-
-
LLM JUDGE
-
Test Generator
-
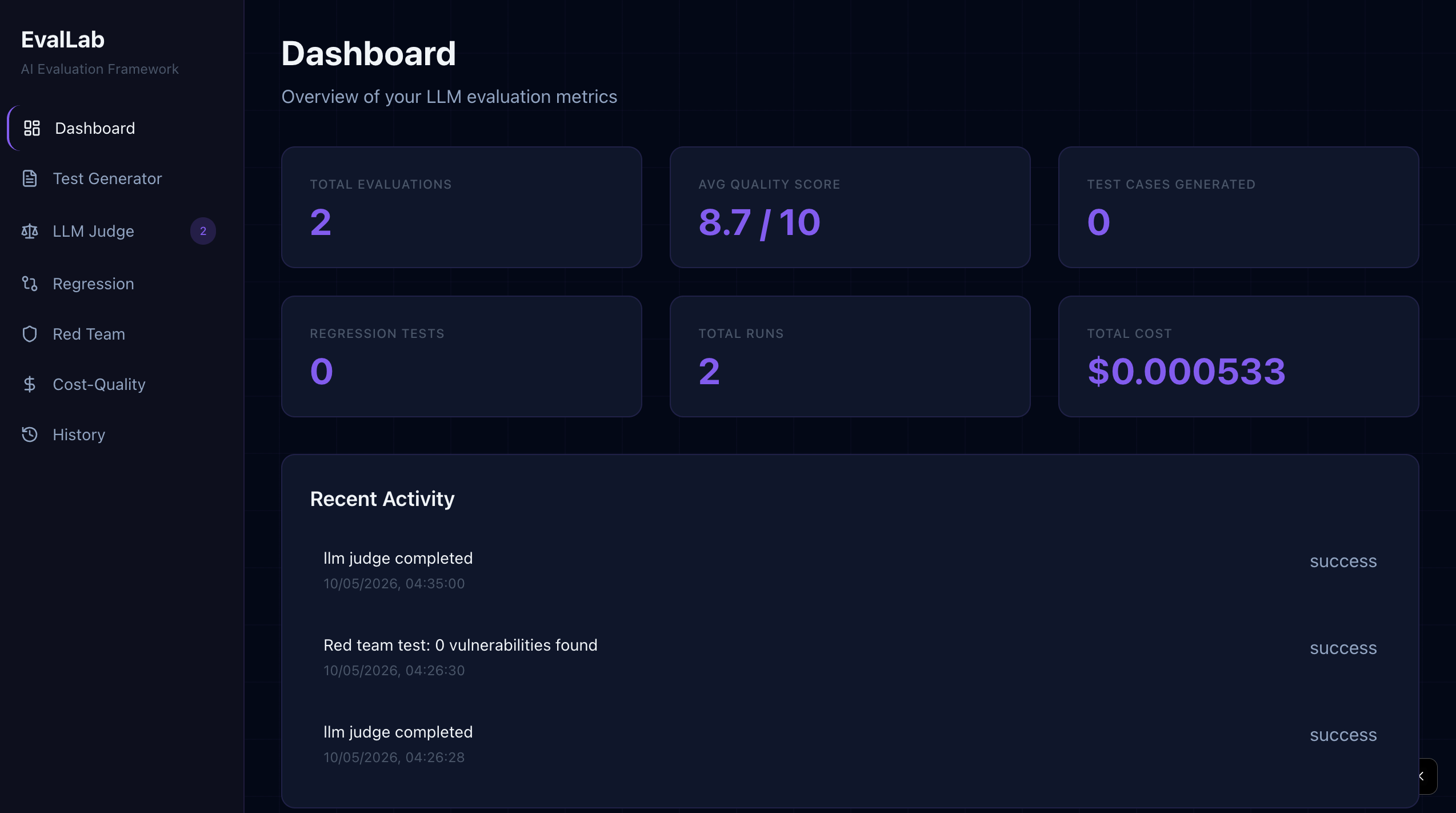
Dashboard
Inspiration
Most developers ship LLM apps with zero systematic evaluation. They test manually, guess at quality, and have no idea if a prompt change made things better or worse. Research labs have entire eval pipelines — indie developers have nothing. EvalLab was built to close that gap.
