-
-
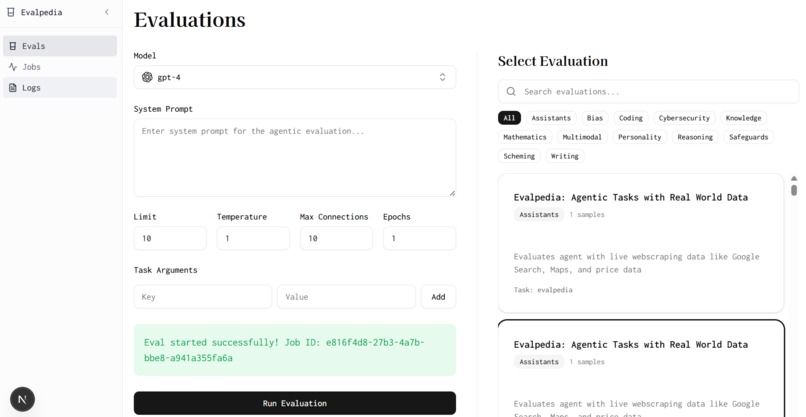
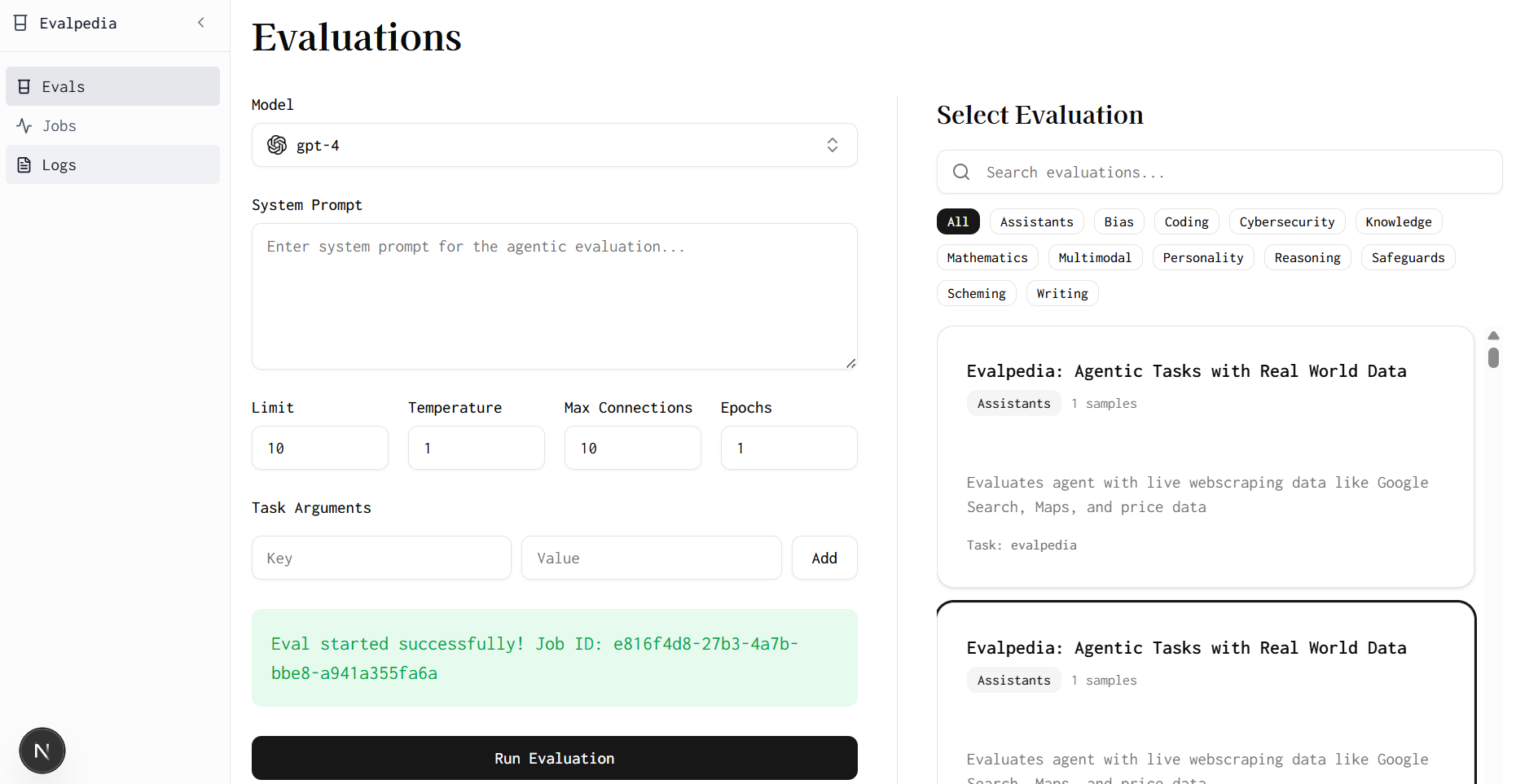
Schedule Evals
-
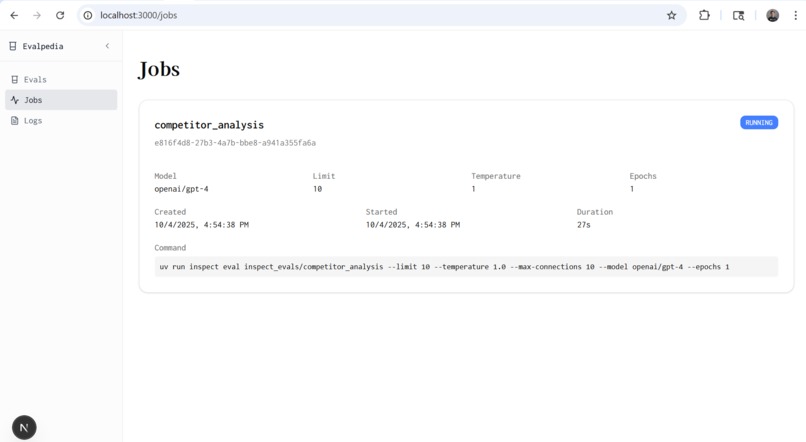
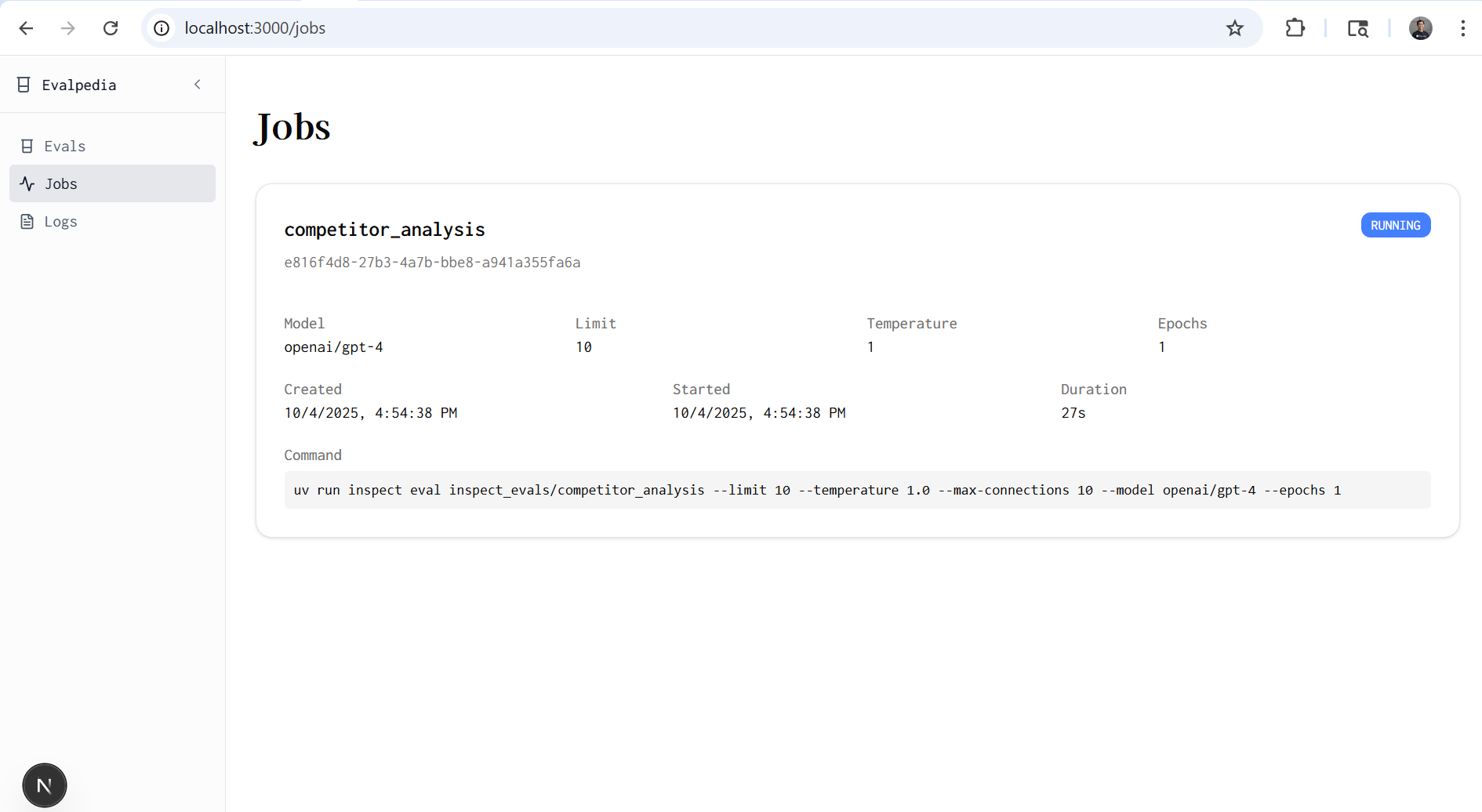
View Current and Past Jobs
-
