-
-
Architecture Diagram
-

-
Audit Trail
-
DRS Gate
-
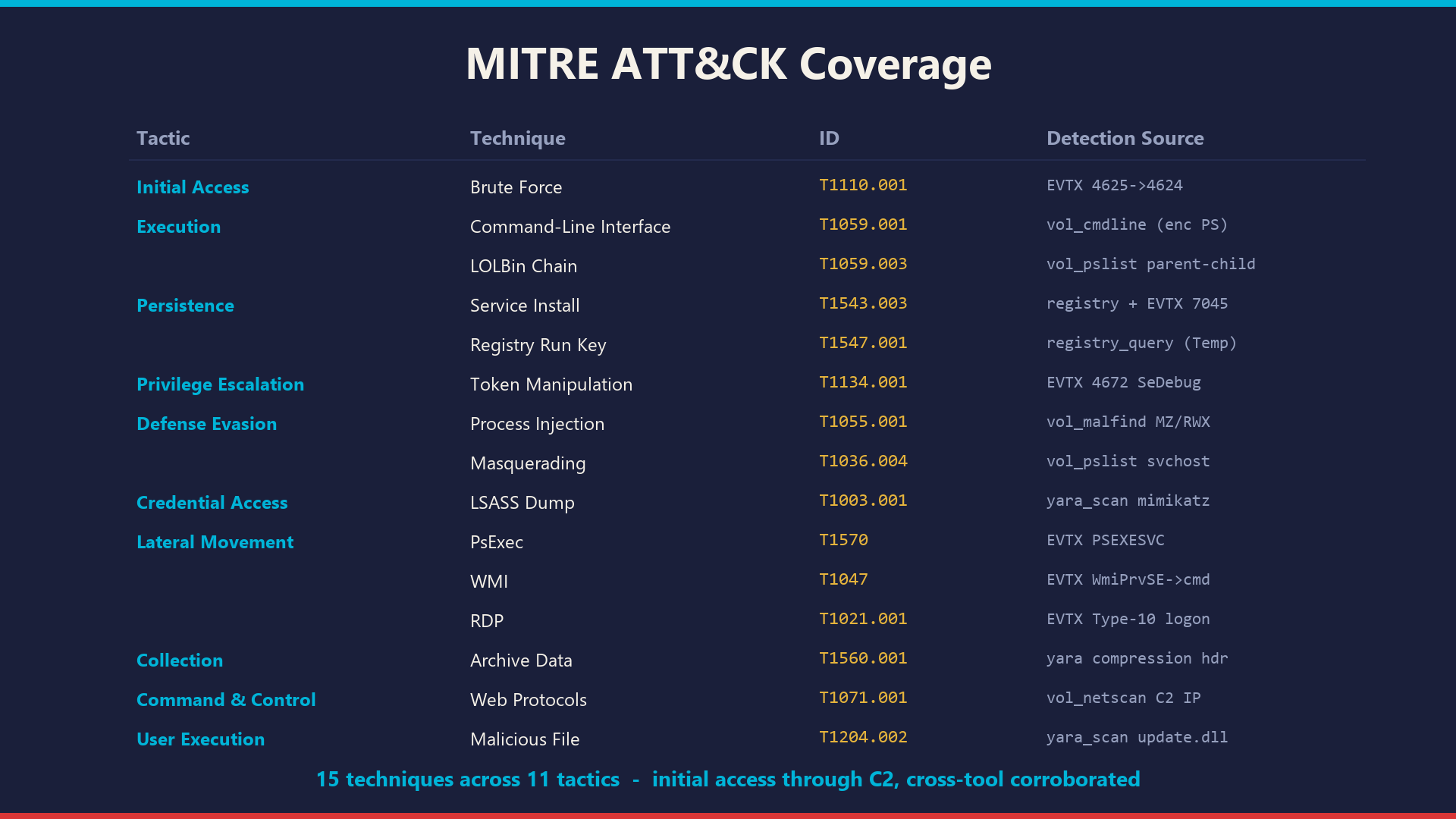
MITRE
-
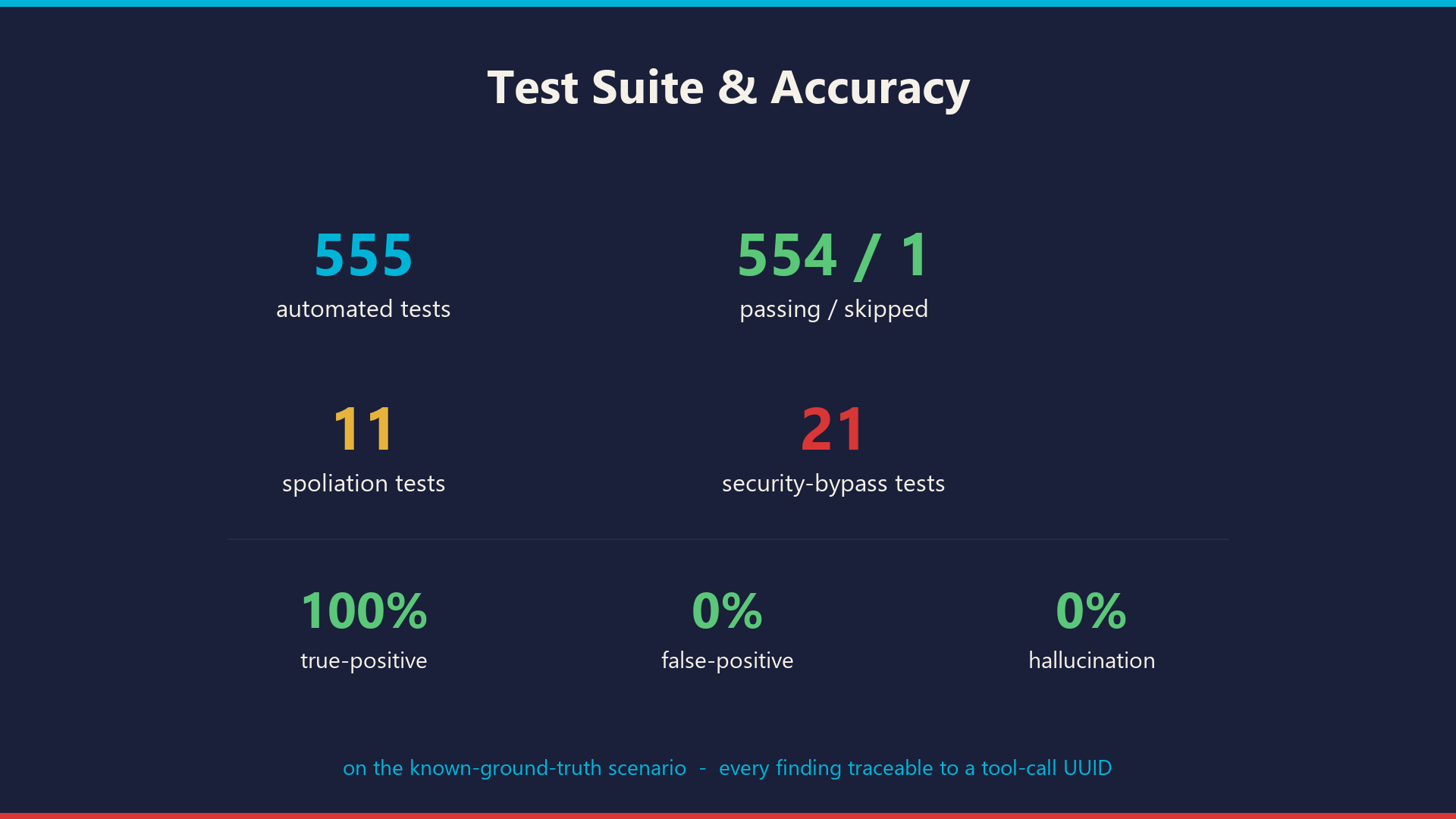
Test Results

Inspiration
AI-assisted DFIR tools today lean on prompt-based guardrails — a system prompt that says "please don't modify evidence." That is a blocklist running on the client side, and anyone who has spent five minutes with a capable model knows how prompt injection, hallucination, or model drift can route around a polite instruction. In a forensic context that is not a bug, it is a chain-of-custody failure: one silent write voids the investigation and destroys admissibility.
