-
Poster Presentation

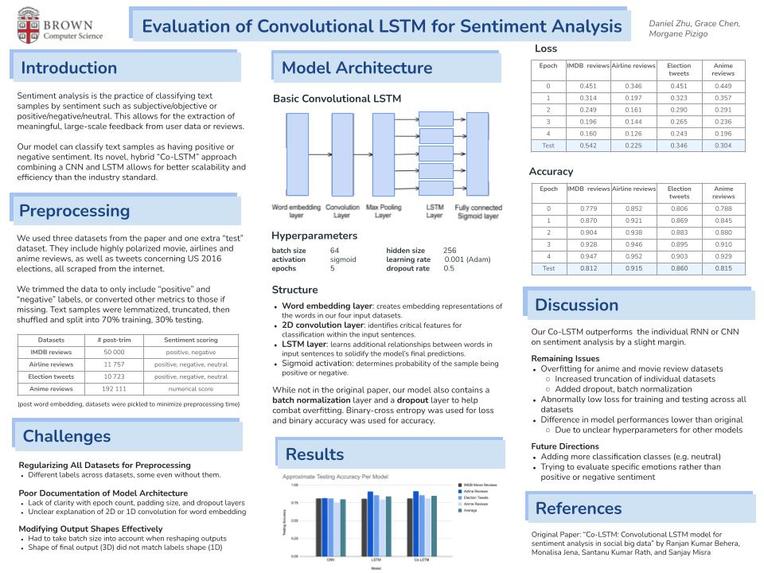
Title: Evaluation of Convolution LSTM for Sentiment Analysis Who: Morgane Pizigo (mpizigo), Grace Chen (gchen76), Daniel Zhu (dzhu36)
Introduction: Consumer reviews on social media are a goldmine of user data, and heavily influence business and brand image. However, it can be difficult to filter and extract some form of meaningful, large-scale feedback from them without the help of deep learning models. Sentiment analysis (a classification task) helps solve this issue by classifying reviews into predefined categories: subjective/objective, positive/neutral/negative… This approach has previously been used to filter through movie reviews and even predict political leanings of Twitter users with much success; however current models are struggling to keep up with the exponential increase in the amount of data available to handle .
The paper we have chosen outperforms previously implemented models for sentiment analysis by blending two deep learning architectures and drawing upon the benefits of each. This hybrid approach dubbed Co-LSTM combines the precise local feature selection of a CNN with the effective sequential analysis of an LSTM. This allows for better scalability with big social data and makes for a more adaptable, non domain-specific model. This new flexible approach helps us take full advantage of current social big data when performing sentiment analysis.
Related Work: Considerable research has been conducted on sentiment analysis for media opinion evaluation using deep learning – our project’s central focus. One 2014 research paper trained a convolutional neural network (CNN) to pinpoint character-level and sentence-level patterns in short texts such as Twitter messages or movie review sentences to evaluate emotional affect. Their model resulted in varied testing accuracies when applied to different datasets, but the accuracies were generally in the 80% to 90% range. A 2018 research paper further proposed using LSTMs and attention mechanisms to correctly classify positive and negative overall sentiment in potentially contradictory data (e.g., a neighborhood review in the SentiHood dataset that contains some criticism but is overall positive). The model’s testing accuracy fell within the 80% to 90% range. Furthermore, a 2016 article proposed combining the CNN and RNN architectures (mentioning both GRUs and LSTMs) for sentiment analysis of short-texts. The article rationalized their decision by mentioning a CNN’s ability to extract local defining features as well as an RNN’s ability to capture long-distance word dependencies reasonably well. The model’s testing accuracies across three different datasets were approximately 80%, 50%, and 90%. The article also noted that the combined CNN-RNN architecture performed better than CNNs or RNNs alone on their testing datasets. The paper whose model we wish to emulate builds upon the 2016 article by also utilizing CNNs and RNNs for sentiment analysis, with some additional layers.
Data: Our project will be using three of the four datasets cited in the paper (as the fourth one was no longer available). These include the “Large Movie Review Dataset” known as the IMDB dataset, which contains 50,000 highly polar movie reviews; the Airline Sentiment Review dataset containing 55,000 positive, neutral, or negative Twitter reviews from 6 major US airlines scraped from Twitter from January 2013 to February 2014 by the Wan and Gao (2015) paper; and the US Presidential Election Dataset with 13,871 positive, neutral, or negative Twitter posts scraped from Twitter in 2016. Finally, we will be using a fourth “experimental” dataset to test the effectiveness of our model, namely an Anime Review Dataset containing 130,000 reviews with an associated numerical rating, scraped from myAnimelist.com.
