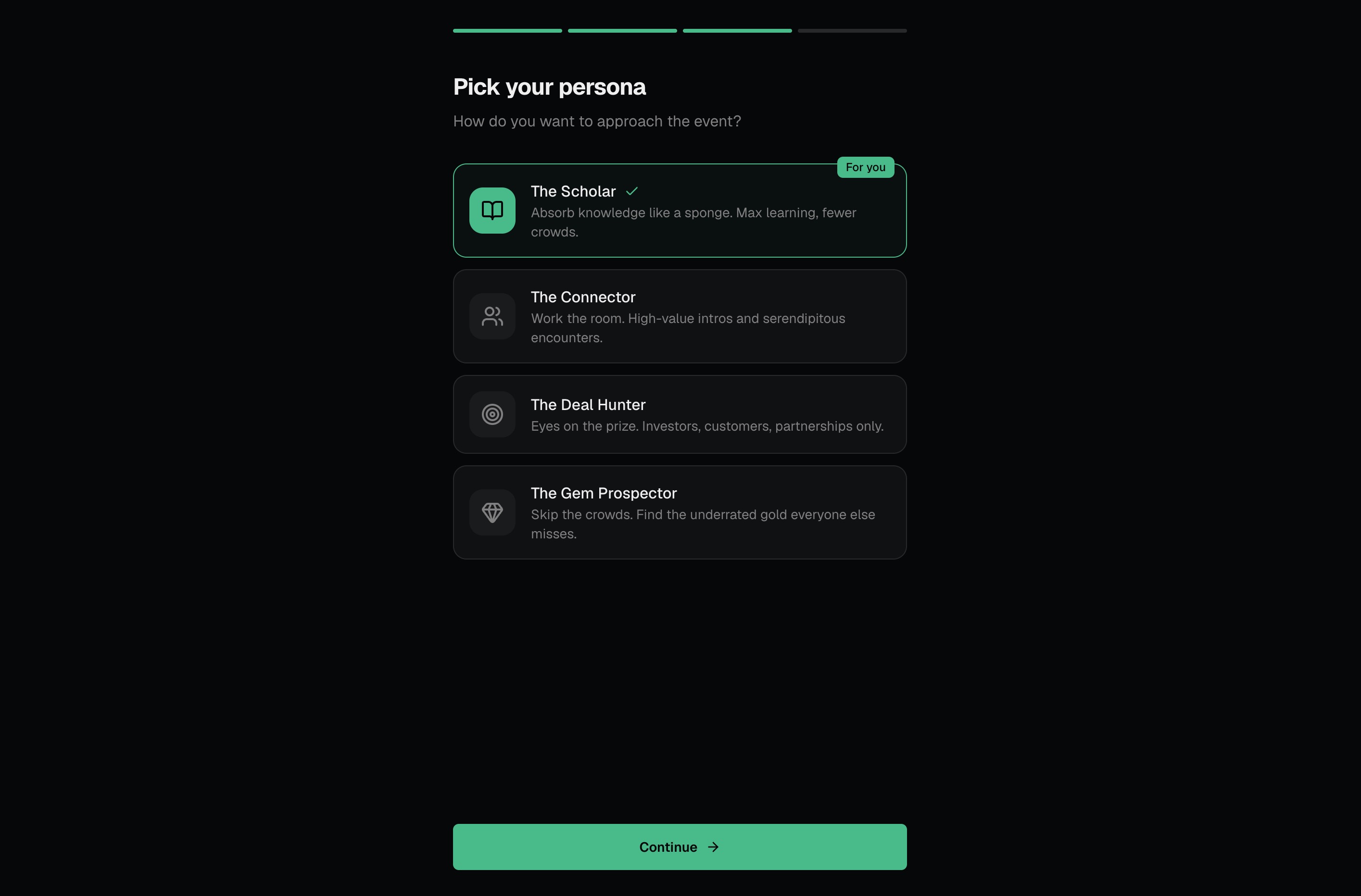
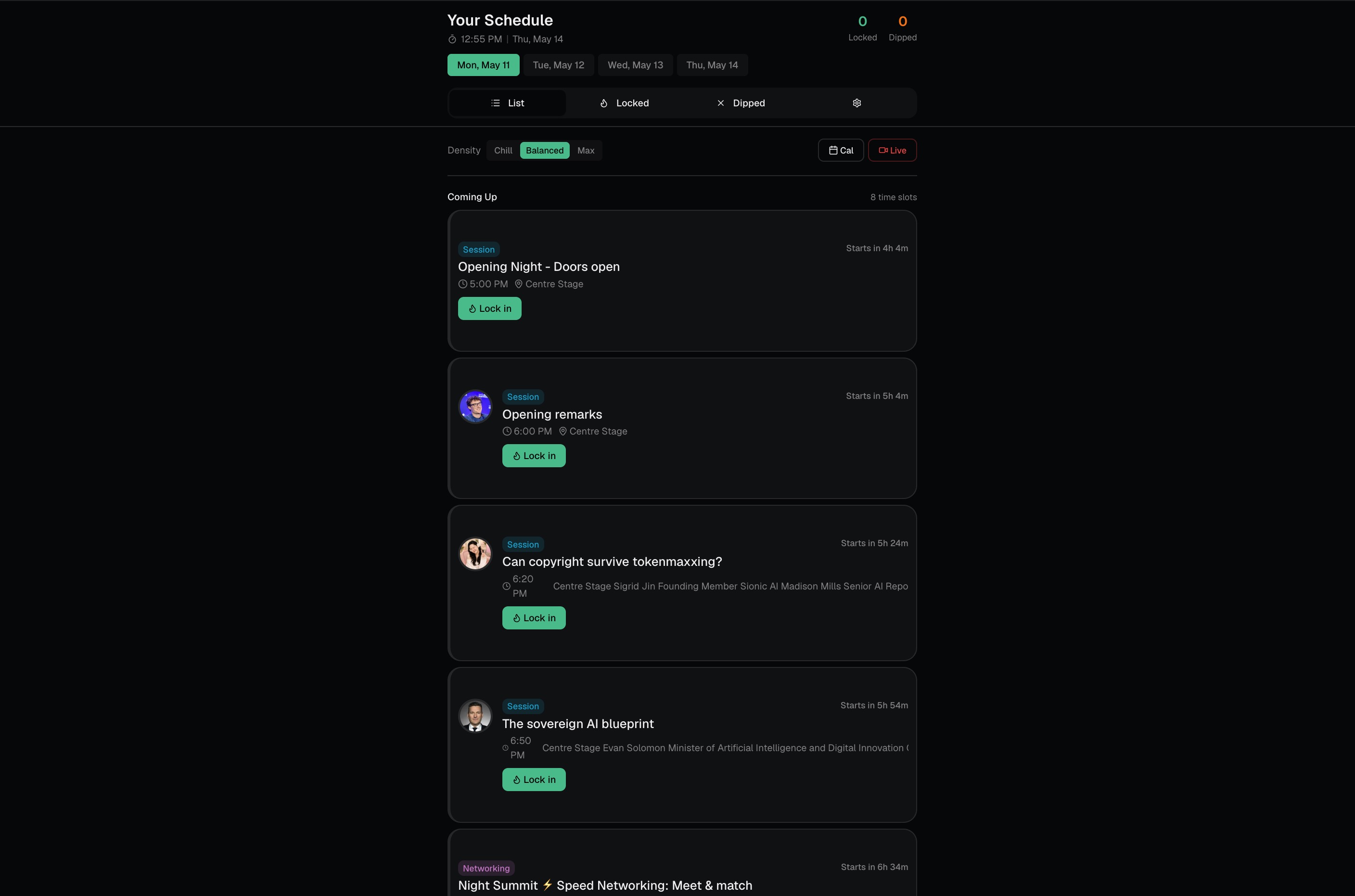
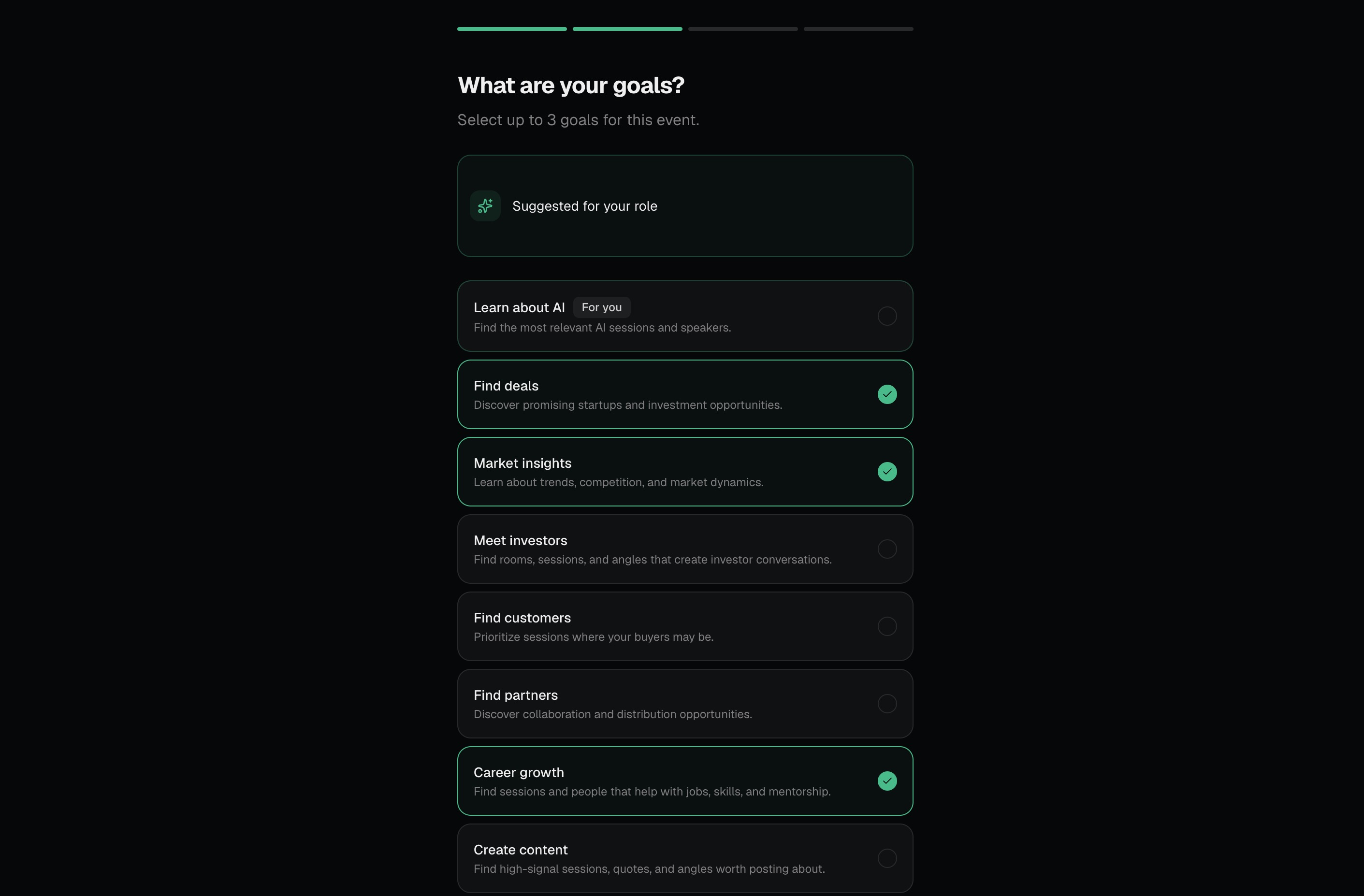
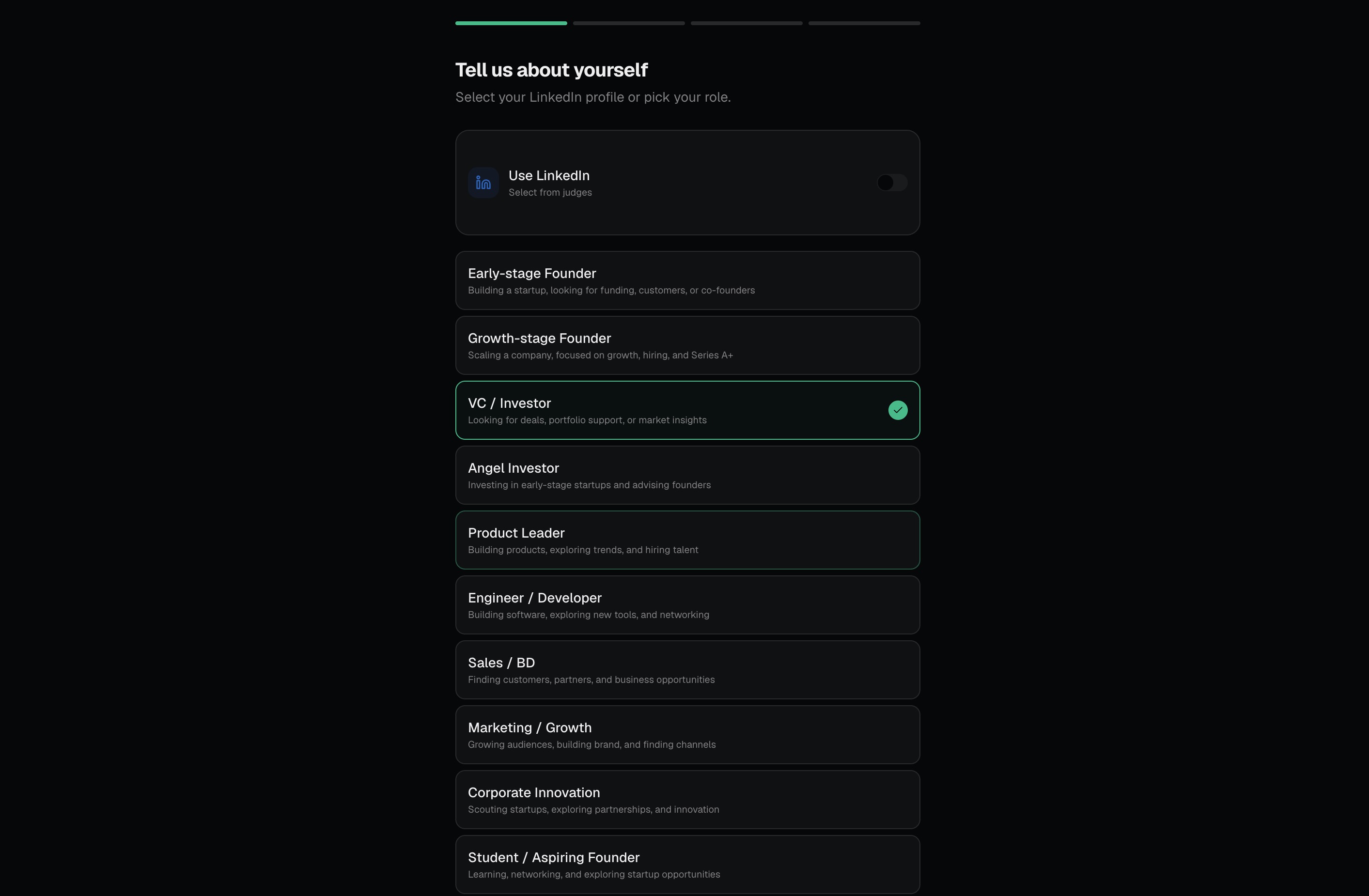
Event Pilot Inspiration We've all been to a big conference and felt it: that low-grade panic of standing in a hallway, phone open to a schedule with 40 overlapping sessions, knowing the real value is happening somewhere you're not. Web Summit has over a thousand sessions, hundreds of booths, and tens of thousands of people. The official app shows you everything. That's the problem. The insight that kicked this off was simple: big events don't have an information problem, they have a decision problem. Attendees aren't short on options, they're short on judgment about which option is right for them. A founder building AI sales tools and a student looking for a first job are staring at the same schedule and need completely different things from it. We wanted to build the friend you wish you had at every conference, the one who knows your