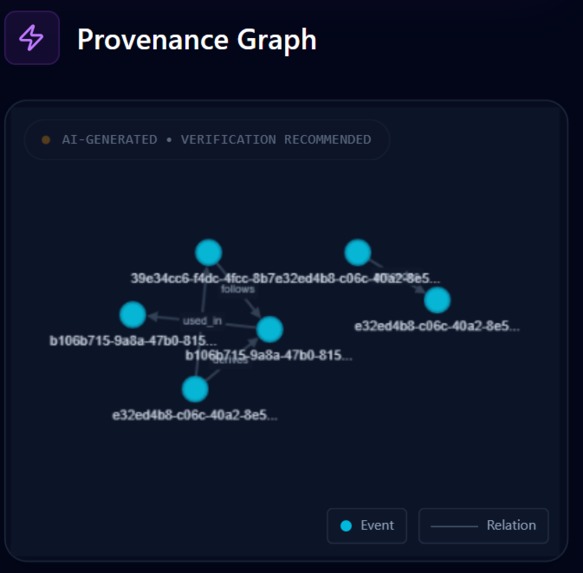
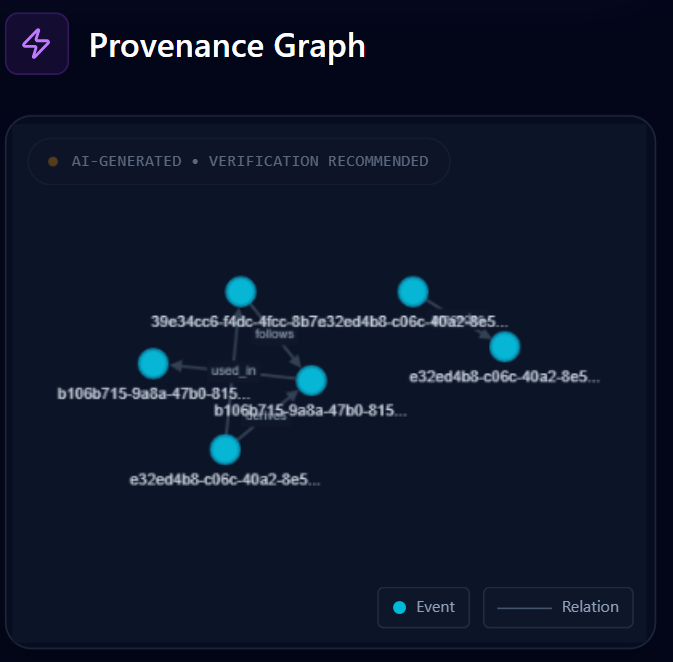
Provenance Graph
-
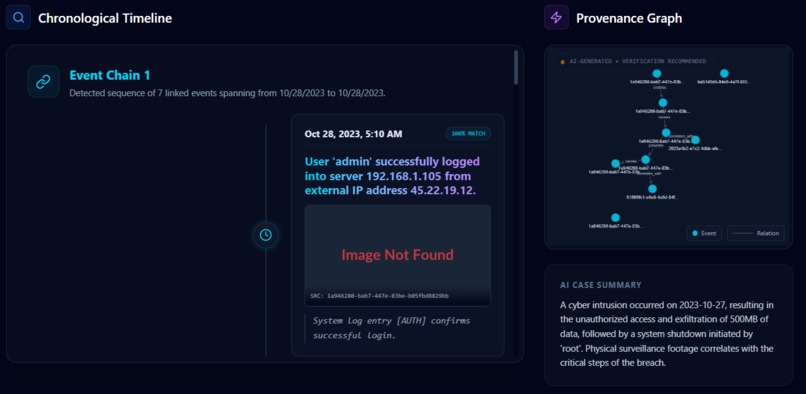
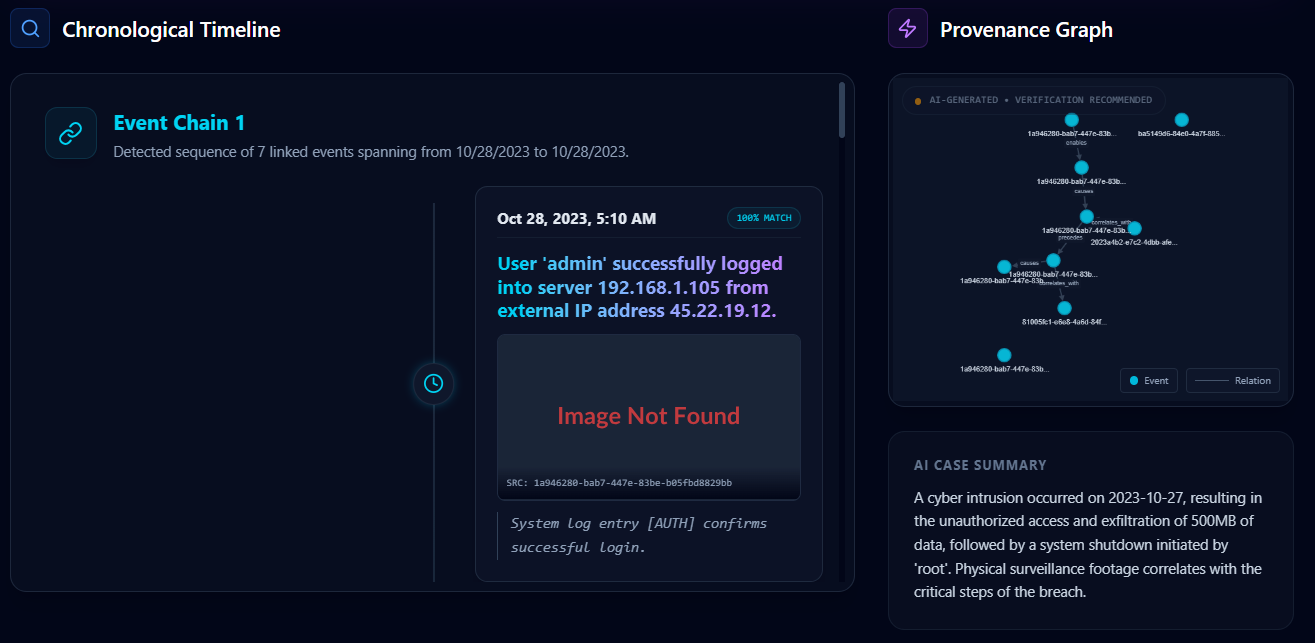
Dashboard view consisting of Chronological Timeline and Provenance Graph
-

