-
-
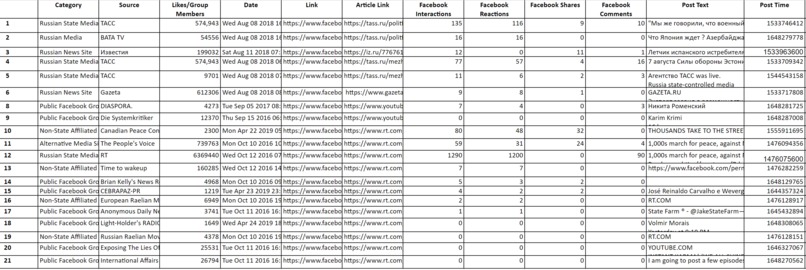
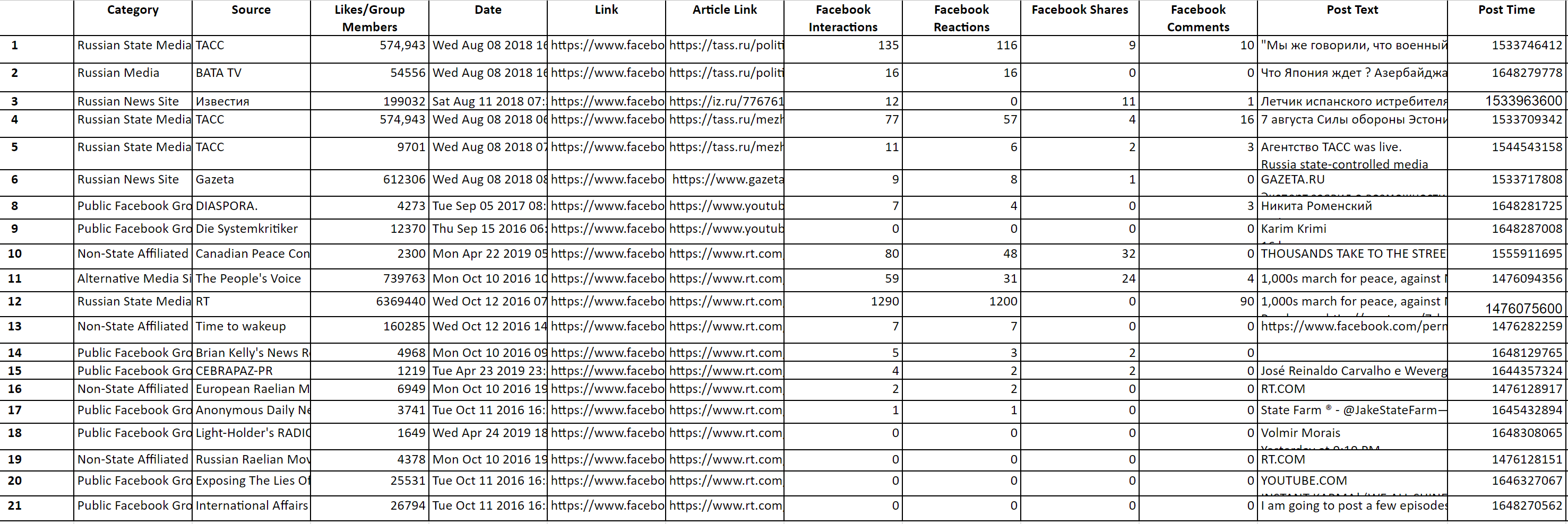
Main DataFrame - Anti-NATO Disinfo @ Estonia
-
-
-
-
-
Inspiration
We co-direct DisinfoLab, W&M's student-led disinformation research lab. In anticipation of the upcoming June 2022 NATO Conference, DisinfoLab is pursuing a mixed-methods investigation at the intersection of social media and international politics: the state of disinformation in Eastern Europe.
Using quantitative and qualitative analysis, DisinfoLab's project will assess the disinformation resiliency of Estonia, Hungary, Poland, and Ukraine, and offer relevant policy recommendations to NATO.
During Cypher VII, we developed a series of webscraping tools to facilitate DisinfoLab's quantitative analysis. Despite the major international security consequences of the spread of mis- and disinformation in Eastern Europe, relevant data and research tools are sparse. Given Russia's recent invasion of Ukraine, supplemented by a barrage of disinformation that seeks to justify the war, research into this region is especially critical. Our code and methodology will not only help DisinfoLab in its investigation, but will also aid disinformation researchers across the world in collecting data from previously untapped corners of social media.