background, knows what you're trying to get out of the week, and just tells you where to go next. What it does Event Pilot turns a generic event schedule into a personal strategy. You paste in your bio (or LinkedIn summary), pick a few goals, choose how packed you want your day to be, and it builds you a ranked, conflict-resolved schedule with:
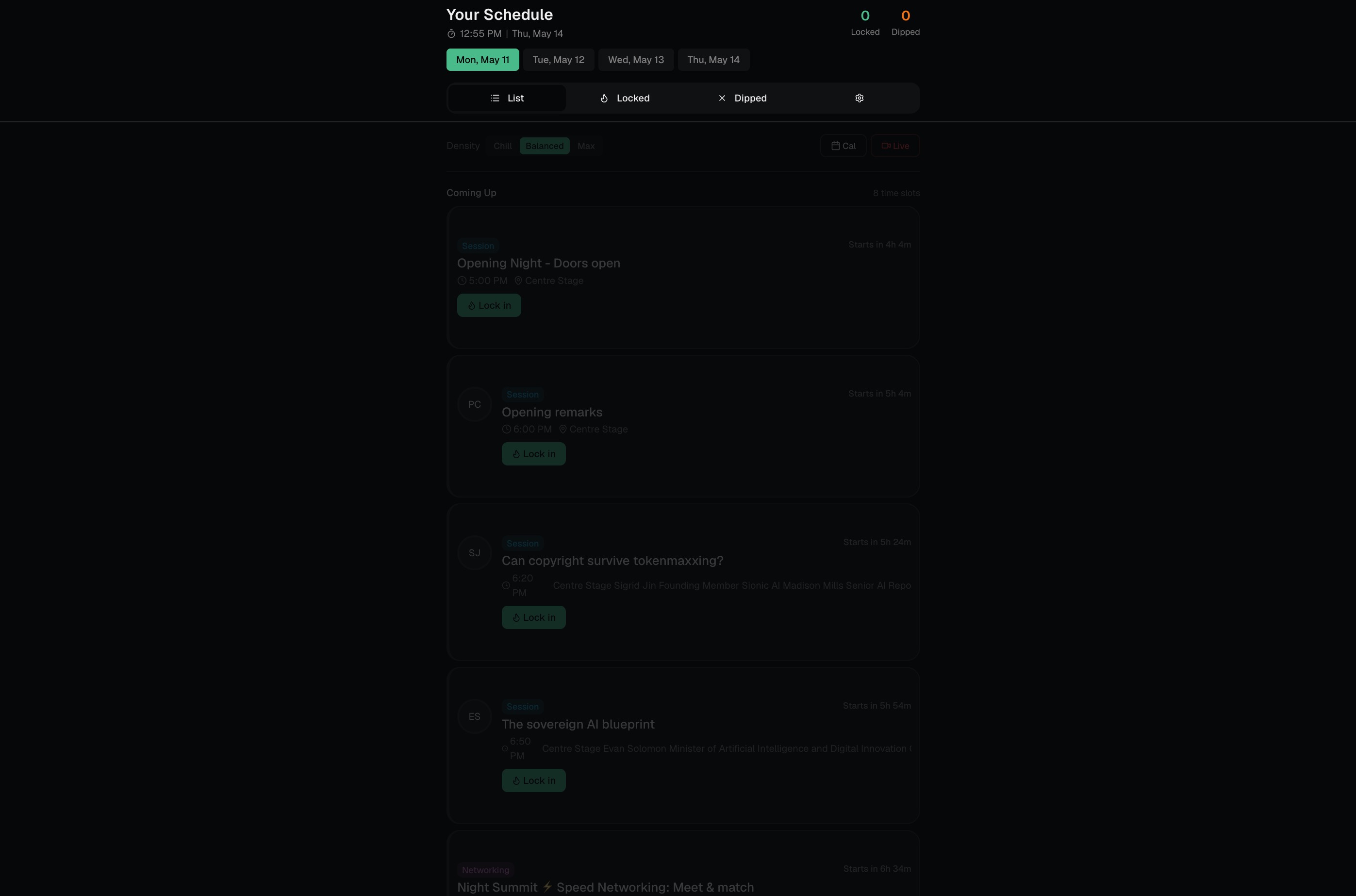
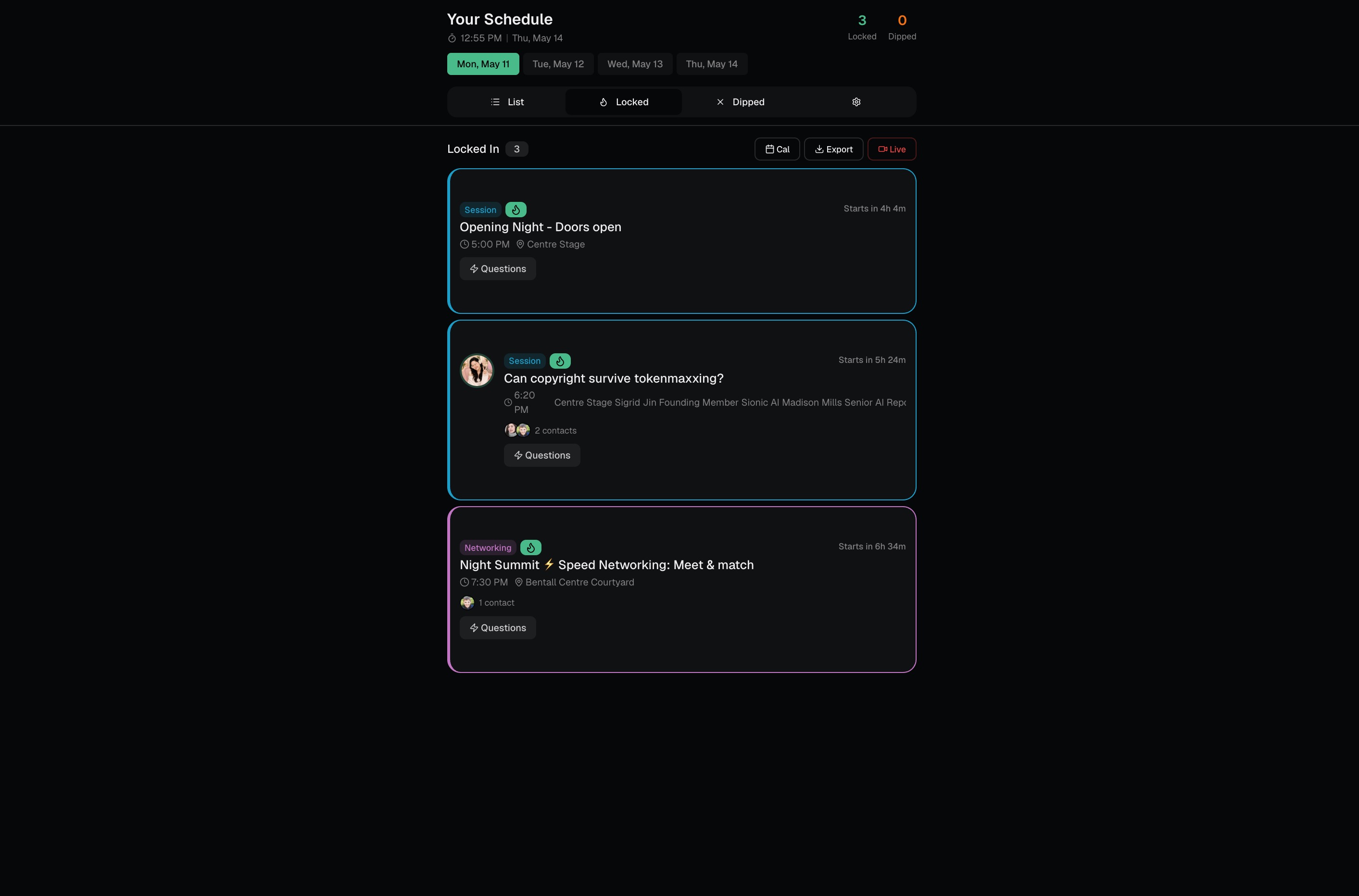
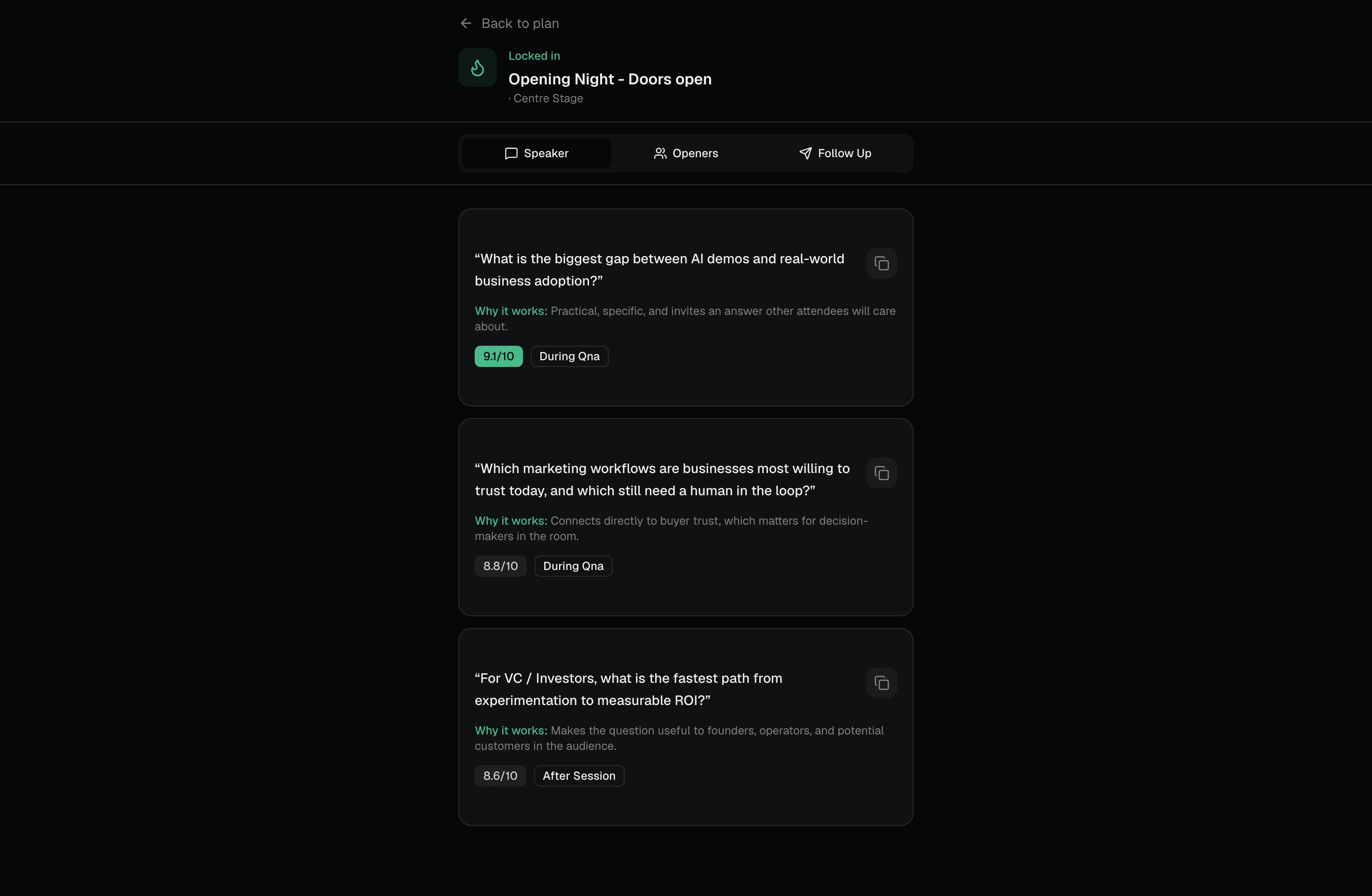
A personalized game plan, which sessions to attend, which to skip, and the hidden gems most people will miss Smart conflict resolution, when two great sessions overlap, it auto-picks the clear winner, but when it's a close call between two strong matches, it kicks the decision back to you with a crisp tradeoff explanation A Question Compass for every session, three speaker questions tailored to your background, three conversation openers for the networking area, and a LinkedIn follow-up template Live swap suggestions, every scheduled session