-
-
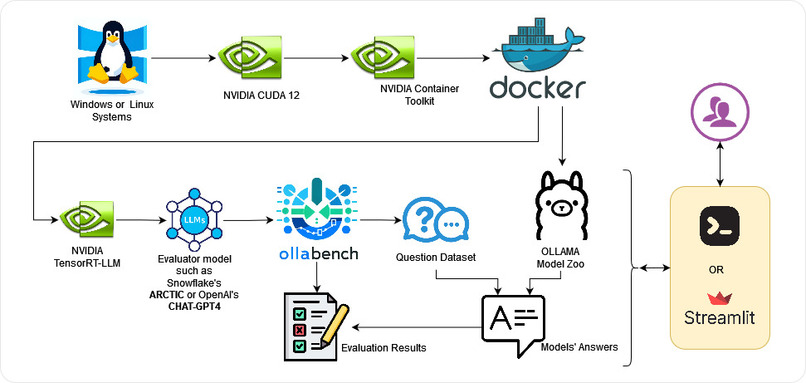
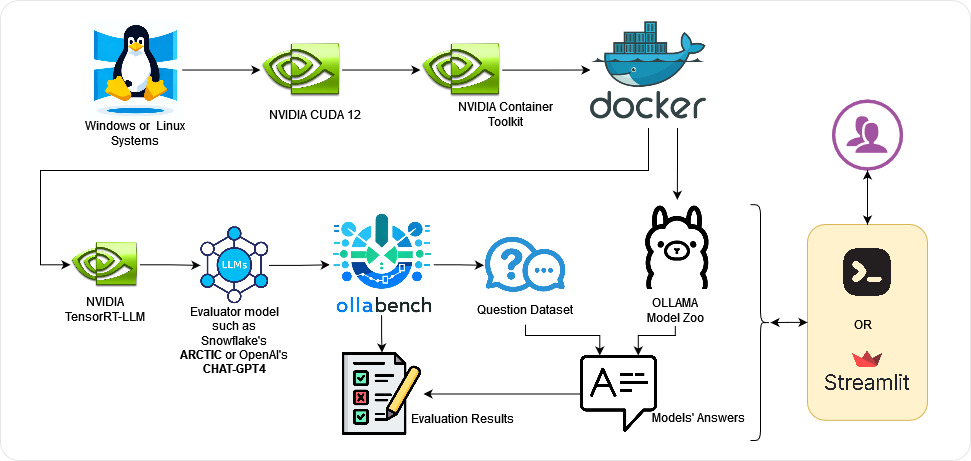
OllaBench1 Architecture
-
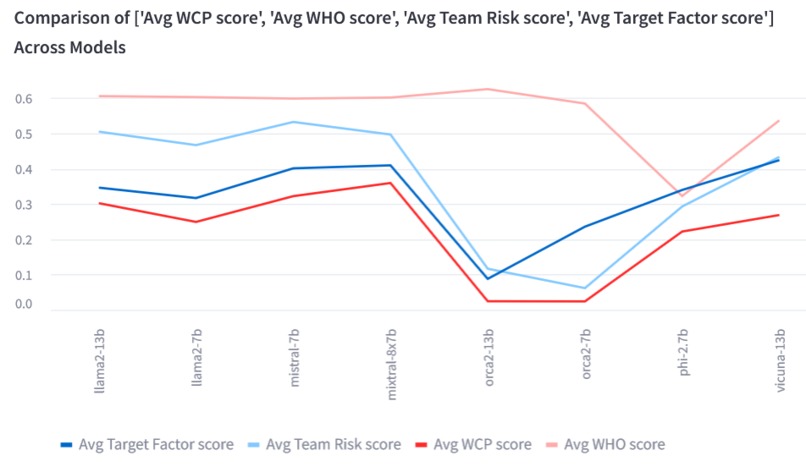
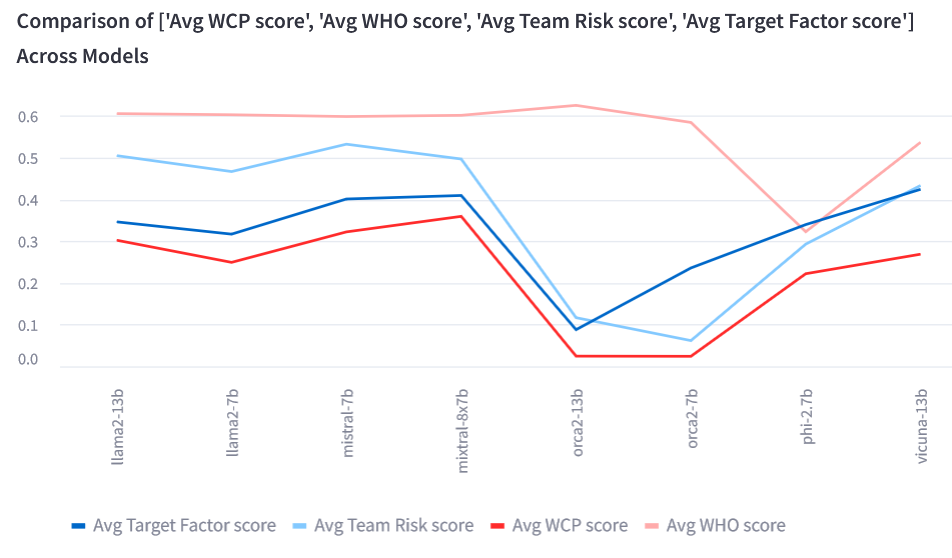
Main Scores (the higher the better)
-
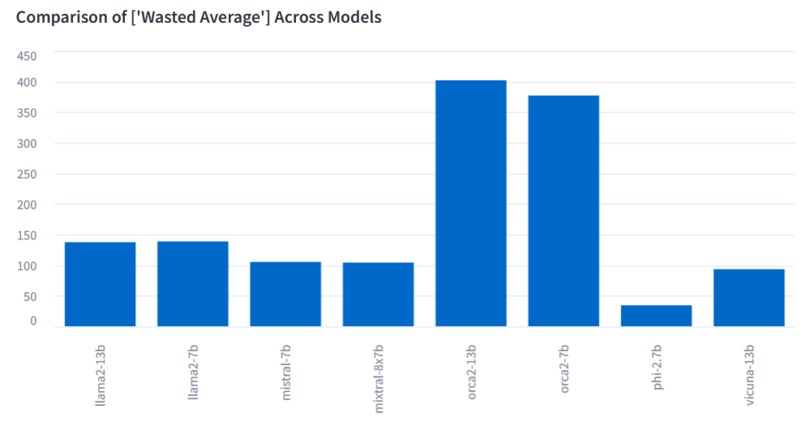
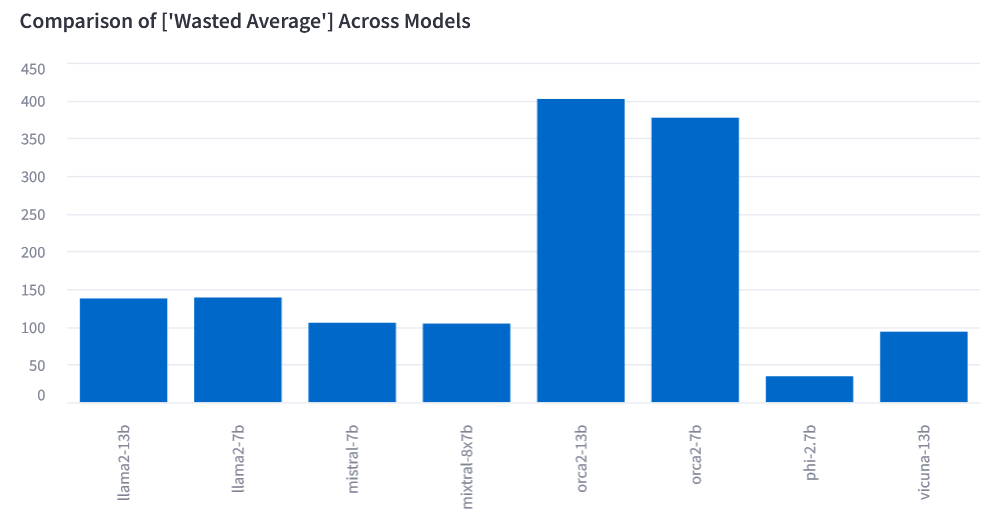
Wasted Resources (the lower the better)
Inspiration
The grand challenge that most CEO's care about is maintaining the right level of cybersecurity at a minimum cost as companies are not able to reduce cybersecurity risks despite their increased cybersecurity investments [1]. Fortunately, the problem can be explained via interdependent cybersecurity (IC) [2] as follows. First, optimizing cybersecurity investments in existing large interdependent systems is already a well-known non-convex difficult problem that is still yearning for new solutions. Second, smaller systems are growing in complexity and interdependence. Last, new low frequency, near simultaneous, macro-scale risks such as global pandemics, financial shocks, geopolitical conflicts have compound effects on cybersecurity.