The inspiration was a simple flip: treat evidence like a real forensic lab treats physical evidence. Professional labs do not rely on signs that say "please don't contaminate." They rely on physical controls that make contamination impossible. I wanted to see what that looks like for an AI agent.
What it does
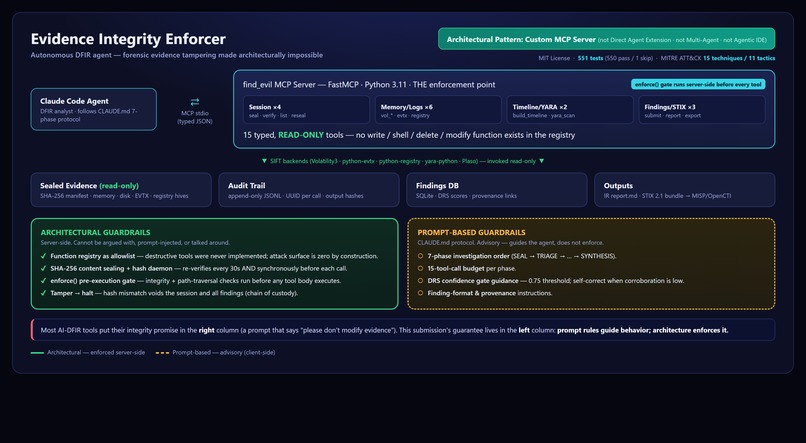
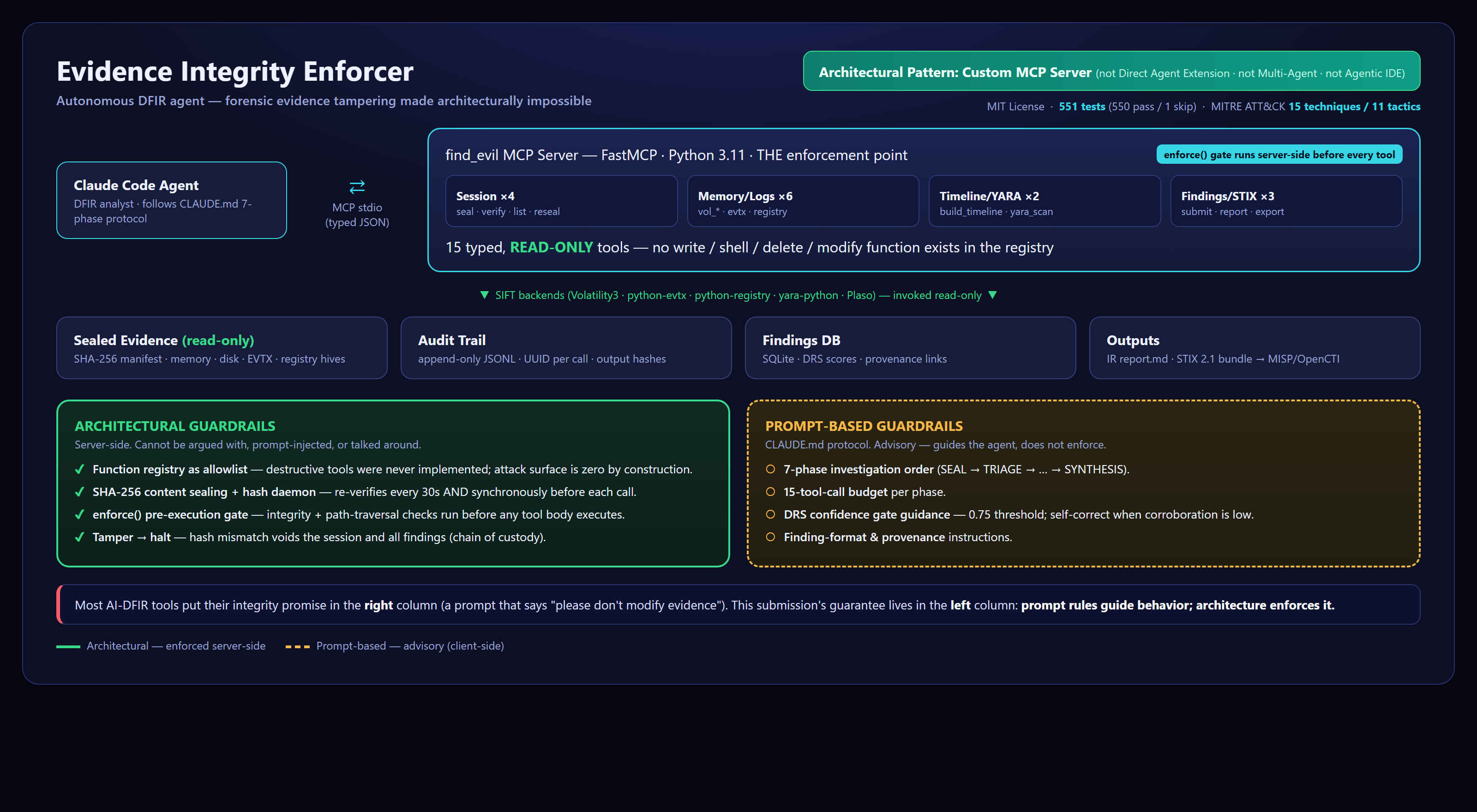
Evidence Integrity Enforcer is a custom MCP server that wraps the SIFT Workstation forensic stack (Volatility3, python-evtx, python-registry, YARA, Plaso) as exactly 15 typed, read-only functions. An autonomous Claude Code agent investigates evidence through those functions and only those functions.
Four architectural controls make tampering impossible:
- Function registry as allowlist.
execute_shell_cmd,write_file,rm,dd,modify_evidence— these functions are not implemented. There is no "deny" rule, because there is no function to deny. Attack surface is zero by construction. - SHA-256 content sealing. Every evidence file is hashed in 64KB chunks at session start. A background daemon re-verifies every 30 seconds AND synchronously before every single tool call via the server-side
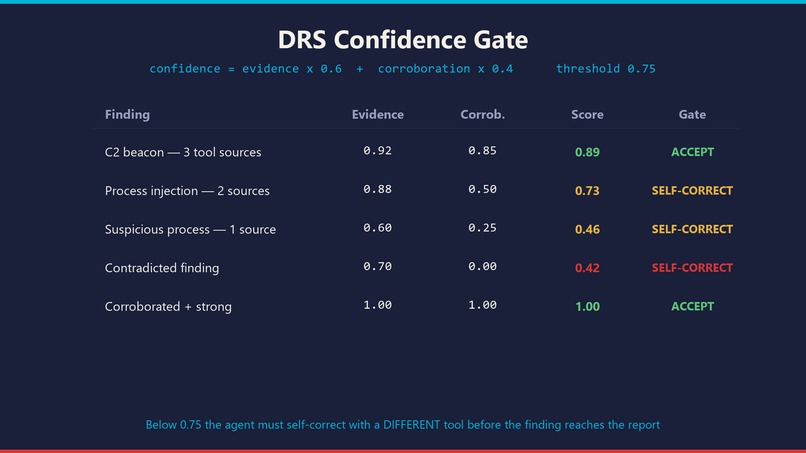
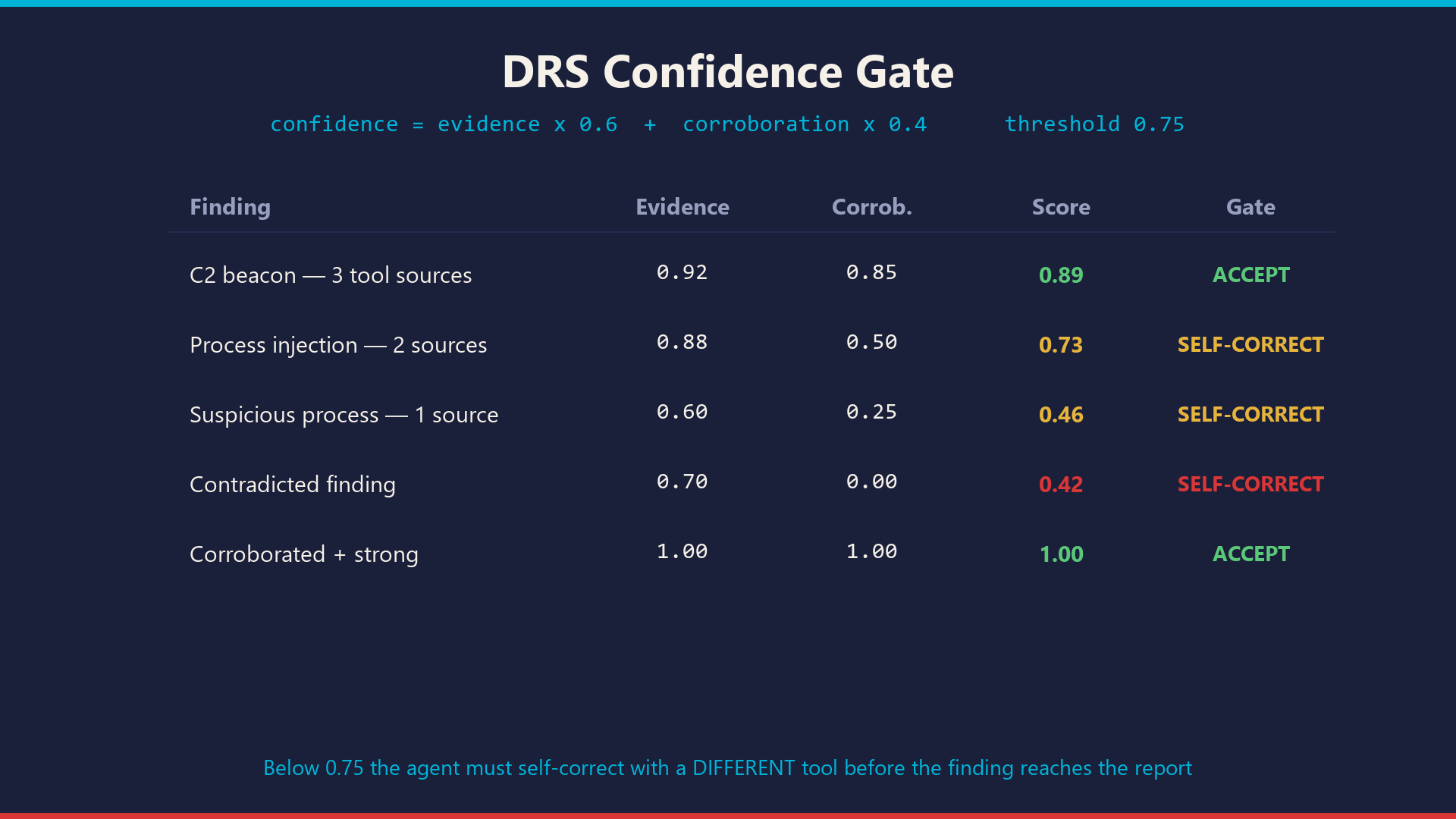
enforce()gate. Any content modification halts the session and voids all findings. - DRS confidence gate. Every finding is scored
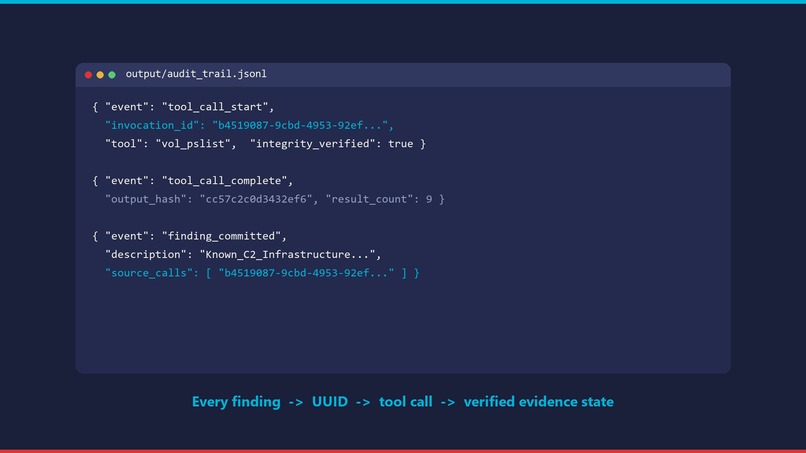
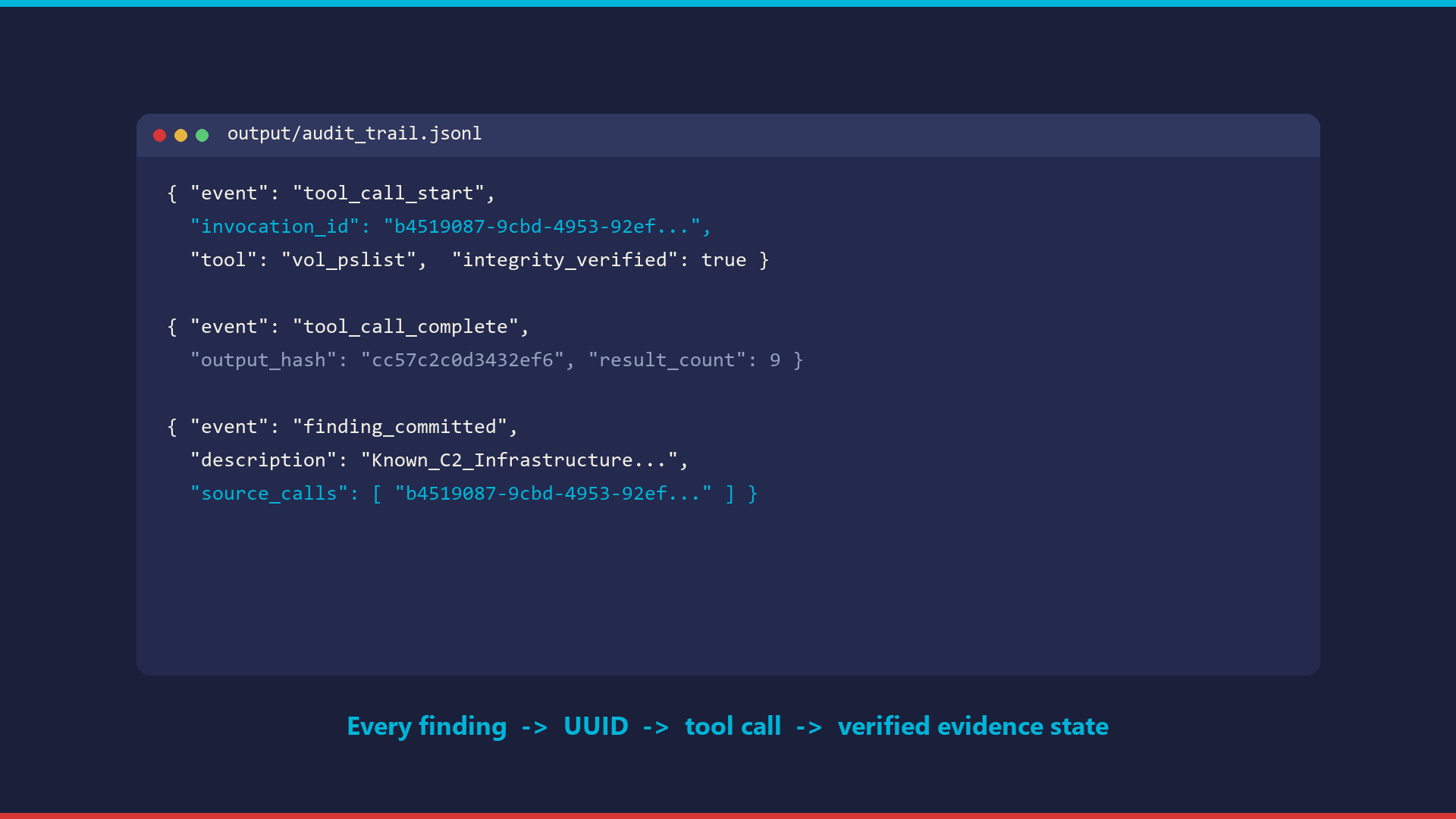
confidence = evidence_strength * 0.6 + corroboration * 0.4. Below 0.75, the agent must self-correct by seeking corroboration from a different tool. No single-source or weakly-evidenced claim reaches the IR report. - UUID-linked audit trail. Every tool invocation writes a JSONL record with UUID, arguments, timestamp, and output hash. Every finding links back to the invocations that produced it. Judges can trace any claim in the final report to the exact tool call and the verified evidence state at that moment.