What it does
Our project evaluates the disinformation resiliency of Eastern Europeans using a proof-of-concept test case: Anti-NATO disinformation targeted at Estonians. Following a generalizable 5-step methodology, we determined the primary sources of Anti-NATO disinformation on Facebook and the duration of engagement with such posts. These insights can aid social media companies, lawmakers, NGOs, and educators in understanding what works and what doesn't work in the fight against disinformation. Going forward, we will follow the same method to both deepen our analysis and expand it to more topics across all four countries.
The 5-Step Method:
Collect salient disinformation articles targeted at the focus country. Make note of the disinformation topic and the target country. For this project, we identified Anti-NATO articles (topic) aimed at Estonia (target country). We used propastop.org, an Estonian fact-checking website, to identify these articles.
Enter disinformation articles into CrowdTangleCollectionScript.py. This script uses the CrowdTangle Chrome Extension to identify public social media posts linking to the disinformation articles.
Enter CrowdTangle data downloads into CrowdTangleCompilation.py. CrowdTangle generates a unique .csv file for every article it analyzes. This compilation script formats and combines these files into a workable format for data analysis.
Enter compiled CrowdTangle data into FacebookCollectionScript.py. This script will collect relevant Facebook post data for analysis, including the post's text, datetime, poster/commenter ID, and comments.
Analyze the data to identify substantive trends. We investigated the primary sources of disinformation and duration of engagement with such posts, but there's more tools in the works! We're pursuing: i. Using VADER to conduct sentiment analysis on each post's text and comments. This will allow us to determine if the users are affirming disinformation narratives or debunking them. ii. Visualizing connections between posters and commenters to identify networks of disinformation.
How we built it
CrowdTangleCollectionScript.py:
This script collects the URLs of public social media posts containing disinformation articles. The social media data collection is made possible through CrowdTangle. CrowdTangle has an API that is access-restricted to professors and professional researchers. To work around this limitation, we made use of CrowdTangle's Chrome Extension (available to everyone), and employed the pyautogui library to automate navigation to relevant URLs and downloading of data.
CrowdTangleCompilationScript.py:
This script formats and combines downloaded CrowdTangle files into a workable format for data analysis. To ensure easily-available data access and manipulation, we use the pandas library to create a main dataframe.
FacebookCollectionScript.py:
This script collects relevant Facebook posts, including the post's text, datetime, poser/commenter ID, and comments. We collect this data using the facebook-scraper library to avoid the need for a Facebook Graph API key. Relevant data is appended to the aforementioned main dataframe.
Challenges we ran into
Issues We Resolved
Browser Load Time: Different webpages and CrowdTangle analyses have varied load times. During our early testing of CrowdTangleCollectionScript.py, our script sometimes moved on to the next webpage before the CrowdTangle report was available for download. We implemented optimized delays between commands to ensure that we got every report without sacrificing scalability.
Data Organization: CrowdTangle's report format is ill-equipped for our project. We had to think through how to format redundant data across massive data sets in a format that would be conducive to both programmatic and manual/qualitative analysis. Our main dataframe is formatted with these expectations in mind.
Pending Issues
Language Differences: Given the regional focus of our project, a number of social media posts and comments that we analyze will be in a non-English language. To analyze these data points we plan on using a translation API, but we remain cognizant of the potential loss of accuracy and precision this may inflict upon the original text.
Accomplishments that we're proud of
These tools are the first step into conducting large-scale social media analysis on Eastern European countries to an extent that has never been done before. We are incredibly proud to have proved a viable quantitative methodology for DisinfoLab's intended research project, and we are even more excited for the potential implications these tools will have for the global disinformation research community.