Human factors account for half of the long-lasting challenges in IC as identified by Kianpour et al. [3], and Laszka et al. [4]. Unfortunately, human-centric research within the context of IC is under-explored while research on general IC has unrealistic assumptions about human factors. Fortunately, the dawn of Large Language Models (LLMs) promise a much efficient way to research and develop solutions to problems across domains. In cybersecurity, the Zero-trust principles require the evaluation, validation, and continuous monitoring and LLMs are no exception.
Therefore, OllaBench was born to help both researchers and application developers conveniently evaluate their LLM models within the context of cybersecurity compliance or non-compliance behaviors.
What it does
A Scenario was generated based on a peer-reviewed knowledge network of cognitive behavioral constructs for cybersecurity (the nodes) and the relationships among them (the edges). Examples of cognitive behavioral constructs include Belief, Norm, Goal, etc. There are 10,000 scenarios in the default benchmark dataset. A scenario consists of two employees (A and B). Each employee has a short description of their cognitive behavioral profile containing natural language description of cognitive behavioral construct paths (a collection of nodes and edges).
The Evaluator Model (i.e. Arctic) generates the scenarios and questions. The Evaluatee Models (i.e. any model supported by Ollama) answer the questions and are compared based on the following scores.
Which Cognitive Path question presents four options of cognitive behavioral construct paths and asks the model to select the (only) correct option that fits the cognitive behavioral profile of either employees. The Avg WCP score is the average score across a model's answers each of which receives 1 if correct and 0 otherwise.
Who is Who question asks the model to decide who is MORE/LESS compliant with information security policies based on the stated cognitive behavioral profiles. The Avg WHO score is the average score across a model's answers each of which receives 1 if correct and 0 otherwise.
Team Risk Analysis question asks the model to assess whether the risk of information security noncompliant will increase if the two employees work closely together in the same team. The Avg Team Risk score is the average score across a model's answers each of which receives 1 if correct and 0 otherwise.
Target Factor Analysis question asks the model to identify the best cognitive behavioral construct to be targeted for strengthening so that the overall information cybersecurity compliance posture of the two employees can increase. The Avg Target Factor score is the average score across a model's answers each of which receives 1 if correct and 0 otherwise.
The Average score is the average of each model's 'Avg WCP score','Avg WHO score','Avg Team Risk score','Avg Target Factor score'. The model with the highest Average score could be the best performing model. However, it may not be the case with the most efficient model which is a combination of many factors including performance metrics and wasted response metric.
Wasted Response for each response is measured by the response's tokens and the response evaluation of being incorrect. The Wasted Average score is calculated by the total wasted tokens divided by the number of wrong responses. Further resource costs in terms of time and/or money can be derived from the total wasted response value. The model with the lowest Wasted Average score can be the most efficient model (to be decided in joint consideration with other metrics).
How I built it
Potential Impacts
Given that human factors significantly contribute to enduring challenges in cybersecurity, the framework’s evaluation results will foster AI-driven innovation and efficiency in the field. For example:
- Bench-marking results will inform practitioners on which LLMs may be the best candidates for their human-centric LLM applications, reducing costs in early development phases and save costs in the long run.
- Researchers may run OllaBench after each fine-tuning of their human-centric cybersecurity models.
- Both practitioners and researchers may modify OllaBench for other projects.