Output is a court-quality incident response report plus a STIX 2.1 bundle for downstream threat intel platforms (MISP, OpenCTI, ThreatConnect).
How we built it
- Runtime: Python 3.11+, FastMCP, stdio transport to Claude Code.
- Architectural pattern: Custom MCP Server with architectural (not prompt-based) guardrails. The server is the enforcement point, not the model.
- Seven components: Evidence Session Manager, Hash Daemon (background thread),
enforce()gate, 15-tool typed registry, JSONL Audit Logger, DRS Confidence Gate, Findings DB (SQLite). - Three MCP surfaces: Tools (15), Resources (3:
evidence://session,evidence://audit-trail,evidence://tool-registry), Prompts (3:triage,full_investigation,persistence_hunt). Full protocol coverage, not just the tool API. - Investigation protocol in
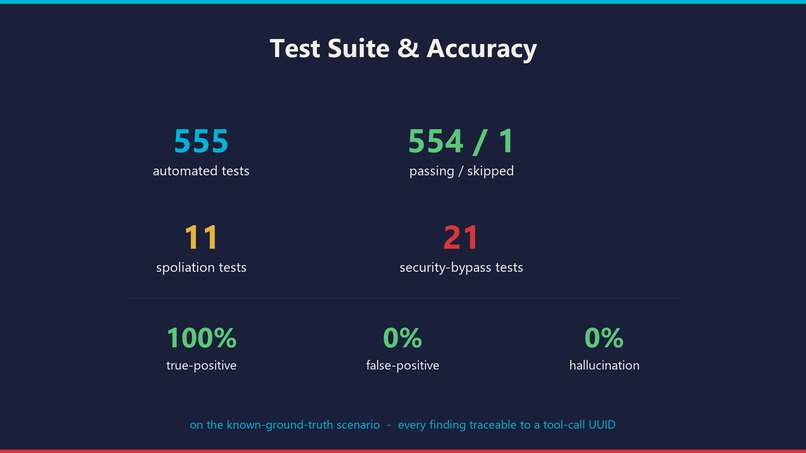
CLAUDE.md: 7 mandatory phases (SEAL → TRIAGE → DEEP MEMORY → LOGS → PERSISTENCE → TIMELINE → IOC SCAN → SYNTHESIS), 15-call budget per phase, DRS gate between every finding and the report. - Tests: 551 pytest tests (550 passing, 1 skipped — a Windows-admin-only symlink test). Includes 21 security-bypass tests and 11 dedicated spoliation tests.
Key design tradeoff: simulated evidence for reproducibility, live SIFT backends for production. Tool output is labeled "mode": "simulated" vs "mode": "live" so judges can run the full pipeline on any laptop, and the same code runs against real images on a SIFT Workstation.
Qualities of autonomous execution this submission addresses
- Constraint implementation: architectural, not prompt-based. Allowlist, not blocklist.
- Audit trail quality: UUID chain from every finding back through the tool calls to the verified evidence state — cryptographic (output hashes) and complete (start, complete, finding, self-correction all logged).