What we learned
From our data collection and analysis on a sample of Anti-NATO disinformation targeted at Estonia, we found:
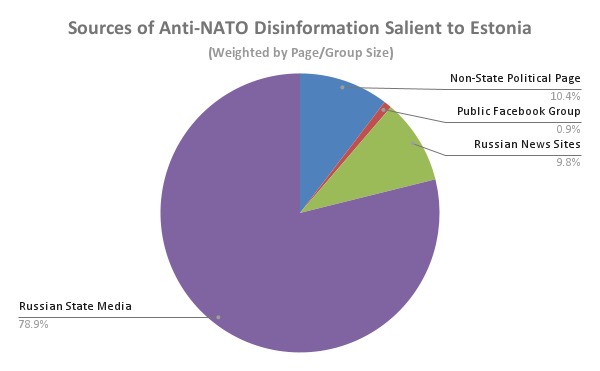
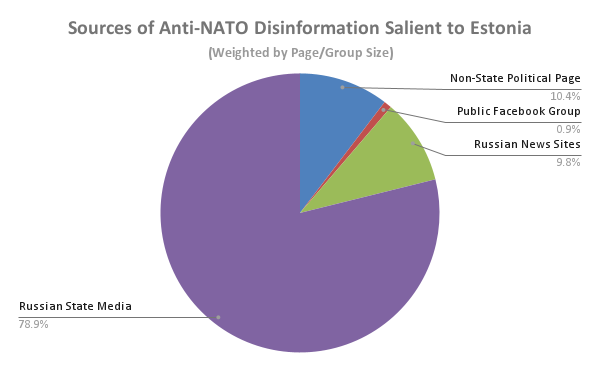
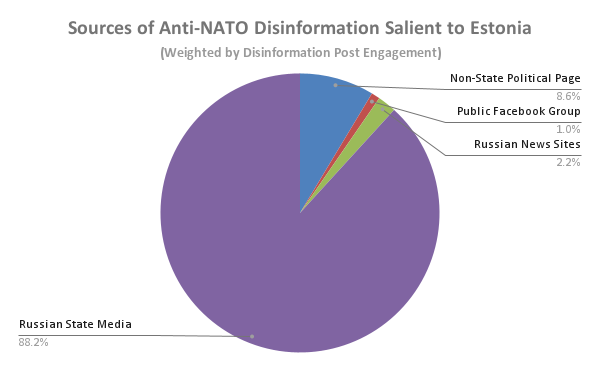
1a) Weighted by page/group size, such articles were posted by: Russian State Media (78.9%), Non-State Political Pages (10.4%), Russian News Sites (9.8%), and Public Facebook Groups (0.9%).
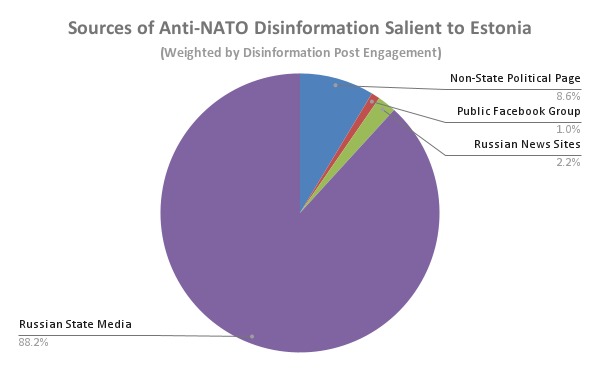
1b) Weighted by post interaction, such articles were posted by: Russian State Media (88.2%), Non-State Political Pages (8.6%), Russian News Sites (2.2%), and Public Facebook Groups (1.0%).
These findings suggest that Russian State Media is a major source of disinformation that stakeholders should aim to address. Despite the "community" element of Public Facebook Groups, these entities play a relatively small role in sharing such articles.
