-
ARX risk analysis
-
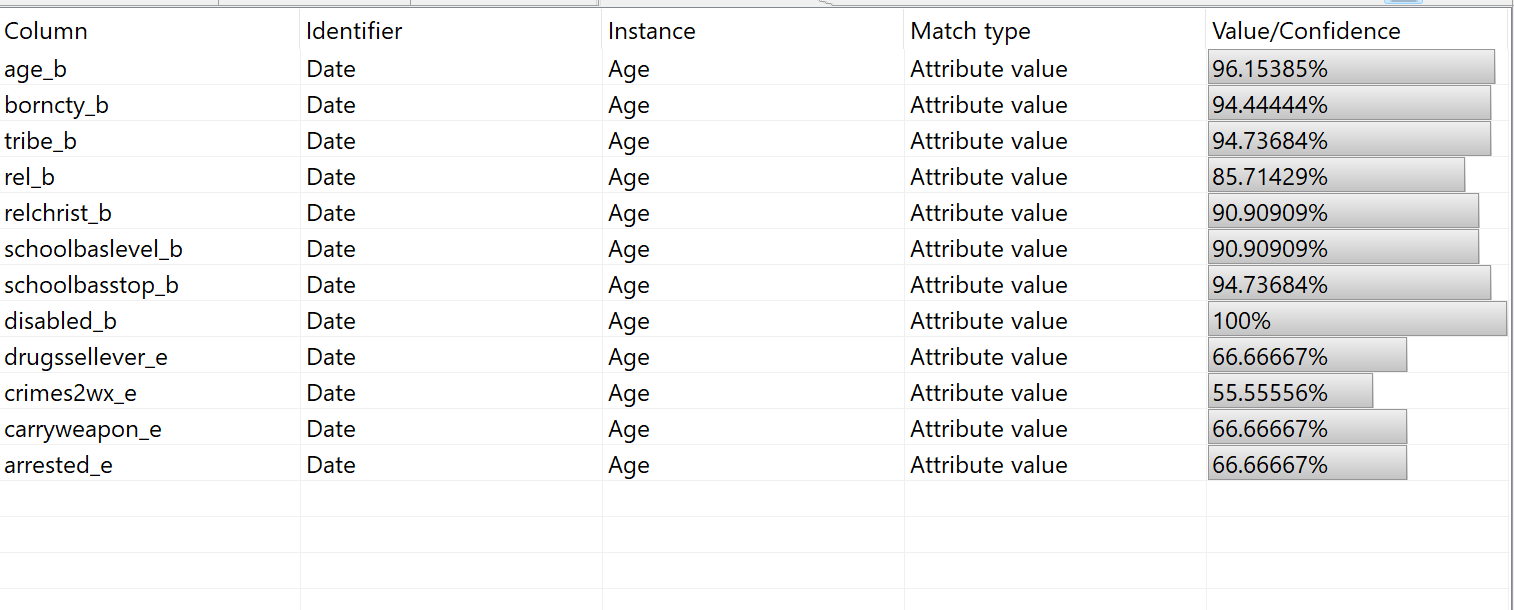
cross examining data
-

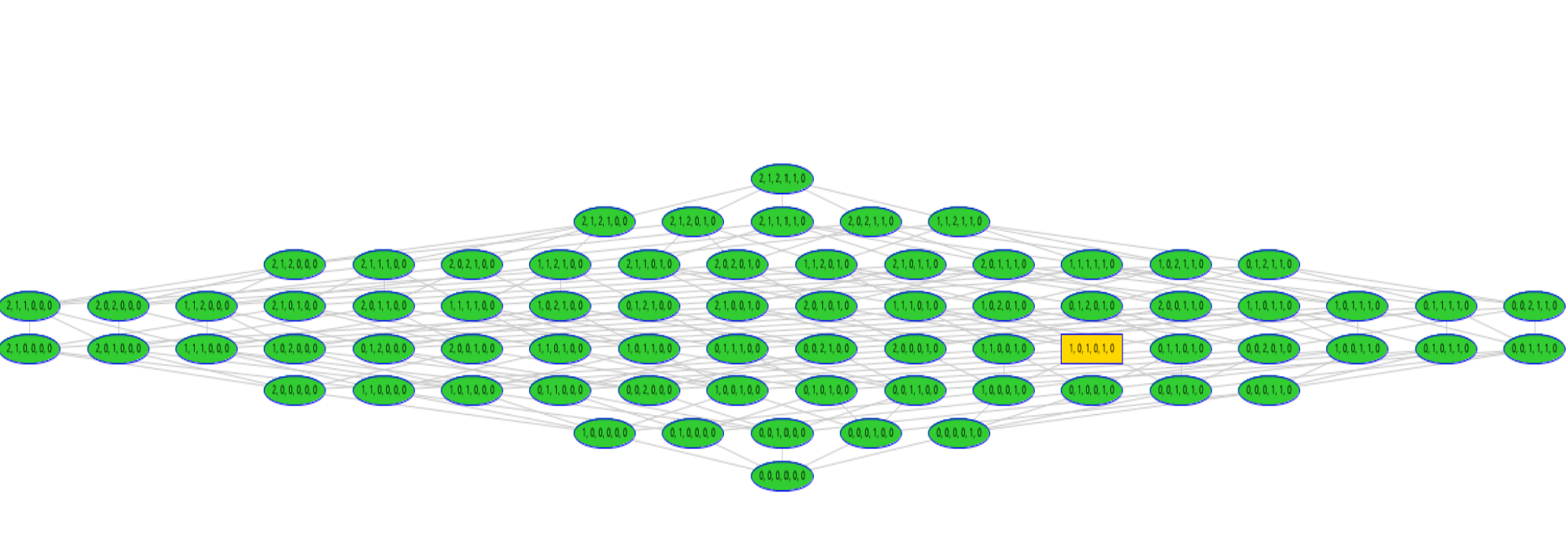
k-anonymity
-

anonymized data clusters
-
hippa identifiers
-

population uniqueness and risk factors


Inspiration
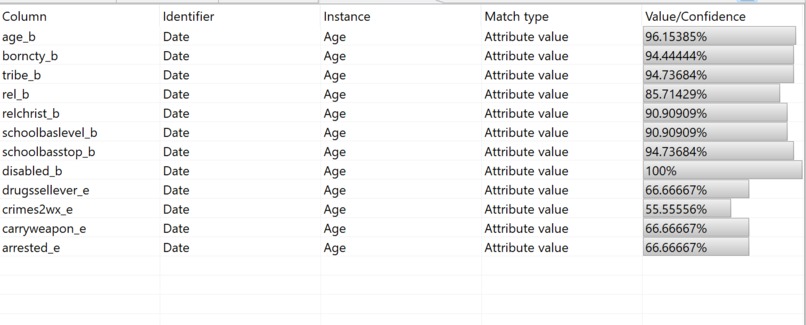
Sensitive personal information is consistently collected from social and behavioral research studies, which could potentially put participants at risk of identification and even further harm. For example, many studies involve gauging the political climate of a particular area. Participants are often asked about their age, religion, economic status, etc., in combination with their political opinions. The combination of key identification information with explicit opinions could make it easier for groups with malicious intentions to re-identify