-
-
App
-
App
-
App
-
App
Evidentia
Developed By: Justin Mui, Gordon Huang, and Evan Wu
About Evidentia
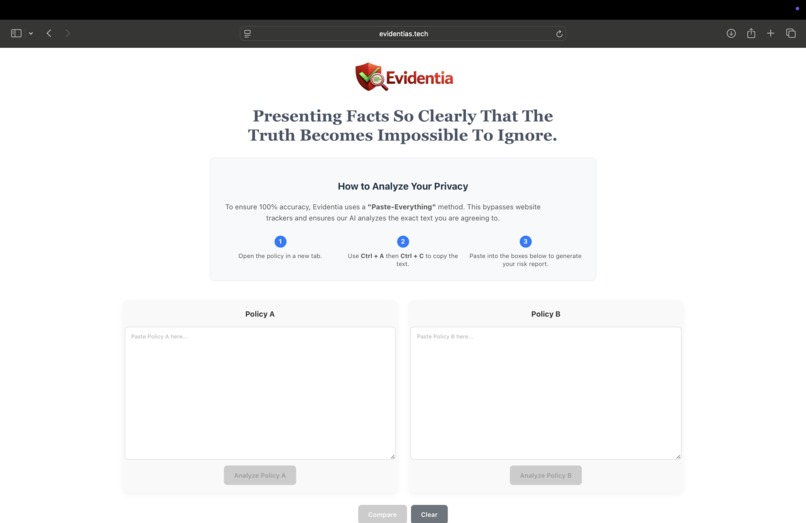
Evidentia helps people understand and compare dense Terms of Service and Privacy Policies by turning them into an evidence backed risk report. Instead of producing a generic summary, Evidentia extracts specific red flags, ties each finding to quoted text, and presents results in a consistent checklist format. It also supports side by side comparisons so users can see what changed between two policies.
Inspiration
We have all experienced paying for a "free trial" because we forgot to cancel it in time. Or maybe falling for "you can change this plan anytime" clause but in reality, your stuck with them for the next ten years. This process is very fustrating to deal with and it was our goal to try and mitigate this issue in a efficient and accessible way.
How Evidentia Became Evidentia
When choosing the name for our project, we needed a name that reflected our core goals clearly but is also simple enough to be memorable. "Evidentia" comes from the Latin phrase "clarity through evidence". This is exactly what we are trying to accomplish in this project, presenting facts so clearly that the truth becomes impossible to ignore.
Problem