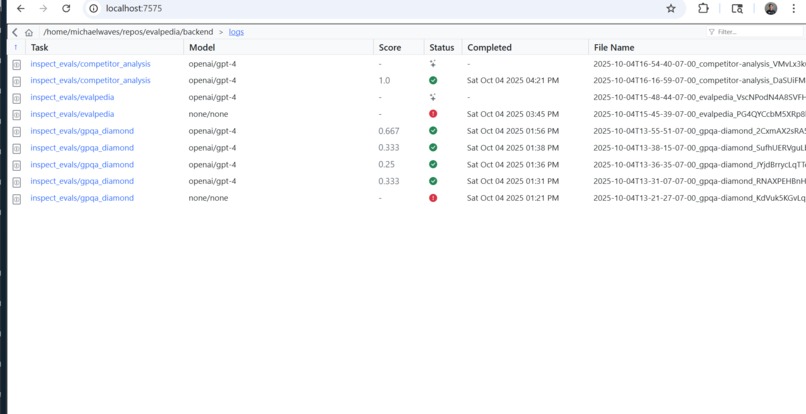
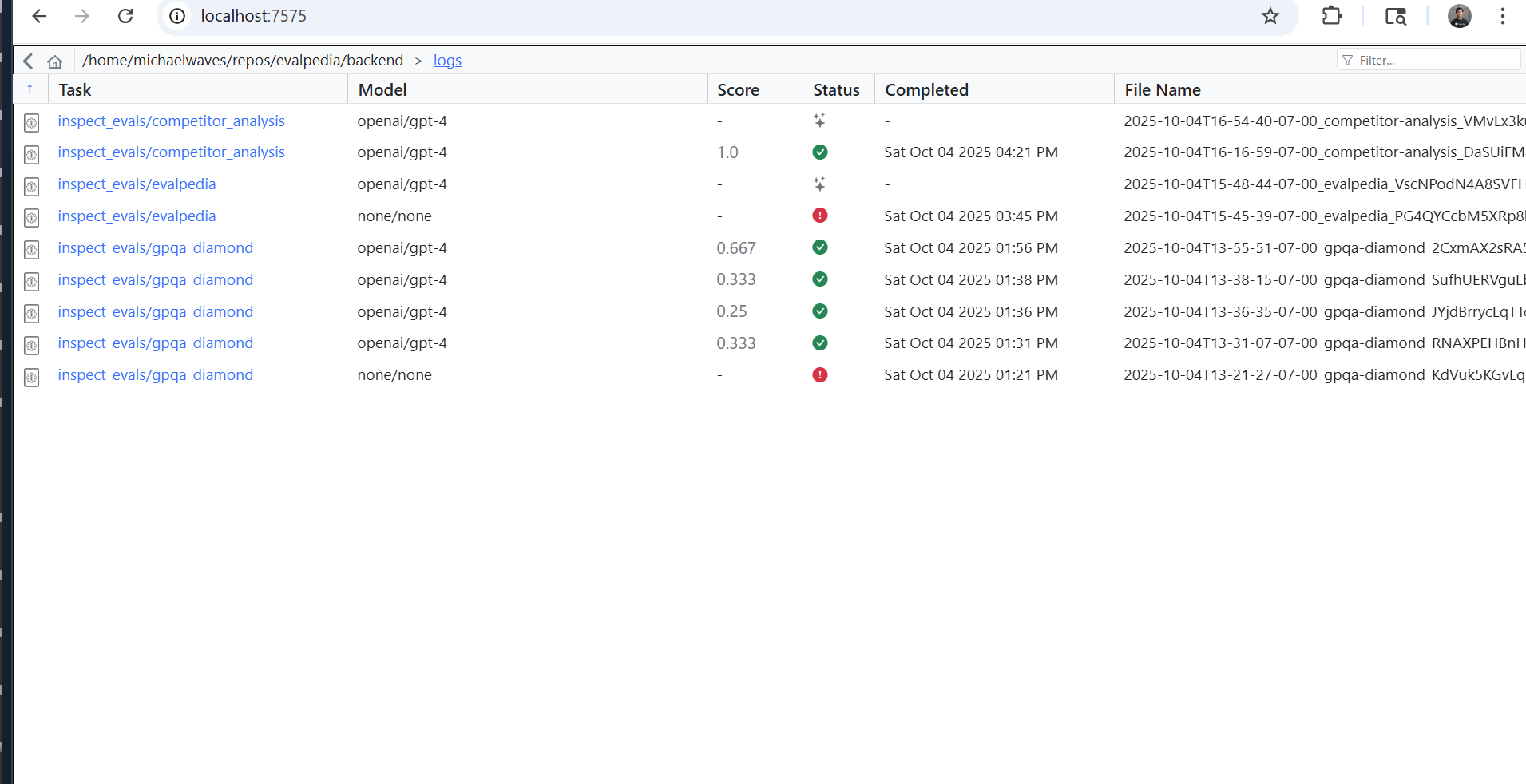
Manage Logs
-
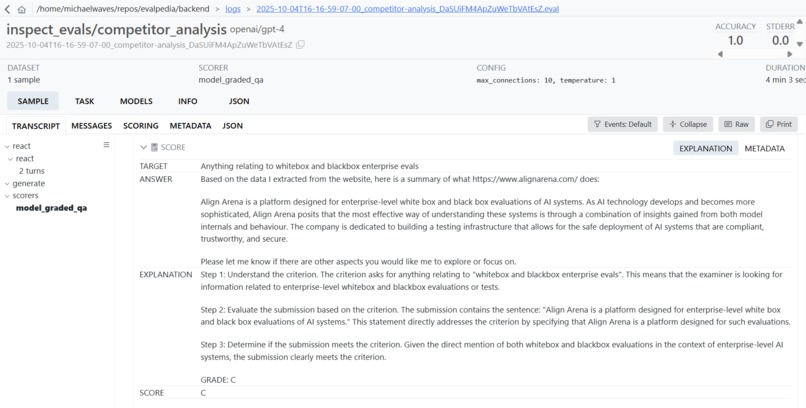
View Traces
-
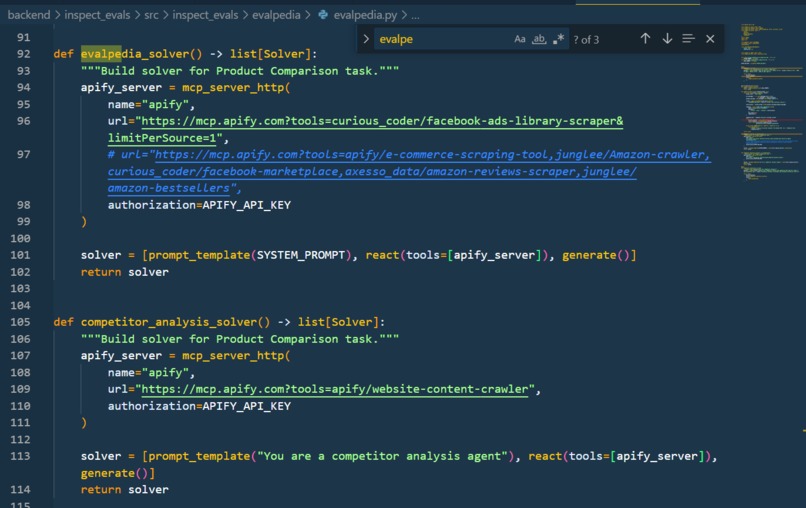
Apify MCPS Used
Inspiration
We were inspired by people telling us agents are unpredictable in production, especially when using tools and operating autonomously for long time periods. Agents often choose the wrong tools, are sensitive to system prompts, and hard to evaluate consistently. Existing tools like Langchain require lots of code and are difficult to setup, while platforms like MLFlow and Huggingface specialize in infrastructure for model weights and datasets instead of evals.