individuals and target them. Therefore, it is important to implement de-identification techniques on social and behavioral research data so that individuals cannot be re-identified and potentially targeted.
What it does
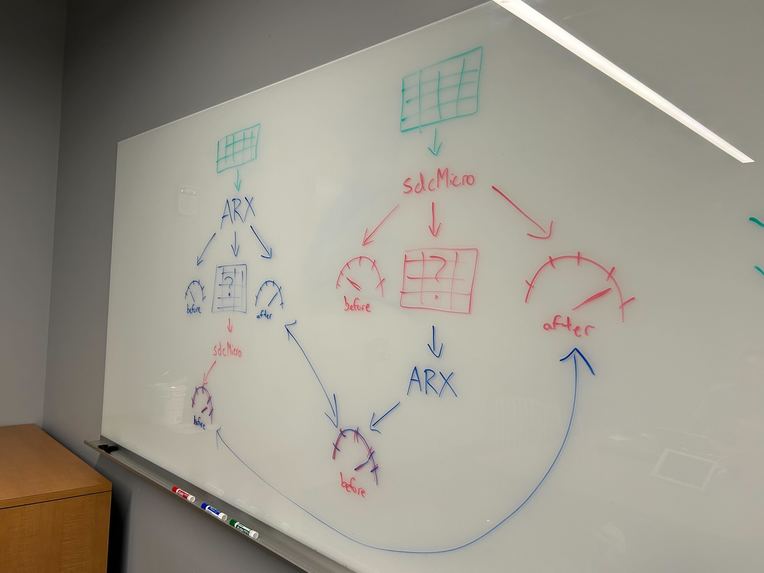
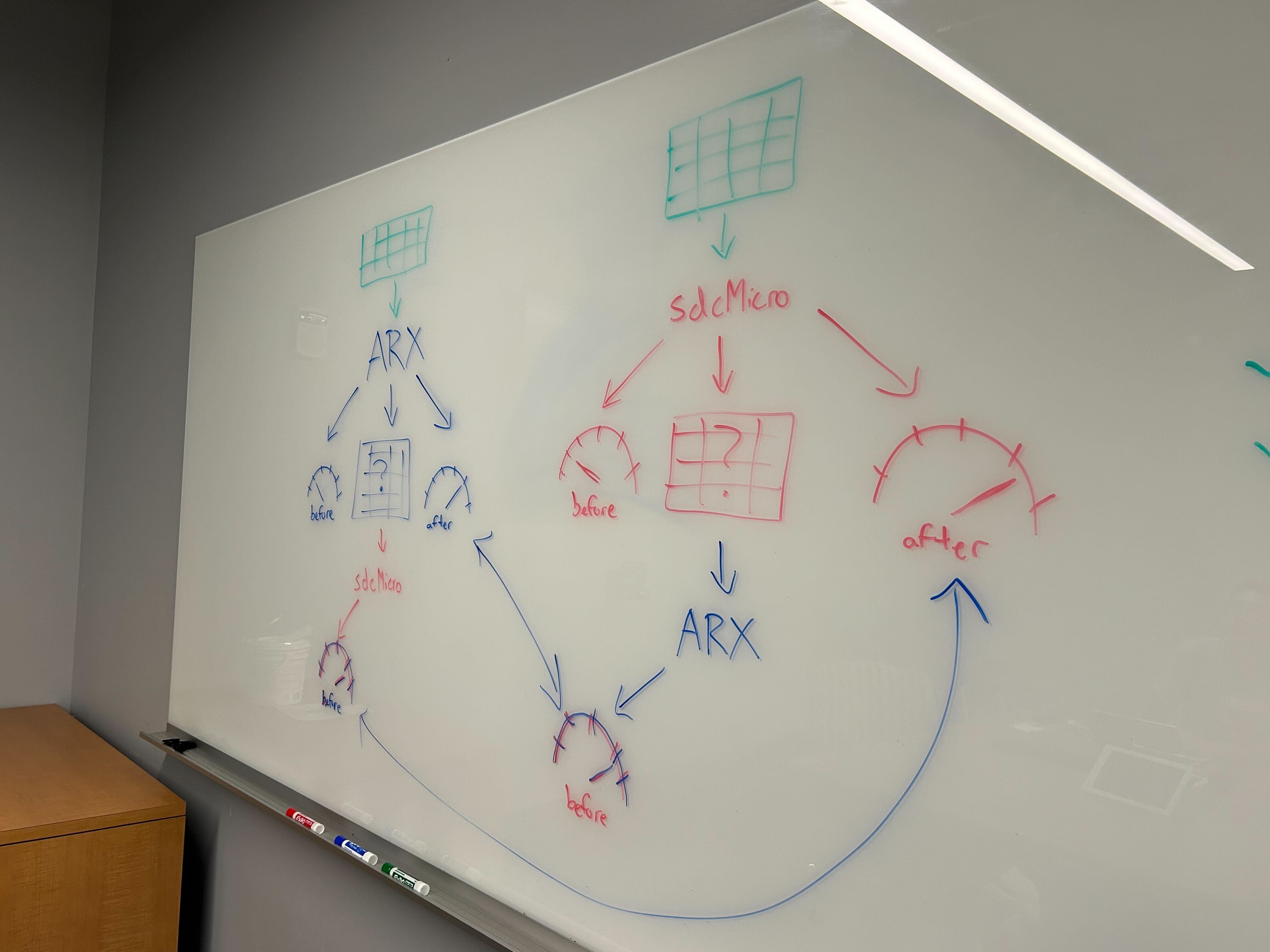
De-identification techniques involve anonymizing key pieces of information, aiming to find a fair balance between risk and utility. There currently exist many techniques and applications that de-identify data; however, it is important to cross-examine data from multiple de-identification sources to ensure their validity and reliability.
How we built it
We examined SDCMicro and ARX, which are both de-identification tools that analyze microdata against risk and utility. We began our experiments by splitting into two groups and individually investigating how to use each tool and how to de-identify data. By reviewing research papers on the de-identification of social and behavioral data and finding online resources on how to use SDCMicro and ARX, we were able to manipulate and run different algorithms on a sample dataset that involved multiple types of sensitive information.
Challenges we ran into
Before we began any analysis, we had to understand what we were investigating to begin with. This involved learning about what de-identification meant and the common methods used to de-identify data from the graduate students who were assisting us with the project. Given that this was our first time using de-identification tools, there was an evident learning curve, which we overcame with the guidance of the graduate students and the resources we found online.