Policies are long, written in legal language, and hard to understand. Even when using an LLM, it is easy to get answers that are not verifiable or that depend heavily on how the prompt is written. Evidentia focuses on repeatability by requiring evidence for every claim and using a fixed rubric for scoring.
Flag based analysis
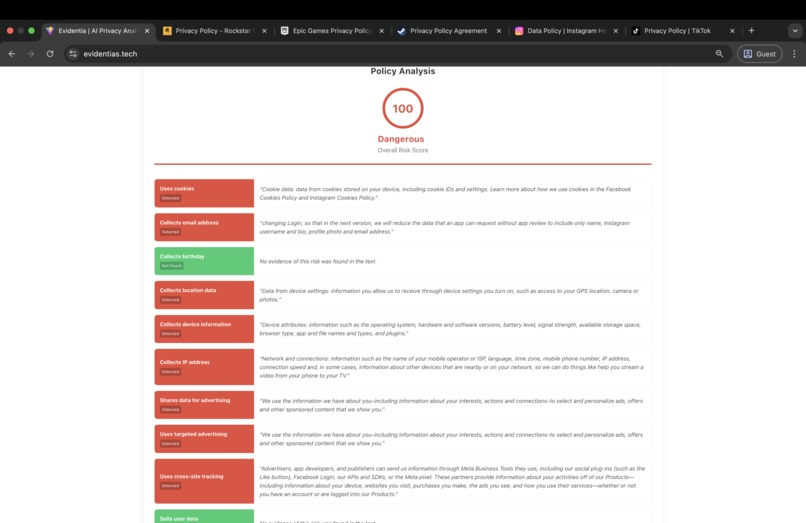
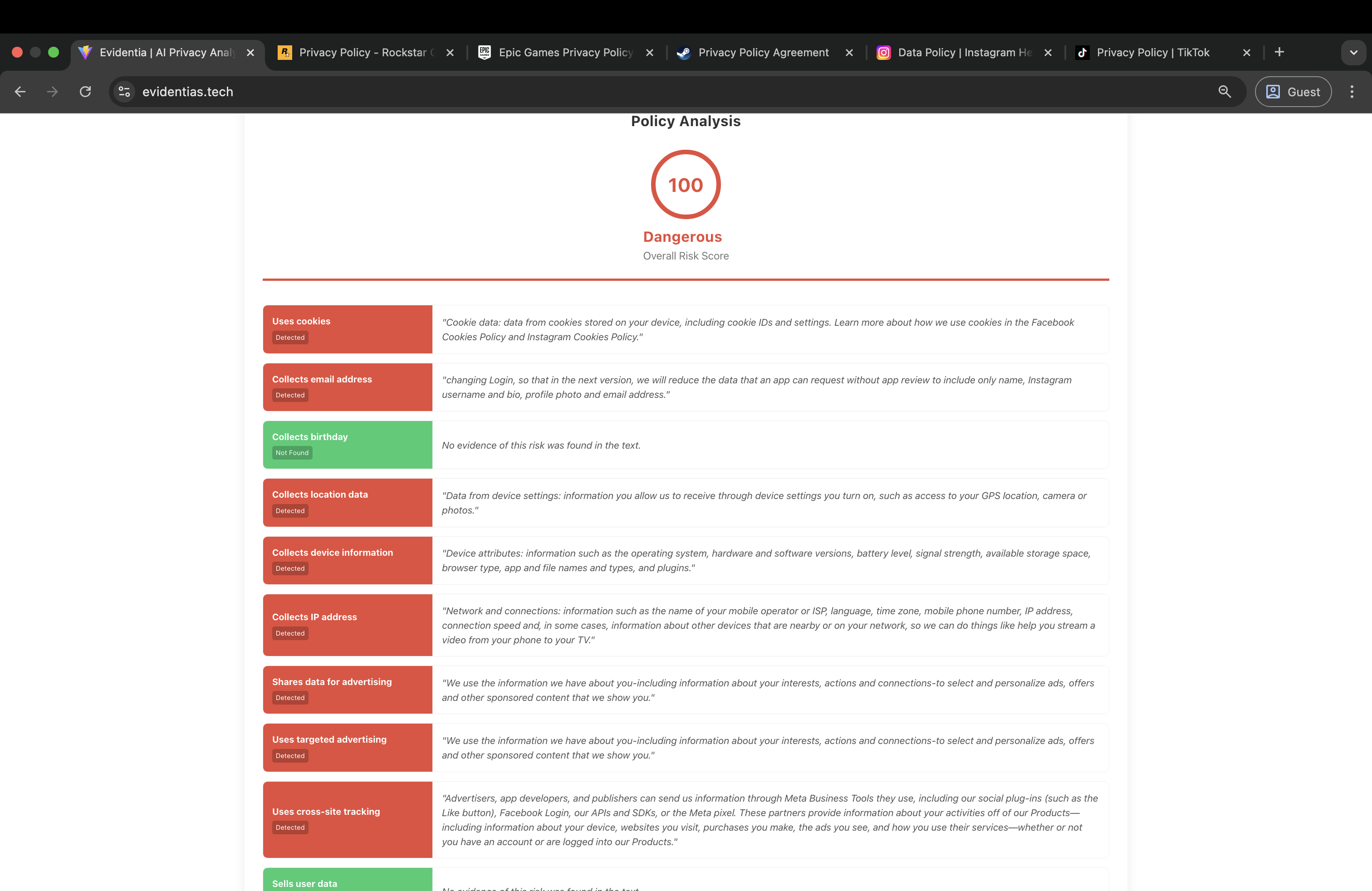
Evidentia evaluates a policy against a set of common risk flags grouped into categories such as tracking and advertising, data sharing and sale, sensitive data collection, retention and deletion, user rights and controls, and legal terms. Each flag is marked as true, false, or unknown. Unknown is used when the provided text does not contain enough information to make a reliable determination.
Evidence and confidence
For any flag marked true, Evidentia includes an exact quote from the policy as evidence. If the system cannot produce a supporting quote, it will not mark the flag as true. Each flag also includes a confidence score which is shown in the UI, especially helpful when results are unknown due to missing sections.
Scoring
Evidentia computes category scores and an overall risk score using weights assigned to the corrisponding flags. This makes results consistent across runs and reduces variation in answers of the same category. The score is intended as a quick comparative signal, while the quotes provide the evidence needed to back the reasoning.
