-
-
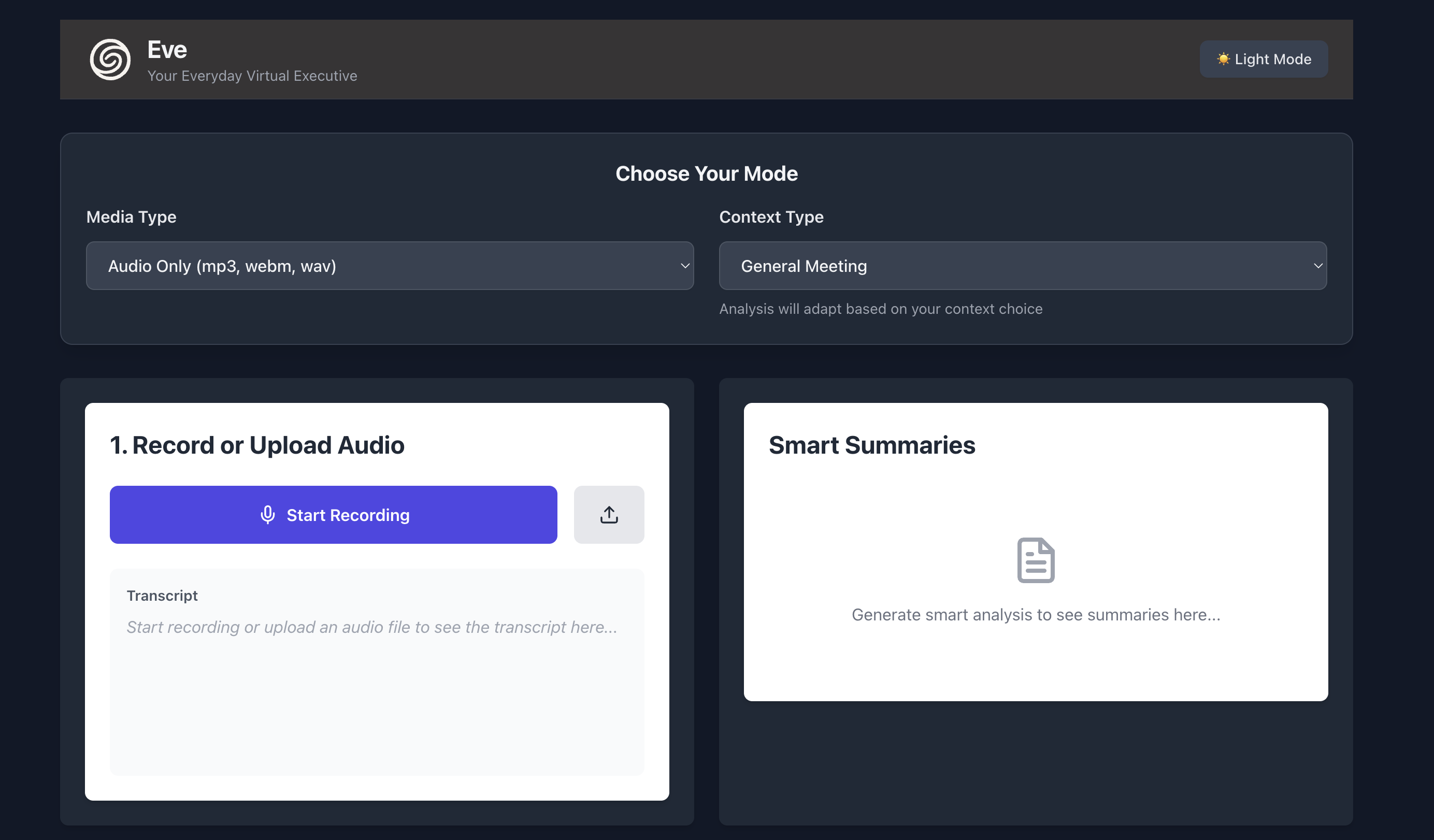
EVE Dashboard - Light Mode!
-
EVE Dashboard - Dark Mode!