Accomplishments that we're proud of
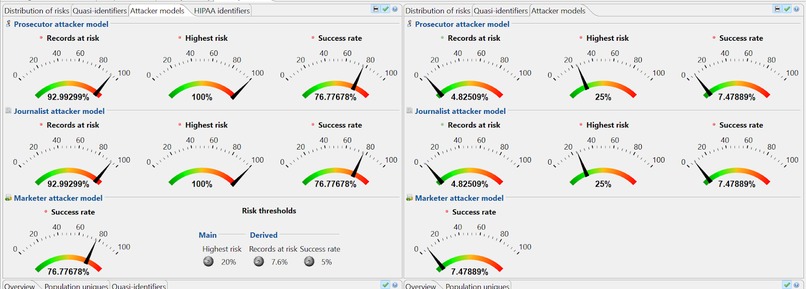
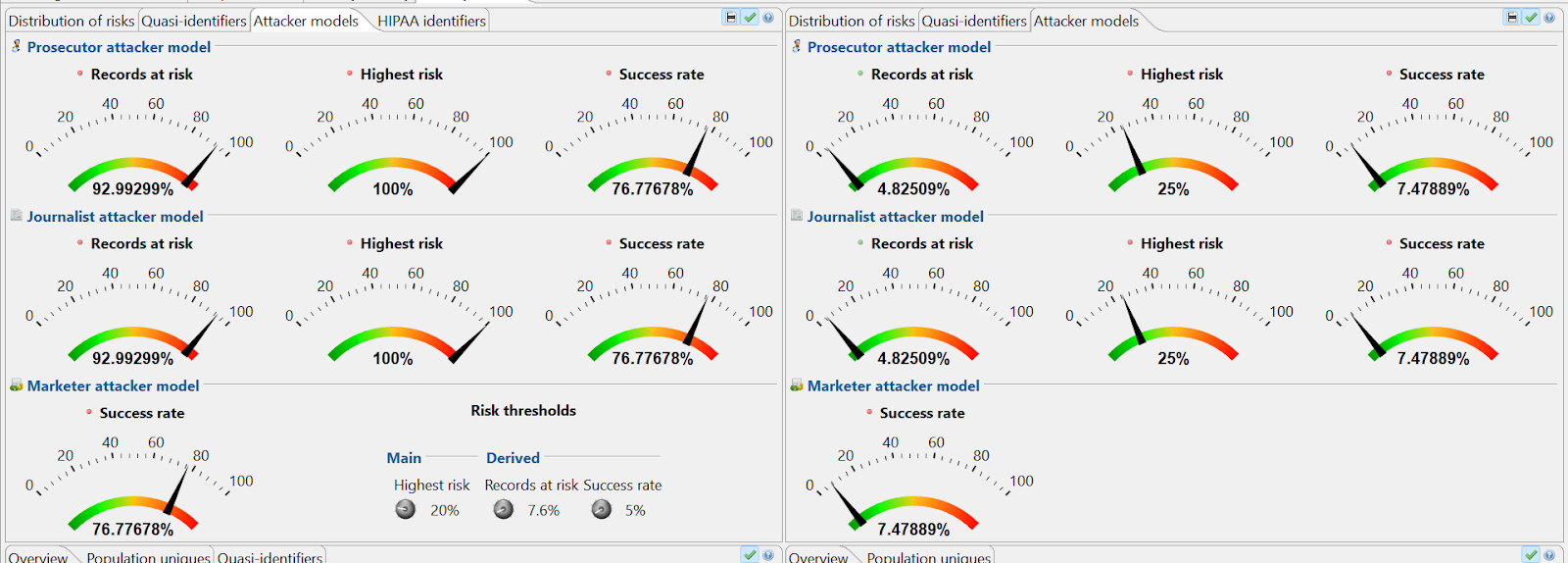
Once we learned the basic mechanics of each tool, we were able to exchange data collected from de-identifying the sample dataset on each tool individually. We were then able to cross-examine our datasets and test whether the de-identification tools could measure a similar risk and utility. This result was ultimately successful, as we were able to see similar, if not the same, measurements of risk and utility on the other tool without manipulating the data at all.
What we learned
We learned about the significance and importance of de-identifying social and behavioral data, including the potential risks it poses to participants and the risk and utility factors that researchers must weigh. We also learned how to use SDCMicro and ARX to run de-identification experiments. Additionally, we learned about different de-identification techniques that can be run on these tools, including k-anonymity and differential privacy.
What's next for Evaluating Impact Of De-Identification On Behavioral Data
In our experiment, we de-identified the data in different ways across the different tools since we were ultimately seeking to understand each tool. It would be more consistent to run the same experiment involving the same de-identification techniques on both tools to see if there are any biases with each tool or if either tool is better at analyzing a particular technique.
Built With
- arx
- r
- sdcmicro




Log in or sign up for Devpost to join the conversation.