This data will necessitate significant preprocessing, as all four datasets are formatted differently, and do not all match the positive/negative format. Two include “neutral” reviews that will have to be excluded, and one contains a numerical score that will have to be converted to a “positive” or “negative” review instead.
Methodology: Our model will primarily consist of a word embedding layer, a convolution layer, and an LSTM layer, in that order. The word embeddings will create embedding representations of the various words in our movie review dataset. The convolution layer will be used to identify critical features in the movie review sentences to the model’s eventual determination of whether a review is positive or negative. The LSTM layer will learn additional relationships between words in input sentences that will help solidify the model’s final prediction. The output of the LSTM layer will be inputted into a fully connected layer and then a sigmoid activation layer to determine the probabilities of a movie review being positive or negative. Our overall model structure will approximately resemble that in the following image (which is also included in the paper whose model we’re trying to recreate):
Our model will also contain an extensive pre-processing class. This class will take movie reviews directly from our datasets, represent those movie reviews numerically, replace uncommon words with an “unknown” token, and then truncate the review so that all reviews will have a length of 25. The results of pre-processing will then be inputted into the word embedding layer. We suspect that this preprocessing stage will be the hardest part about implementing this model due to the vast amount of data we need to modify. The pre-processing class will have the following architecture taken from the article:
We will train our model by splitting our pre-processed data into 80% training data and 20% testing data. Our model’s performance will be updated based on gradient backpropagation from our final sigmoid layer up until our convolution layer, where the parameters of our convolution layer, LSTM layer, and fully connected pre-sigmoid layer will be modified through gradient descent. We will use binary cross-entropy loss as our loss function – our model will evaluate inputs as being positive reviews or negative reviews.
Metrics: Since our model will use binary classification for sentiments, we measure our success using the accuracy of our model. Accuracy will be calculated using four components: true positives, false positives, true negatives, and false negatives. Specifically, accuracy will be the fraction of samples predicted correctly.
In the existing project that we are implementing, the authors were hoping to find better performance parameters for their Co-LSTM model compared to support vector machines (SVM), Naive Bayes, Linear Regression, Random Forest, and CNN/RNN individually. The performance parameters were quantified using 4 measures, including accuracy. The performance parameters also included precision, recall, and F-measure.
Our base goals for the project are to have a working model with the movie review dataset. This includes the word embedding layer, the convolutional and max pooling layer, the LSTM layer, and the sigmoid layer. Our target goals will be to implement preprocessing for the other datasets using the paper and ensure stable outputs for those datasets. Our stretch goals will be to feed a new dataset not used in the paper (the anime review dataset) into the model and obtain stable outputs. We are also considering experimenting with different architectures including a transformer, just a CNN, and just an RNN.
Ethics: Deep learning is an effective approach to sentiment analysis of big social media data compared to traditional machine learning approaches. SInce social media review data can be very nuanced and involve complex elements such as sarcasm and slang, sentiment can be hard to predict. Traditional statistical approaches must rely on high-quality feature engineering of the review data, and even then, the model trained may only be limited to a specific domain of knowledge (eg. restaurant reviews). Using a deep learning approach will allow our model to capture complex sequential and contextual information from a given review at relatively lower cost. Using deep learning, our model will also have an enhanced ability to generalize to different domains in sentiment analysis and allow us to apply our model to various types of review data.
The major stakeholders for our model might include retail companies (such as Walmart), advertising companies, and the companies/founders behind the products. Retail companies might be interested in this model in order to classify the reviews for products on their website and bump up products that have considerably larger numbers of good reviews. Similarly, advertising companies could use our model to identify good reviews for a product and understand what customers/users generally like to see. Furthermore, the companies/founders of the product can look for negative reviews for competing products. This will allow them to understand how to design their product to better appeal to the consumer base. Since there will be a lot of finances involved in the decisions of these companies, a mistake in our algorithm could potentially cost a company millions or billions of dollars in revenue. Issues in our algorithm may also lead to bias in search results if a company decides to use our model to promote certain “well-performing” products.
Division of labor: We plan for Morgane to handle the data preprocessing and word embedding layer, Grace to handle the convolution layer and max pooling layer, and Daniel to handle the LSTM layer and sigmoid activation layers. We plan to work on the other parts of the project, such as creating the poster, together whenever convenient.
Built With
- keras
- python



Log in or sign up for Devpost to join the conversation.