-
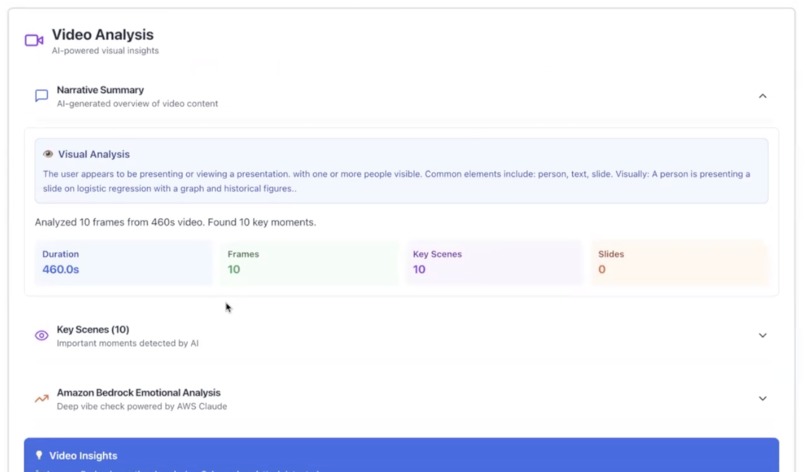
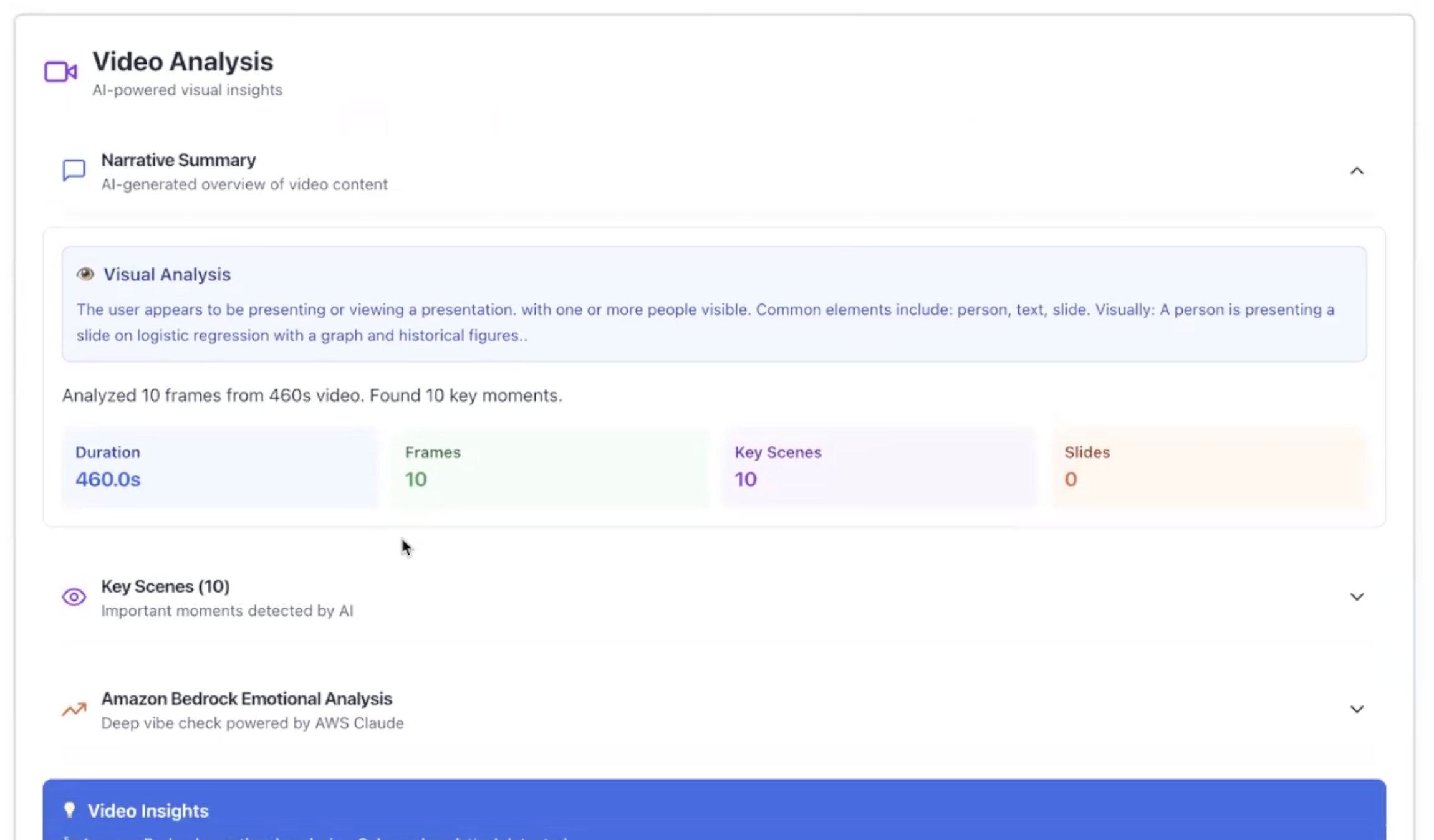
Video analytics!