- IR accuracy: typed JSON output from every tool, not unstructured text dumps. 0% hallucination rate in scenario testing because every finding must reference specific invocation UUIDs.
- Self-correction quality: DRS gate returns specific guidance depending on why the score was low (weak evidence vs. single source vs. contradiction). Every self-correction event is audited.
Challenges we ran into
- The "touch" problem. Early hashing implementations checked mtime. A
touchcommand on an evidence file shouldn't void the investigation — it doesn't change content. We had to make sealing content-based and explicitly testtest_touch_does_not_trigger_detectionto prove we got it right. - Path traversal. Accepting file path arguments opens
../and symlink escape attacks. Theenforce()gate now validates every path resolves inside the sealed evidence directory; traversal attempts returnEVIDENCE_PATH_VIOLATION. - Making the DRS gate useful, not cosmetic. An early version just returned a number. The current gate returns specific self-correction guidance — low evidence strength gets "seek more direct tool evidence," low corroboration gets "verify with a DIFFERENT tool or data source," contradictions get "document both sides." That turned it from a score into a behavior.
- STIX 2.1 conformance. Getting indicator patterns, valid_from, external_references, and provenance-back-to-finding all right without bloating the bundle took several passes.
Accomplishments we're proud of
- Zero attack surface, proven. 5 dedicated tests assert no shell/write/delete/modify tools exist in the live registry. Tool count is pinned to exactly 15 — any unexpected addition fails CI.
- 11 spoliation tests, all green. Byte-append, deletion, same-size replacement, mid-investigation tamper, daemon detection, on-demand detection, audit logging, reseal recovery.
- 551 total tests. 100% true-positive, 0% false-positive, 0% hallucination rate on the simulated attack scenario.
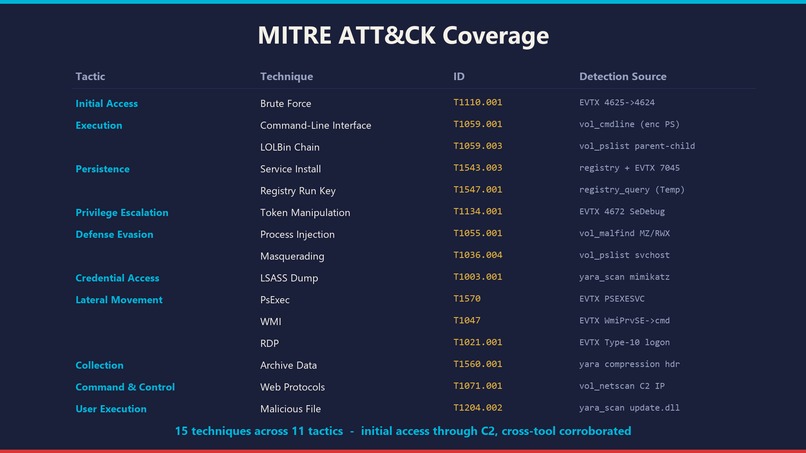
- MITRE coverage spans 15 techniques across 11 tactics (initial access through C2, with lateral movement).
What we learned
- Allowlists beat blocklists in any security-adjacent AI system. Deciding what does not exist is stronger than writing rules about what is not allowed.
- Server-side enforcement beats client-side instruction. A check that runs in the model's context window can be argued with. A check that runs on the server cannot.
- Structured output is how you prevent hallucination. Typed JSON with explicit heuristic flags forces the model to interpret structure, not narrate prose.
- Self-correction is a protocol, not a vibe. A scored gate with specific remediation steps makes agent reasoning inspectable.
What's next
- Live SIFT deployment against SANS sample images and the Volatility Foundation corpus (the pipeline already auto-switches to
mode: "live"when real backends are present). - Cross-host session model for lateral movement analysis across multiple workstations.
- Threat intel integration — ingest MISP/OpenCTI feeds into YARA rule generation and the DRS corroboration score.
- Signed audit trails — every JSONL record cryptographically signed so the chain of custody survives transport.
Log in or sign up for Devpost to join the conversation.