What it does
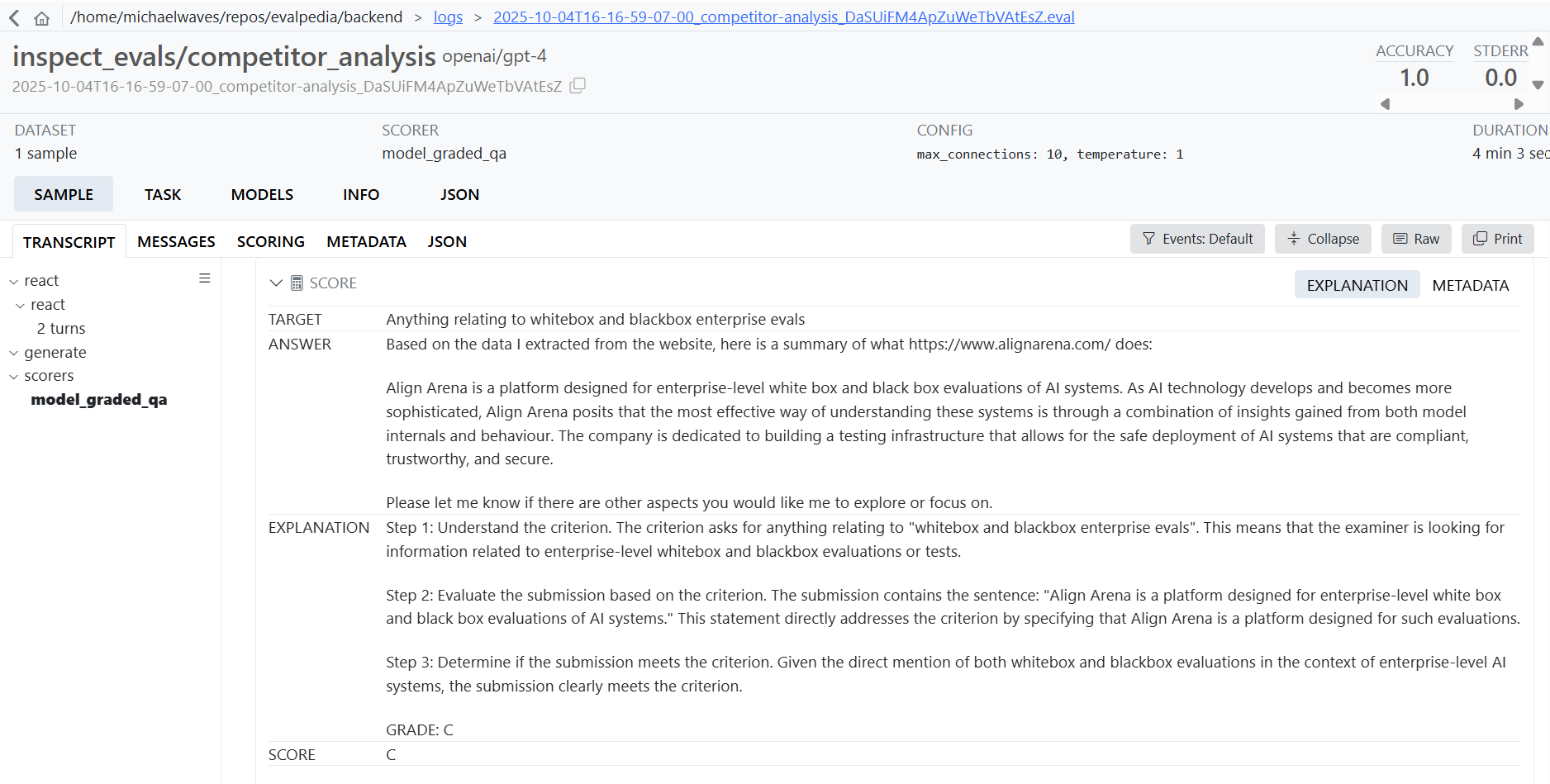
Select a model, write a system prompt, and choose an eval. Specify evaluation parameters like temperature, epochs, and number of samples, and run eval jobs. For example, one evaluation is finding the cheapest iphone 15 pro, and another is doing competitor webpage analysis. We use llm as judge to grade model performance. Once a job is done running, click logs to view detailed agent traces
How we built it
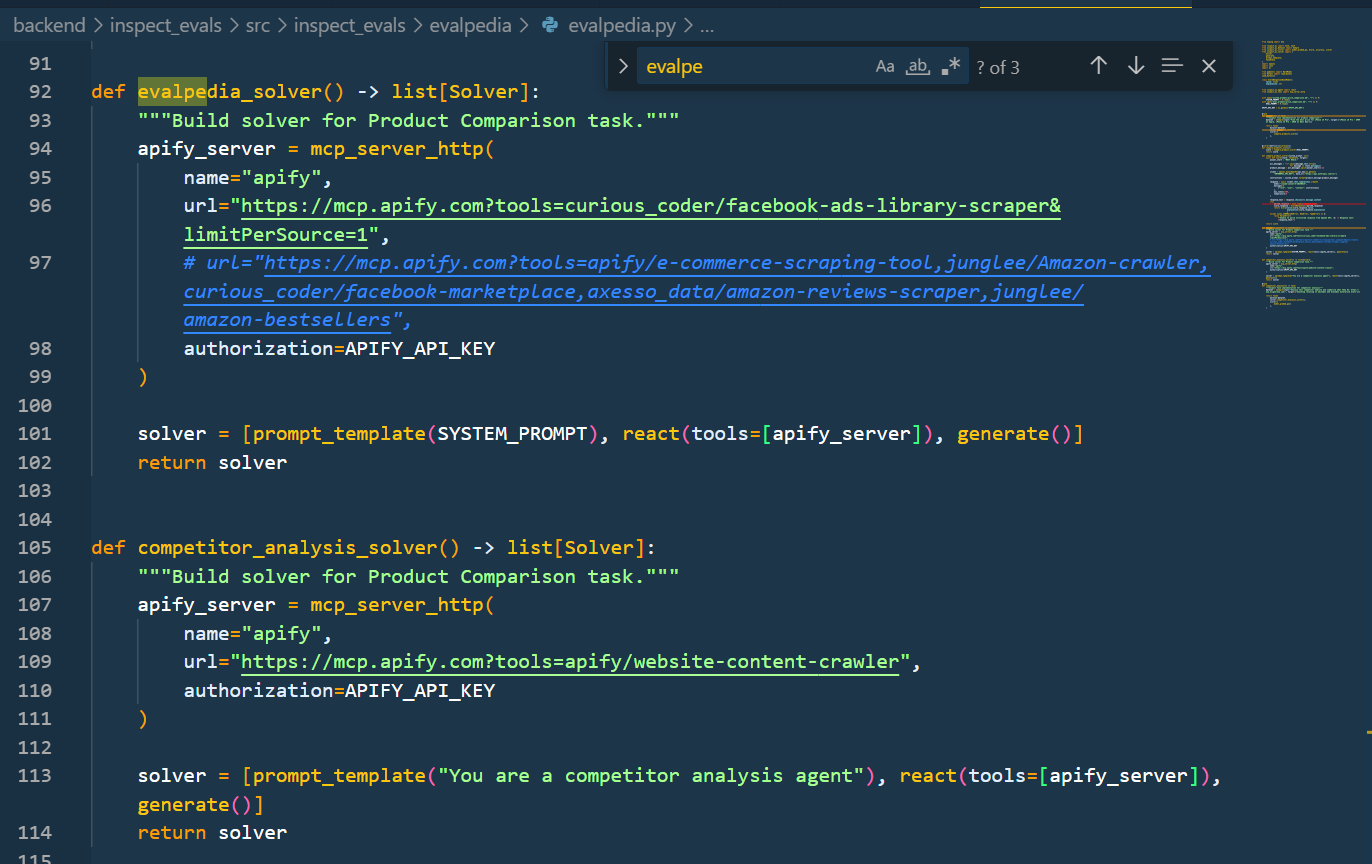
We used Apify actors to scrape Google, Facebook Marketplace, Amazon, and generic Website Content. The backend uses FastAPI with a task queue for long running evals and the frontend is nextjs 15.
Challenges we ran into
There were some issues with Apify Actors such as long timeouts, inconsistent API schemas, and inconsistent results.
Accomplishments that we're proud of
The frontend UI is cool, the jobs queue works, the log viewer is nice
What we learned
Evals are hard but cool
What's next for Evalpedia
Sell to OpenAI and raise $10M in VC money
Built With
- apify
- fastapi
- nextjs



Log in or sign up for Devpost to join the conversation.