-
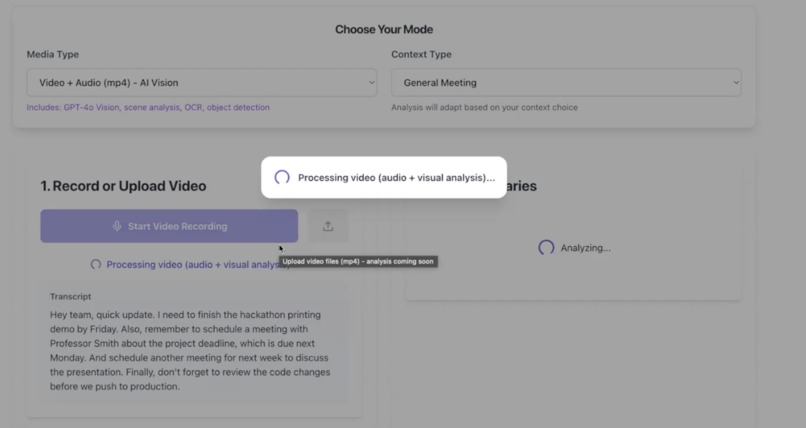
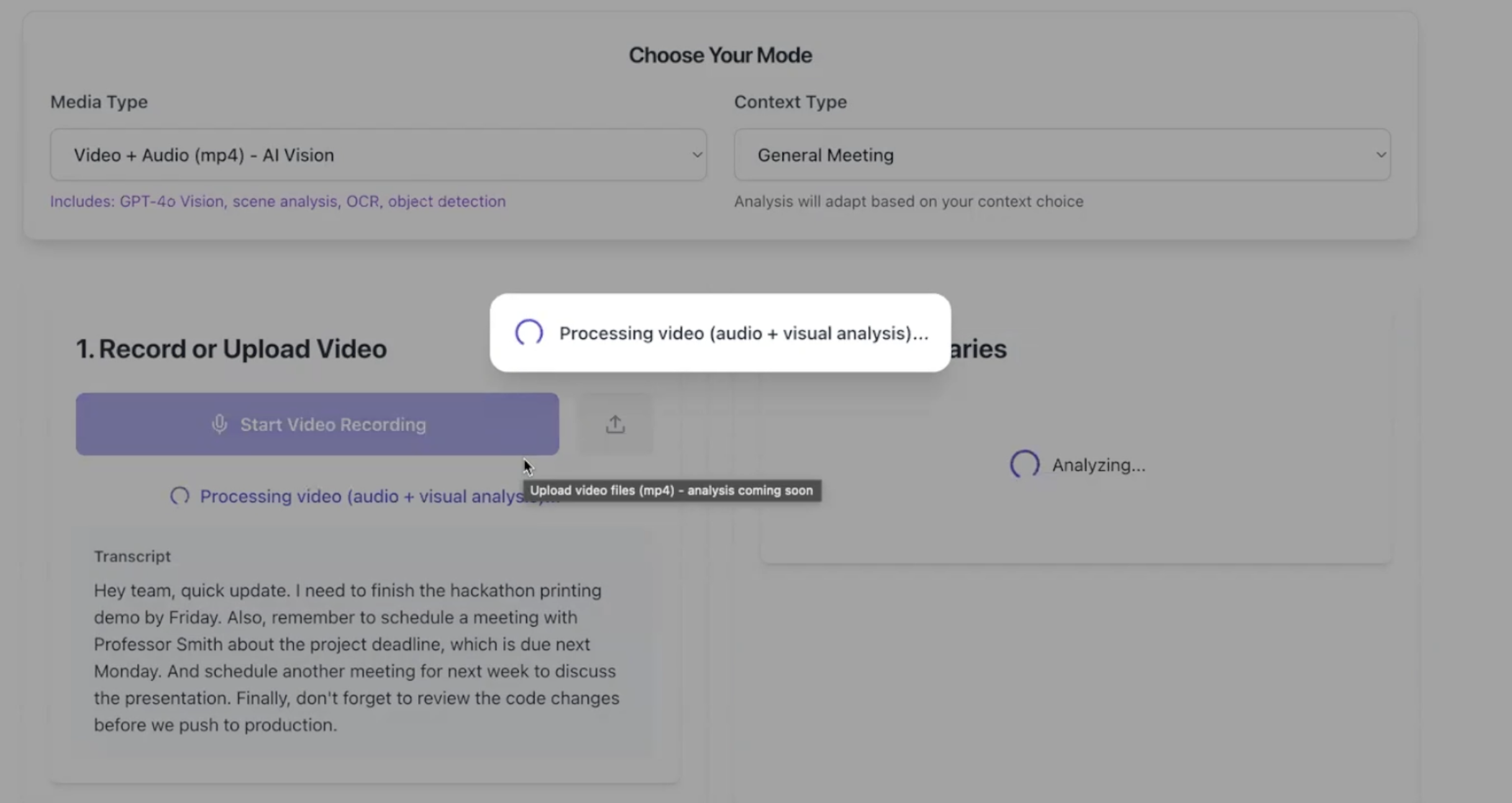
Processing an audio recording
-
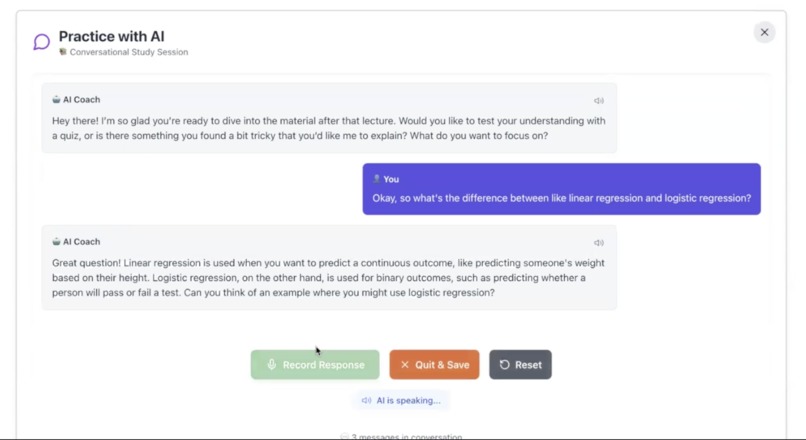
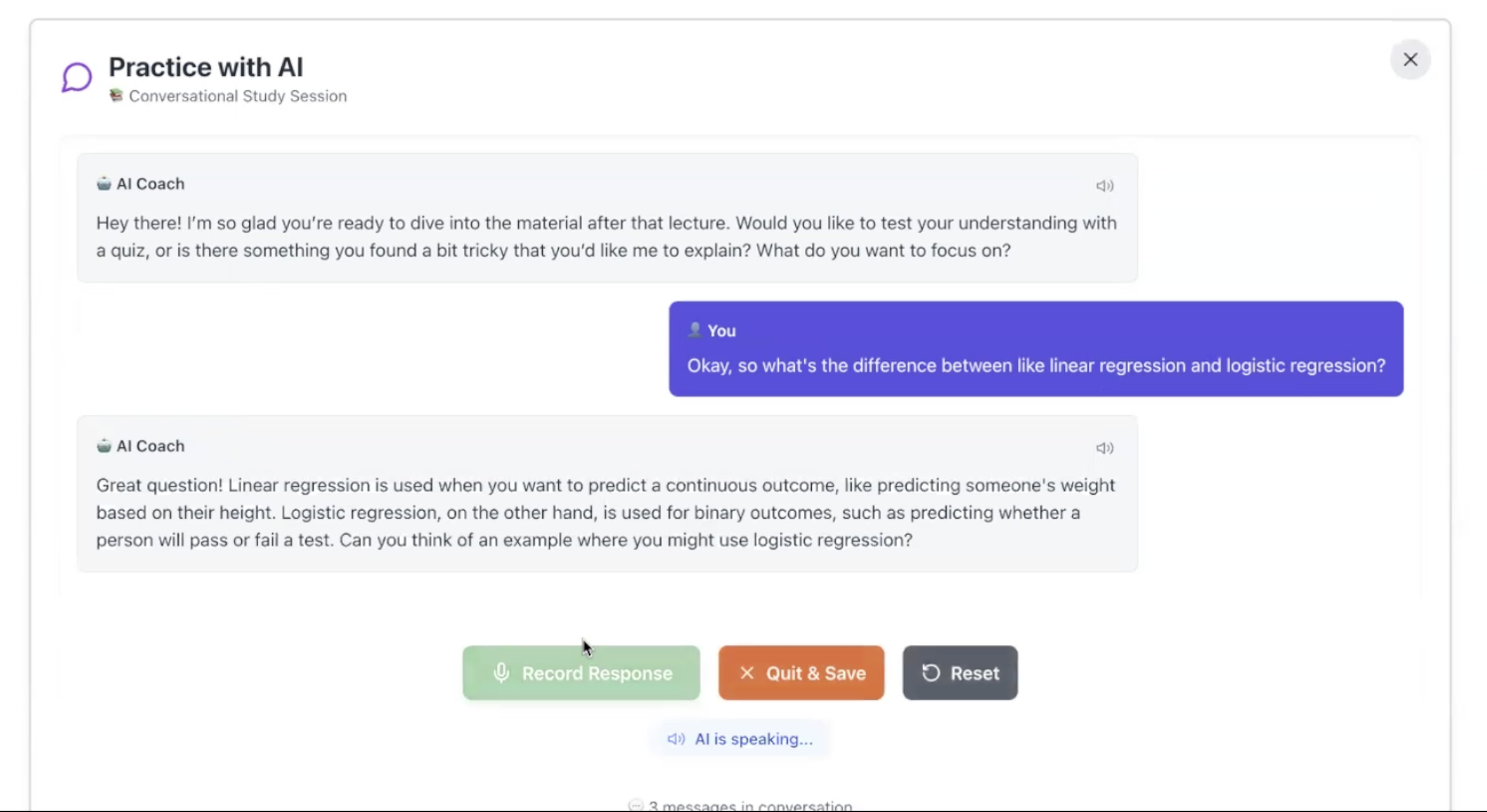
Chat with AI (ElevenLabs)!
-
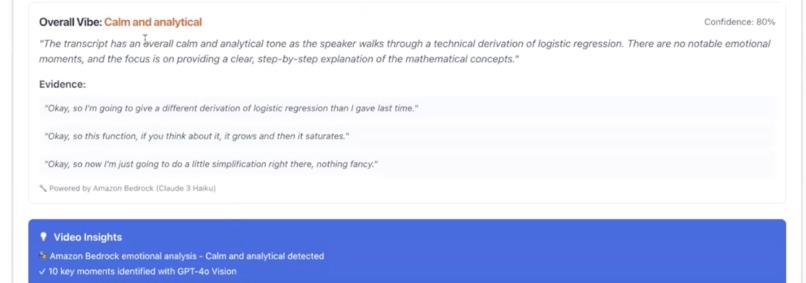
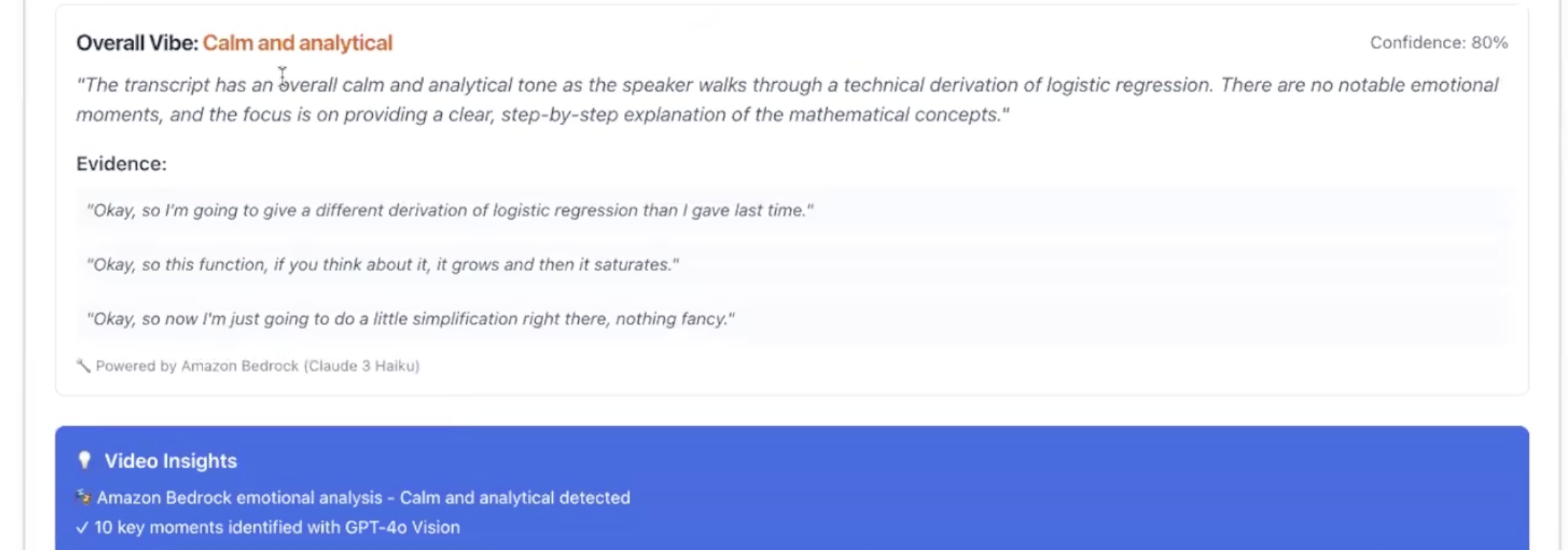
Emotional intelligence with AWS Bedrock
-
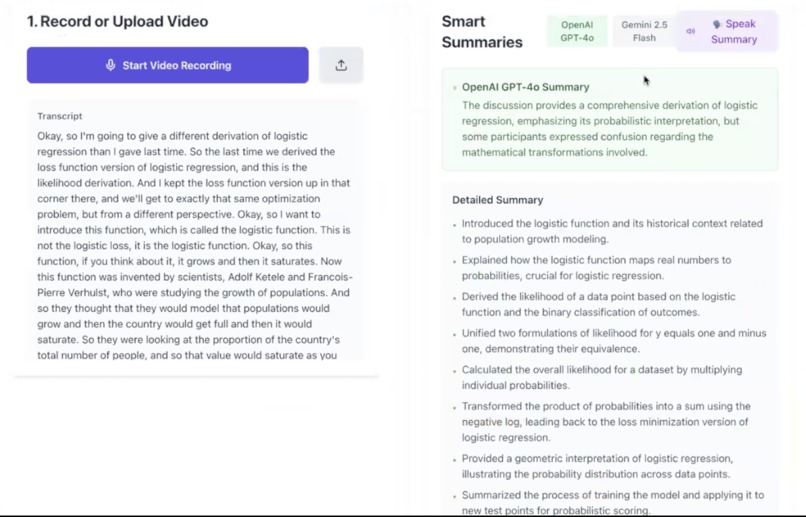
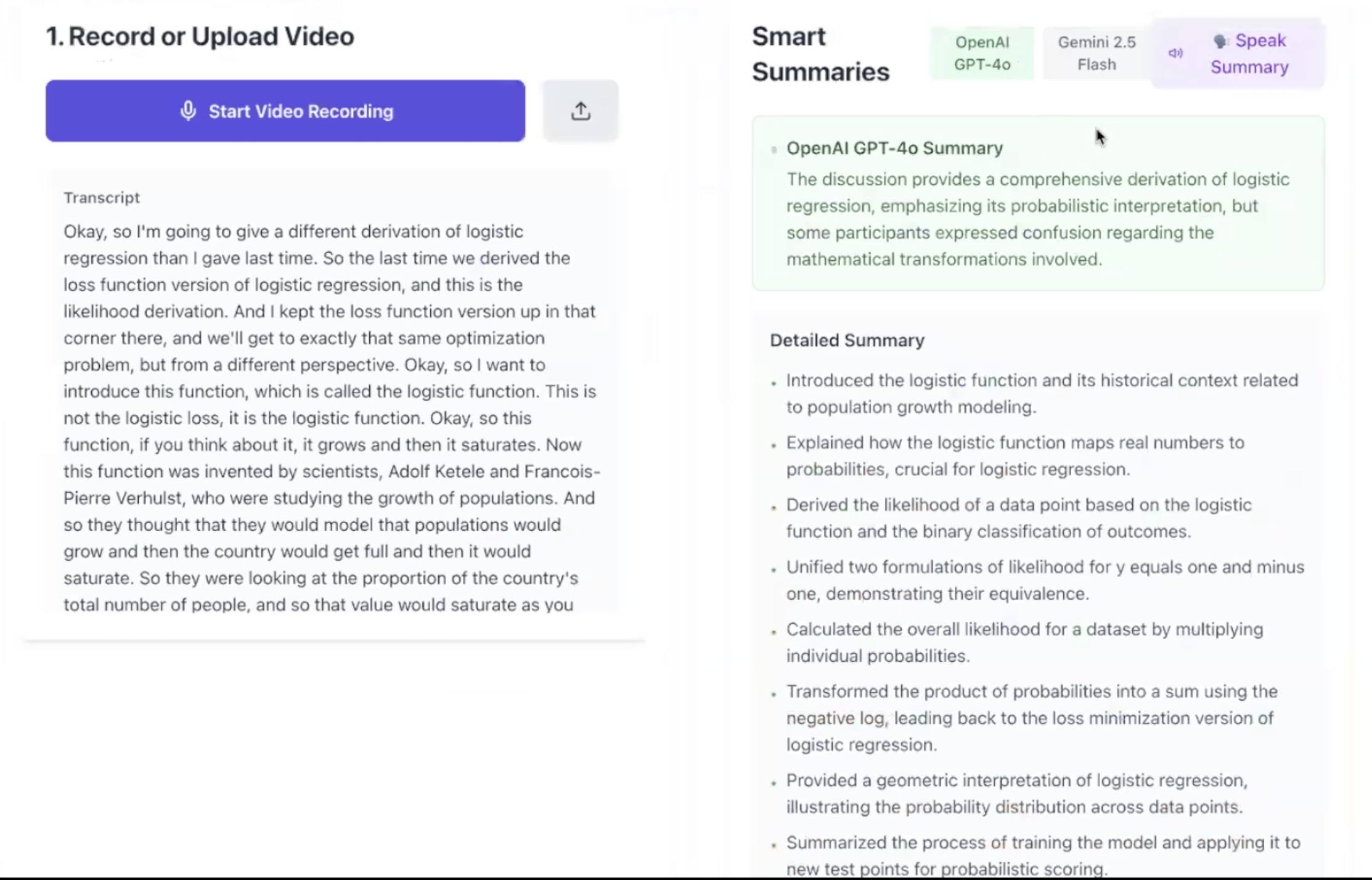
Gemini and GPT-4o summaries
Inspiration