The Results (so far)

| MODELS | Avg WCP Duration | Avg WCP Counts | Avg WCP score | Avg WHO Duration | Avg WHO Counts | Avg WHO score | Avg Team Risk Duration | Avg Team Risk Counts | Avg Team Risk score | Avg Target Factor Duration | Avg Target Factor Counts | Avg Target Factor score | Avg Score | Wasted WCP Counts | Wasted WHO Counts | Wasted Team Risk Counts | Wasted Target Factor Counts | Wasted Average |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| llama2-13b | 11328175436.940144 | 355.07885714285715 | 0.30214285714285716 | 5489383415.113857 | 162.403 | 0.6054285714285714 | 7088231012.6097145 | 214.48557142857143 | 0.5047142857142857 | 6624460159.934 | 198.51657142857144 | 0.34614285714285714 | 0.43960714285714286 | 1748283 | 446868 | 738592 | 920381 | 137.64728571428572 |
| llama2-7b | 8492252613.1398 | 306.5312 | 0.2491 | 5054308887.6915 | 176.707 | 0.6027 | 6313784600.8859 | 224.0448 | 0.4666 | 5512254103.1345 | 194.0564 | 0.3167 | 0.408775 | 2312084 | 701811 | 1189559 | 1351947 | 138.885025 |
| mistral-7b | 8959153207.0657 | 292.4959 | 0.3221 | 3843736940.608 | 118.4382 | 0.5984 | 4347391603.8823 | 136.4793 | 0.5322 | 5757130027.6119 | 182.3919 | 0.4009 | 0.4634 | 2017752 | 476609 | 617705 | 1104906 | 105.4243 |
| mixtral-8x7b | 148058972478.00333 | 252.368 | 0.35933333333333334 | 87464366821.55267 | 125.25866666666667 | 0.6013333333333334 | 114885144102.572 | 188.906 | 0.49666666666666665 | 104986877016.44867 | 175.658 | 0.4093333333333333 | 0.4666666666666667 | 242523 | 76767 | 142957 | 163916 | 104.3605 |
| orca2-13b | 20472223410.8879 | 625.5752 | 0.0245 | 13790271030.6872 | 414.31 | 0.6252 | 15214033255.1227 | 458.987 | 0.1166 | 15709322249.2406 | 475.3549 | 0.0879 | 0.21355 | 6112178 | 1574714 | 4039670 | 4354959 | 402.038025 |
| orca2-7b | 15138010530.5208 | 570.6399 | 0.0241 | 10866066666.8139 | 404.5928 | 0.5843 | 12822254518.9788 | 480.2021 | 0.0617 | 11644636439.9282 | 434.7639 | 0.2357 | 0.22645 | 5569100 | 1667142 | 4503611 | 3346329 | 377.15455 |
| phi-2.7b | 2052660640.5804 | 64.1359 | 0.2219 | 1192838313.5778 | 35.343 | 0.3225 | 1758810938.0609 | 54.0241 | 0.2928 | 1522030470.9613 | 46.4584 | 0.3396 | 0.2942 | 483938 | 187374 | 405970 | 303897 | 34.529475 |
| vicuna-13b | 8867362511.8793 | 260.3653 | 0.2687 | 3831699001.4209 | 103.2363 | 0.5368 | 4754472050.2115 | 131.705 | 0.4333 | 3429500807.9661 | 91.6197 | 0.4241 | 0.415725 | 1997074 | 418984 | 781284 | 545532 | 93.57185 |
What's next for OllaBench
- JUL2024 - White paper on OllaBench v.0.2 evaluation results of mainstream open-weight LLMs such as Llama3, Llama2, Orca2, Gemma, etc.
- DEC2024 - OllaBench v.0.3 release, providing datasets and benchmark scripts for evaluating LLMs’ ability to detect Cognitive Warfare manipulations in chat texts.
- JAN2025 - White paper on OllaBench v.0.3 evaluation results of mainstream open-weight LLMs
- FEB2025 - Release tutorials on how to customize OllaBench for any interdisciplinary evaluation purposes of LLMs.
- MAR2025 and forward - Running workshops on how to use OllaBench in various conferences, IEEE chapters, and university sponsored events.

Log in or sign up for Devpost to join the conversation.