ships with backup options ranked by match score, so if a room is full or a talk isn't landing, you know exactly where to go next A "Next Best Move" button, one tap, and it tells you what to do in the next 15 minutes based on the time, your goals, and what's happening around you Intensity and load controls, a busy founder running on three hours of sleep gets a different schedule than someone there to soak everything in, even with the same profile
How we built it We optimized for speed and signal. The stack:
Next.js + Tailwind + shadcn/ui for the frontend, mobile-first, dark theme, big cards, one decision per screen OpenAI powering the scoring, scheduling, and question generation, with carefully structured prompts that return strict JSON we can render directly A static JSON dataset of Web Summit-style sessions for the demo, with tags, expected audiences, crowd levels, and vibe scores Local state for the user profile and persisted rankings, every event gets scored once and stays scored, so swapping out of a session never requires another LLM call Vercel for deployment
The core architectural decision was treating the LLM as a scoring and ranking engine, not a chatbot. One big prompt builds the entire schedule, scores every event in the pool, pre-computes swap candidates for each slot, and flags genuine ties for the user to resolve. Everything downstream, swaps, next-best-move, the question compass, reads from that persisted ranking instead of asking the model again. That kept latency low and behavior consistent. The scoring formula is intentionally explainable: profile match (30%), goal match (25%), interest match (20%), networking potential (15%), and timing fit (10%). When the app tells you why a session is recommended, the reason traces back to actual weights, not vibes. Challenges we ran into Conflict resolution was harder than it looked. Our first instinct was to just pick the highest-scoring event when two overlapped. But that quietly betrays the user when two sessions are nearly tied