We've all been in virtual meetings, lectures, and coffee chats where we struggle to pay attention, take notes, and identify key action items all at once. Valuable insights get lost, and tasks are forgotten. We wanted to build an intelligent companion that acts as an "everyday virtual executive" (EVE). Our inspiration was to create an AI that doesn't just record conversations but actively participates by listening, understanding, coaching, and taking autonomous action, turning messy spoken audio and video into structured, actionable data.
What it does
EVE is a multi-API, multimodal AI assistant that transforms spoken audio and video into structured, actionable intelligence.
- Transcribes & Fact-Checks: A user records or uploads audio or video (e.g.,
mp3,mp4,webm), which is transcribed by OpenAI Whisper and then "fact-checked" by GPT-4o to correct errors and technical terms. - Advanced Video Analysis: For
mp4files, EVE uses GPT-4o Vision and Gemini Vision to perform scene-by-scene analysis, extract text from slides (OCR), and identify key moments. - Dual AI Analysis: The transcript is processed in parallel by two AI models:
- OpenAI GPT-4o: Extracts tasks (with dates, owners, priority) and generates context-aware summaries for meetings, interviews, or lectures.
- Google Gemini 2.0 Flash: Provides a "second opinion" summary for cross-validation, which the user can toggle between in the UI.
- Autonomous Action: EVE identifies tasks with dates and, with one click, autonomously schedules them in the user's Google Calendar via OAuth 2.0.
- Voice Feedback & Coaching: The user can hear a smooth, natural-sounding voice recap of their summary, powered by ElevenLabs. EVE also provides context-aware coaching and a "vibe analysis" powered by AWS Bedrock (Claude 3 Haiku) to analyze social dynamics.
How we built it
We built EVE primarily using a Next.js 14/React frontend (with TypeScript and Tailwind CSS) and a Python/FastAPI backend. Kexin focused on designing and building the entire user experience. They created the sleek EVE logo and used Next.js, React, and Tailwind CSS to build all the core components. This includes the browser audio recording logic, dark mode, dual-AI summary toggle, and client-side Google Calendar auth flow.