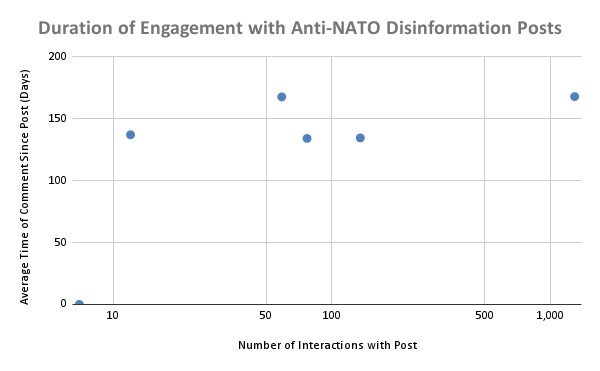
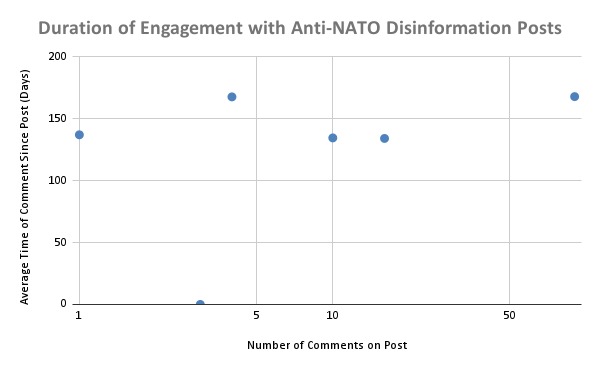
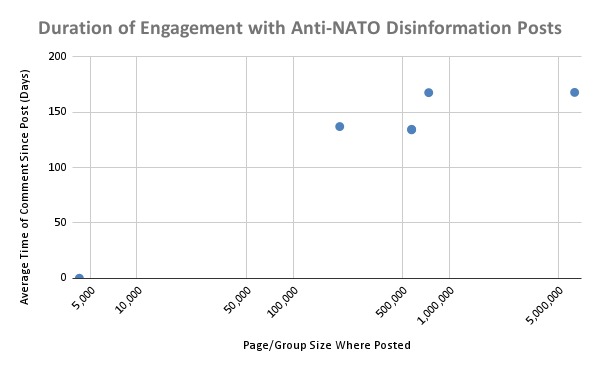
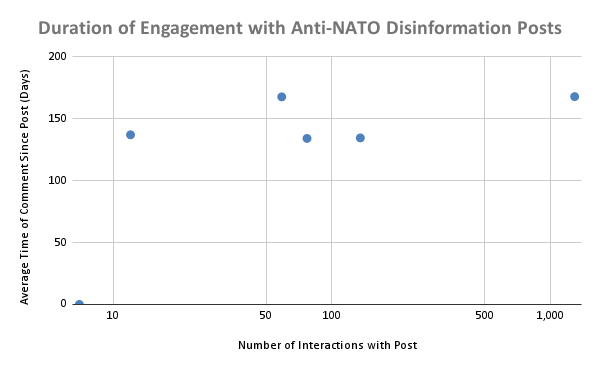
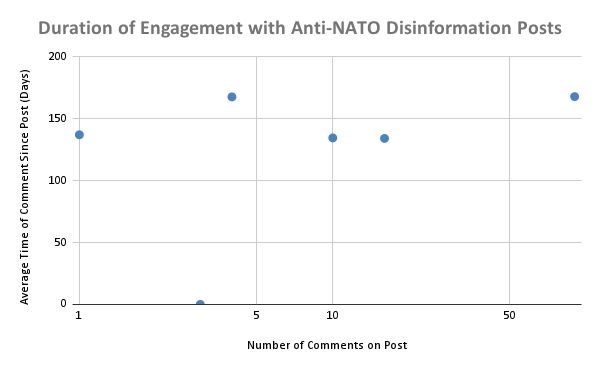
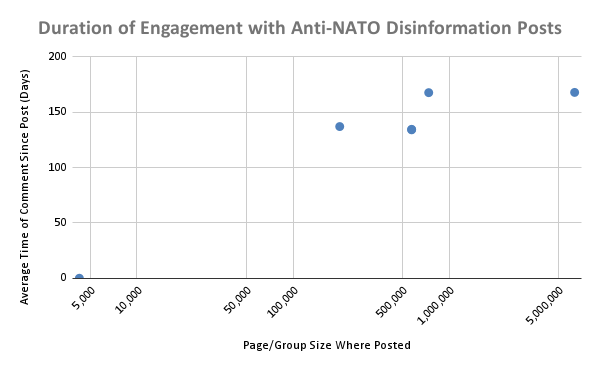
2) There is limited correlation between the number of interactions and comments on a post containing disinformation and how long users continue to interact with it. This finding suggests that posts containing disinformation have a limited lifespan for spreading, even if they initially see high engagement.
What's next for Evaluating Disinformation Resiliency in Eastern Europe
This project functioned as a proof-of-concept that will support a much larger and richer research agenda that will allow us to offer actionable policy recommendations to NATO on combatting disinformation in Eastern Europe. We plant o expand this project in two dimensions:
As described in the "5-Step Method," we will deepen our data analysis to consider sentiment analysis and potential networks of disinformation-spreading users discerned through our data collection.
We will expand our data analysis to a greater number of topics across all four countries of interest. This will allow us to compare disinformation resiliency across countries, and suggest how the political and historical context of each country determines its current state.
Built With
- crowdtangle
- facebook-graph
- pandas
- pyautogui
- python

Log in or sign up for Devpost to join the conversation.