the model is essentially flipping a coin and pretending to be confident. We landed on a 15-point gap rule: clear winners get auto-selected, close calls get surfaced to the user with a real tradeoff explanation. Getting that threshold right took a lot of test runs. Making recommendations feel personal, not algorithmic. Early versions returned reasons like "this matches your interests in AI and SaaS." Technically correct, totally forgettable. We rewrote the prompt to force specificity the reason has to reference something concrete from the user's bio, not just echo their tag selection back at them. Keeping the JSON contract stable. When you're rendering schedule cards, swap candidates, decision prompts, and the ranked pool all from one LLM response, any drift in the output shape breaks the UI. We spent real time on the system prompt's "hard rules" section and added validation on the parse step. Resisting feature creep. The PRD listed LinkedIn OAuth, calendar sync, real-time maps, voice notes, CRM, attendee matching all good ideas, all out of scope for a three-hour build. The discipline of saying "future feature" instead of "let's just add it" was its own challenge. Accomplishments that we're proud of
The full magical loop works end to end. Paste a bio, pick goals, get a real schedule with real reasoning, drill into any session, get questions tailored to your background. No mocked steps. The conflict-resolution kickout actually fires when sessions tie, and the tradeoff explanations are good enough that picking feels easier, not harder. The ranked pool persists, so swapping sessions is instant no waiting on the model, no flicker. The UI feels like a personal strategist, not event software. Big cards, one decision per screen, confidence scores you can actually act on. We resisted every temptation to add a feature that wouldn't ship cleanly, and the demo is tighter for it.