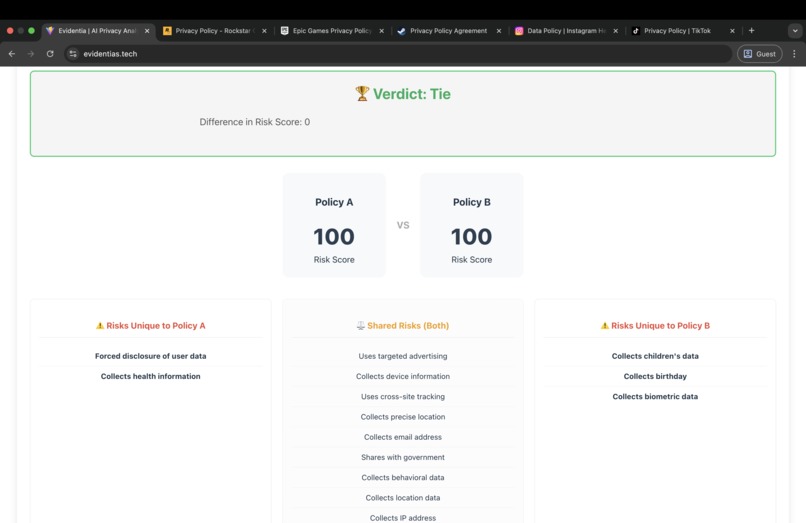
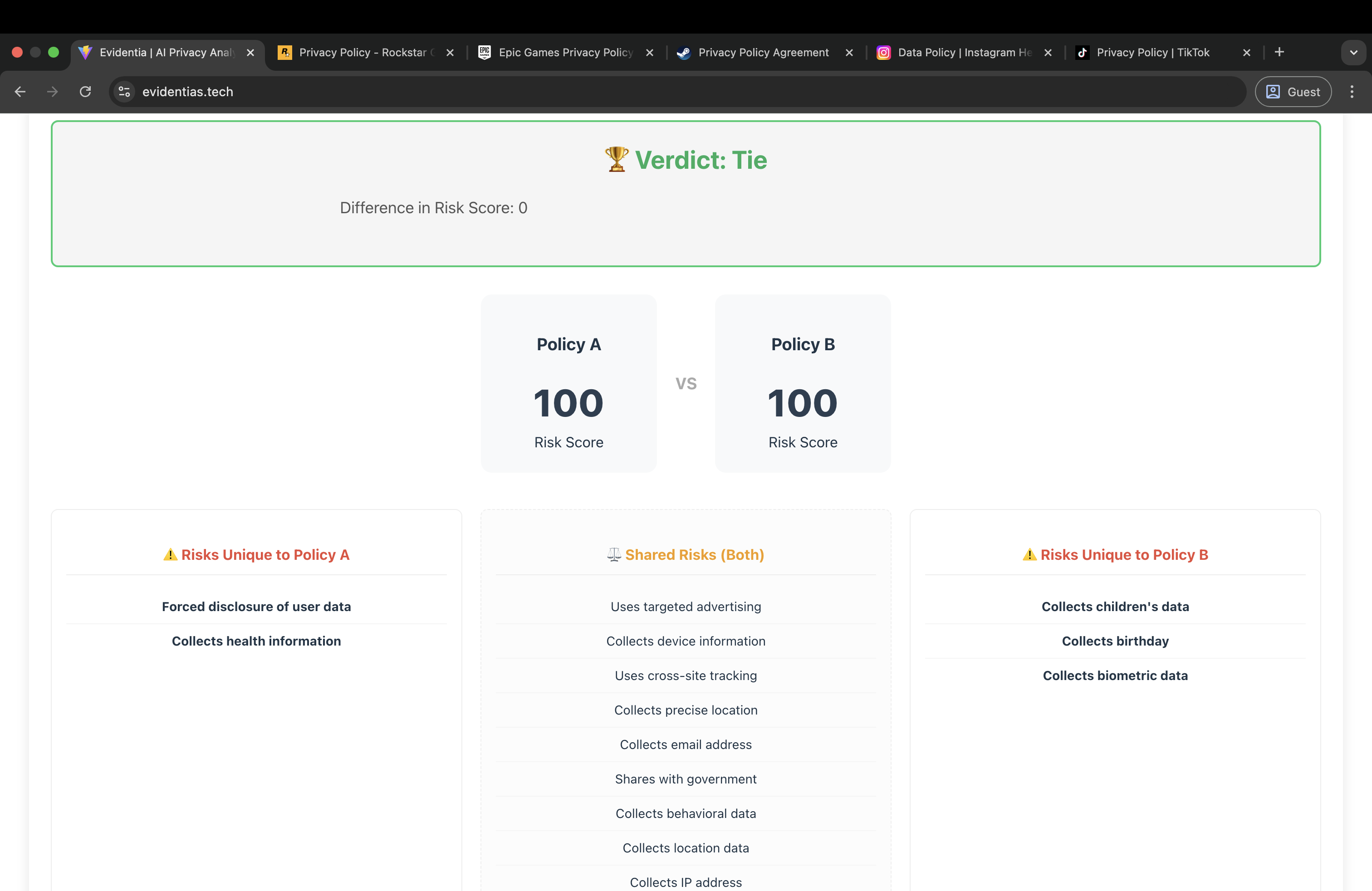
Compare mode
Compare Mode runs the same analysis on both policies and then gives a risk score based on the weights and flags. It highlights flags that were added or removed, flags that changed from known to unknown or vice versa, and category level score differences. This makes it easy to answer questions like which policy is riskier or what a new update changed.
Report
Evidentia generates a checklist report that includes the overall score, category breakdown, and the pass fail unknown status for each flag along with confidence indicators and supporting quotes where applicable.
Architecture overview
Evidentia uses a React frontend for the user interface and a FastAPI backend for analysis. The backend calls an LLM through Gemini API to perform structured extraction into a strict schema, then applies scoring and diff logic. The frontend renders the checklist, evidence, comparison view, and the risk score.
Challenges Faced
When developing our project, it was inveitable to run into issues and challenges that we had to overcome. One specific issue that slowed down our progress significantly would be the using Gemini API effectivly as beginners. For instance, Gemini kept throwing errors about rate limit exceeded which caused the backend to not break and halted the progression of the project.
Built With
- css
- fastapi
- gemini
- html
- javascript
- python
- react
- render
- typescript
- vercel




Log in or sign up for Devpost to join the conversation.