Robert and Keona worked together on the FastAPI backend. Keona worked on EVE's autonomous capabilities and data pipelines, integrating the Google Calendar integration and implementing the server-side OAuth 2.0 flow, token exchange, and autonomous event creation logic. She also built the foundational transcription pipeline using OpenAI's Whisper and GPT-4o for fact-checking, integrated the Google Gemini API, and built the video processing pipeline using FFmpeg and GPT-4o Vision.
Robert focused on the core AI reasoning and personality. He implemented the OpenAI GPT-4o logic for task extraction and built the "adaptive summary" engine. He also integrated the ElevenLabs API to give EVE its voice and developed the "vibe check" service using AWS Bedrock (Claude 3 Haiku) to analyze social dynamics in coffee chats and interviews.
Challenges we ran into
Our main processing endpoint was a major challenge, especially for large media. Large video files (>100MB) can take 2-5 minutes to fully process because they require FFmpeg for frame extraction, transcription, and multiple calls to different vision AIs (GPT-4o Vision and Gemini Vision). In addition, integrating five distinct, complex APIs (OpenAI, Google Calendar, Google Gemini, ElevenLabs, and AWS Bedrock) was a significant hurdle. Each had its own authentication, error handling, and data models that we weren't really familiar with. Managing the Google Calendar OAuth 2.0 flow was particularly complex, requiring precise configuration of client secrets, redirect URIs (http://localhost:8000/calendar/callback), and test user permissions to make the "one-click" scheduling seamless. Finally, the "vibe check" feature, which uses AWS Bedrock (Claude 3 Haiku), added another layer of complexity. It required separate IAM permissions and AWS credentials, and we had to design it to degrade gracefully (i.e., turn off with a clear message) if the keys weren't configured, without breaking the entire app.
Accomplishments that we're proud of
- End-to-End Autonomous Action: Going from raw spoken audio or a video file to a confirmed Google Calendar event in just two clicks is a huge win.
- True Multimodal Analysis: We successfully integrated video analysis. EVE doesn't just listen; it watches. It uses FFmpeg, GPT-4o Vision, and Gemini Vision to extract text from slides, analyze scenes, and identify key visual moments.
- Dual-AI Cross-Validation: The UI lets users toggle between summaries from OpenAI GPT-4o and Google Gemini 2.0 Flash (AND a spoken summary from ElevenLabs for accessibility!), helping provide a true "second opinion".
- Adaptive Coaching & Vibe Check: EVE doesn't just summarize. It has context-aware coaching for interviews, coffee chats, and lectures. We are especially proud of the AI-powered "vibe analysis" (using AWS Bedrock) that provides social dynamics feedback based on the transcript.
- Polished & Resilient MVP: Kexin's design and frontend work, combined with the smoother, more efficient backend, make EVE feel like a real product! We also built the app to degrade gracefully, remaining functional even if optional API keys (like AWS or ElevenLabs) are missing. And, of course, our logo that's sort of reminiscent of OpenAI 🤔.
What we learned
We learned how to balance technical complexity with a creative user experience. We combined five different sponsor APIs (OpenAI, Google Calendar, Gemini, ElevenLabs, and AWS Bedrock) and complex asynchronous backend logic while keeping the app approachable and even fun, thanks to the conversational chat function. We also realized how important a clean UI is when handling so many features and diverse use cases. Features like the "vibe analysis" panel and the one-click task list were critical in making our web app feel intuitive.
What's next for EVE - The Everyday Virtual Executive
- True Real-Time Streaming: Implement the WebSocket logic (prototyped in our original vision) to provide transcription and insights as the user speaks.
- True Multimodal "Vibe" Analysis: Our current vibe analysis is text-based using AWS Bedrock (Claude). The next step is to integrate a service like Amazon Rekognition to analyze the video feed for facial expressions and tone, providing a true "vibe check" on how an interview or coffee chat is going.
- The "Second Brain": Fully integrate a persistent, searchable memory for users, allowing them to ask, "Show me all the career tips I've received in the last month."
Built With
- aws-bedrock
- eleven-labs
- fastapi
- google-calendar
- next.js
- openai
- openai-whisper
- react
- tailwindcss
- typescript



Log in or sign up for Devpost to join the conversation.