What we learned The biggest lesson: LLMs are better as ranking engines than as conversation partners for this kind of problem. Once we stopped treating the model as something to chat with and started treating it as a scoring function with structured output, everything got faster, cheaper, and more trustworthy. We also learned how much the framing of a recommendation matters. "Skip this session" lands completely differently than "this is lower priority for your goals." Same information, different relationship with the user. Every piece of microcopy got rewritten at least twice. And on the team side: writing a tight PRD before opening an editor saved us hours. Knowing exactly what was in scope and what was deferred meant zero arguments mid-build about whether something was worth adding. What's next for Event Pilot The MVP proves the core loop. The roadmap is about making it real:
Real LinkedIn integration so users can onboard in one tap instead of pasting a bio Live event sync with the actual Web Summit (and eventually SXSW, TechCrunch Disrupt, Slush) APIs instead of a static dataset Calendar export so the plan lands in Google Calendar with reminders and walking directions Attendee matching the same scoring engine, but applied to other attendees who opted in, so you can find the five people in the building most worth meeting Crowd and vibe data from the venue itself, turning the "vibe_score" from a heuristic into something live A post-event recap that turns your messy notes and business cards into ranked follow-ups with draft messages Multi-day strategy that thinks across the whole conference, not just the next session Voice mode for when you're walking between stages and don't want to type
The long-term vision is bigger than conferences. The same engine profile + goals + schedule + ranking + question generation works for trade shows, university orientation weeks, music festivals, even busy travel itineraries. Anywhere there's too much happening and not enough judgment about what matters to you, Event Pilot has a job to do.
Built With
- nextjs
- react
- typescript

Log in or sign up for Devpost to join the conversation.