AI findings and reasoning based on submitted evidences

About the Project
💡 Inspiration
Modern digital investigations involve thousands of files—images, logs, documents. Investigators often struggle to "see the forest for the trees." We wanted to move beyond linear file lists and build a tool that reconstructs the narrative of an event. Evidex was born from the concept of "Temporal Forensics"—visualizing evidence not just as static objects, but as connected events in time, preserving the sacred Chain of Custody.
🧠 What it does
Evidex is a comprehensive forensics dashboard that transforms raw data into actionable intelligence:
- Ingests Evidence: Accepts nested directory uploads of mixed media (images, logs, PDFs).
- Extracts Deep Metadata: Uses client-side OCR (
tesseract.js) and EXIF extraction (exifr) to pull hidden location data, device models, and timestamps. - Visualizes Connections: A dynamic node-link graph (
cytoscape.js) reveals relationships between files based on shared directories or time proximity. - Reconstructs Timelines: A chronological view (
react-chrono) maps evidence to exact moments in time, allowing investigators to "replay" the incident. - AI Analysis: Integrates Google Gemini to analyze unpacked text content and suggest potential leads or anomalies.
⚙️ How we built it
We architected a modern, high-performance full-stack application:
- Frontend: Built with React 19 and Vite for a responsive experience. We used Tailwind CSS for a premium, "cyber-sleuth" dark-mode aesthetic.
- Visualization: We leveraged
cytoscape.jsfor the intricate evidence graph andreact-chronofor the linear timeline. - Local Intelligence: To improve privacy and speed, we run OCR and metadata extraction directly in the user's browser using Web Workers.
- Visualization: We leveraged
- Backend: A robust Node.js/Express server that handles secure multipart uploads and orchestrates the cloud storage strategy.
- Database: MongoDB Atlas acts as our source of truth, storing complex case metadata and enabling spatial/temporal queries.
- AI Integration: We utilize Google Gemini 1.5 Pro to process extracted text, identifying entities (names, locations) that standard regex might miss.
To prioritize evidence, we concepted a relevance metric $S$ to rank file importance based on temporal proximity and semantic content:
$$ S(e) = w_t \cdot \frac{1}{|t_e - t_{ref}| + \epsilon} + w_c \cdot \text{sim}(c_e, c_{query}) $$
Where $t_e$ is the evidence timestamp, $t_{ref}$ is the incident time, and $sim$ represents semantic similarity.
🛑 Challenges we faced
- The "500" Nightmare: We faced a persistent
500 Internal Server Errorduring the deployment of our upload service. Debugging this required deep diving into multipart boundary parsing and server timeout configurations. - Recursive Chaos: Parsing deeply nested folder structures from a browser drag-and-drop event while preserving the exact directory hierarchy for the "Chain of Custody" tree was algorithmically tricky.
- Graph Performance: Rendering hundreds of connected nodes without turning the browser into a jet engine forced us to optimize our
cytoscapeconfiguration and memoize heavy React components.
🏆 Accomplishments that we're proud of
- Seamless Drag-and-Drop: The feeling of dropping a folder and watching the dashboard populate with parsed data, thumbnails, and graphs in real-time is incredibly satisfying.
- The "Minority Report" Feel: Interacting with the evidence graph—dragging nodes, zooming into clusters—delivers the futuristic investigation experience we aimed for.
- Zero-Knowledge OCR: Implementing optical character recognition entirely on the client side without sending sensitive images to a third-party OCR API.
📖 What we learned
We learned that metadata is the silent witness. A simple file modification timestamp, when placed on a graph, can contradict an alibi. Technically, we gained massive insight into React 19's new hooks, the complexities of hybrid cloud/local storage, and the power of LLMs when applied to structured forensic data.
Built With
- css3
- cytoscape.js
- express.js
- firebase
- google-cloud
- google-gemini
- html5
- javascript
- mongodb
- node.js
- react
- tailwind-css
- typescript
- vite

Log in or sign up for Devpost to join the conversation.