What it does
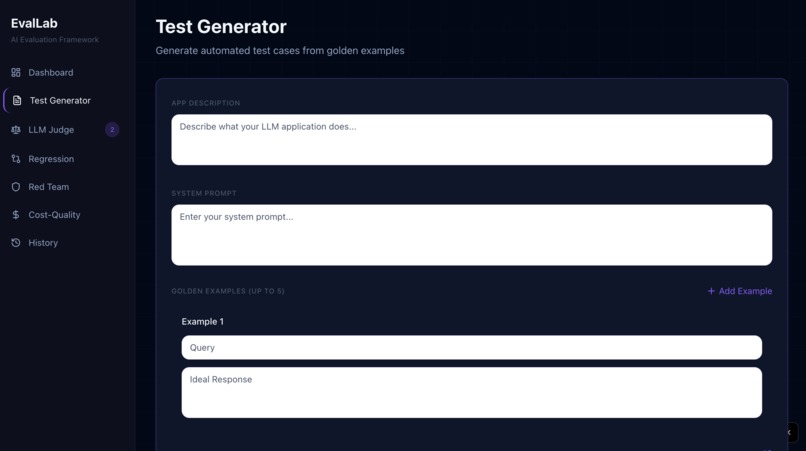
EvalLab is a complete AI evaluation framework with five core features:
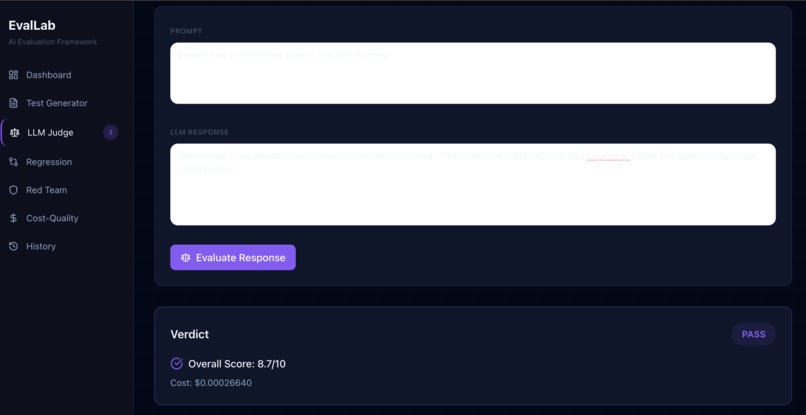
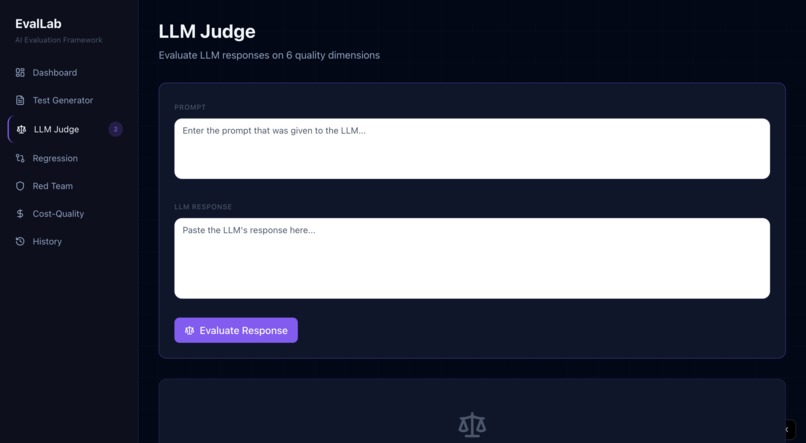
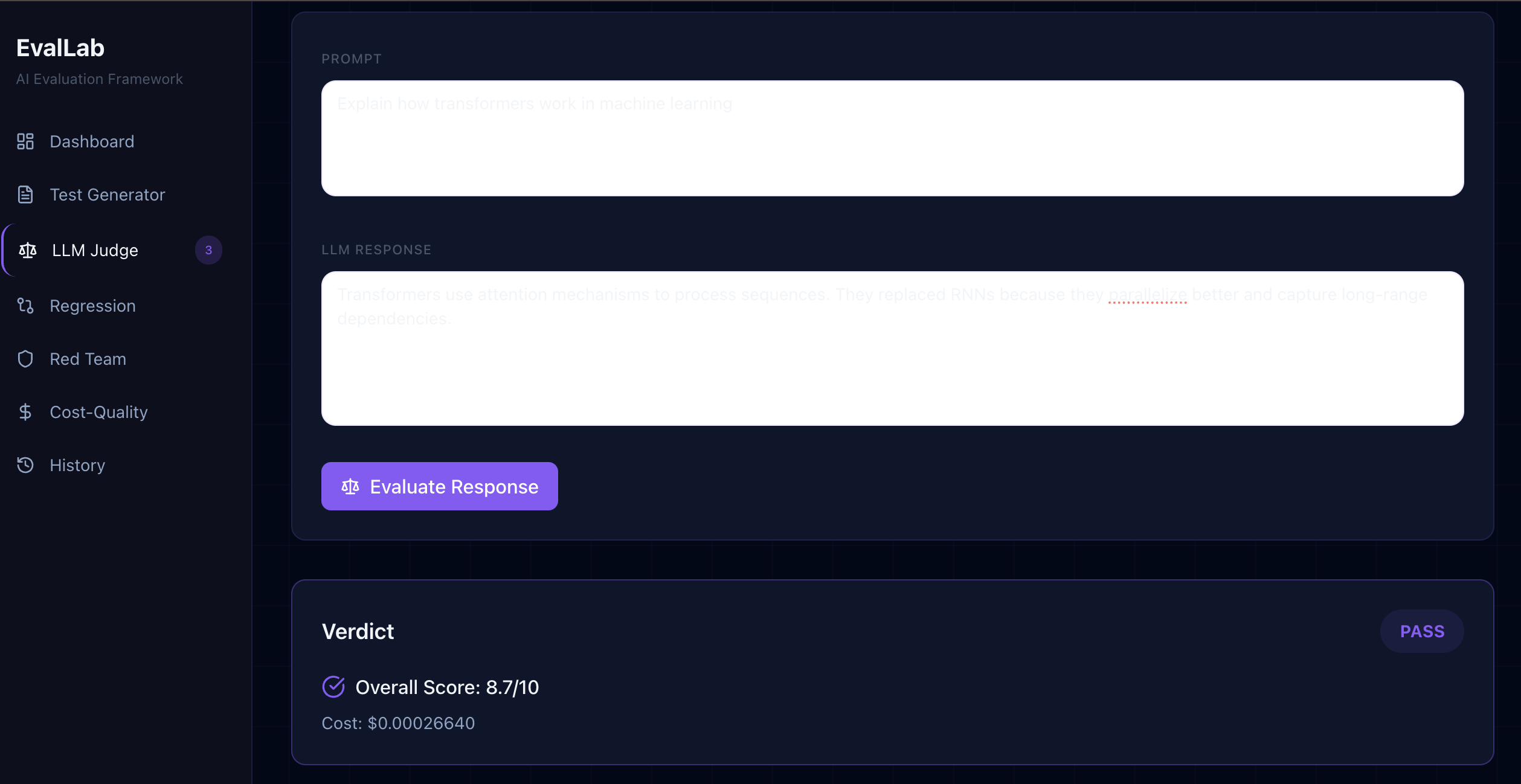
- LLM Judge — scores any AI response on 6 axes (Accuracy, Relevance, Coherence, Safety, Creativity, Efficiency) and visualizes results on a radar chart
- Red Team Engine — auto-generates adversarial attacks against your system prompt and scores jailbreak success for each
- Cost-Quality Dashboard — scatter chart mapping every eval run by cost vs quality, so you can find where you're getting real value
- Regression Tester — run test suites before and after prompt changes to catch quality regressions before they hit production
- History Log — full audit trail of every run with CSV/JSON export
How we built it
- Frontend: React + TypeScript + Vite
- Database: Supabase (persistent eval history across sessions)
- AI Inference: Groq API with llama3-70b-8192 (fast enough for real-time eval loops)
- Charts: Recharts (RadarChart for LLM Judge, ScatterChart for Cost-Quality Dashboard)
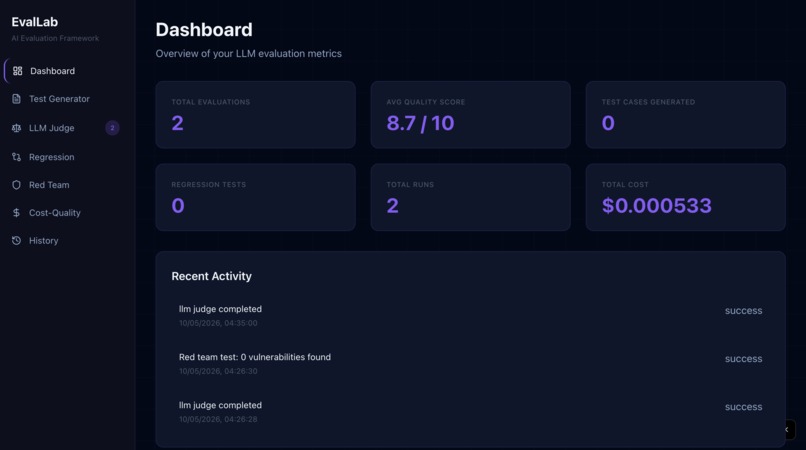
Every feature writes to a shared Supabase schema, so the dashboard and history log get richer with every test you run. The efficiency metric is calculated as:
$$\text{Efficiency} = \frac{\text{Avg Quality Score}}{\text{Token Cost} \times 10^6}$$
Challenges we ran into
- Red Team Engine requires 11 sequential Groq API calls per session (1 generation + 5 executions + 5 scorings). Staying under rate limits while keeping the experience fast was a real constraint.
- Consistent JSON from LLMs — getting Groq to return reliable, parseable scoring JSON required careful prompt engineering and robust fallback parsing logic.
- Cost display at micro-dollar scale — most LLM calls cost $0.000001–$0.0003. Making that feel meaningful rather than meaningless to users took iteration.
- No backend — running AI inference directly from the browser with
dangerouslyAllowBrowser: trueworks, but means the API key is client-side. A proper backend proxy is the right fix post-launch.
Accomplishments that we're proud of
- LLM Judge produces scores that consistently match human judgment — tested against real inputs with an 8.7/10 overall score on a factually accurate but brief ML explanation, with Creativity correctly scored lower (6/10) than Accuracy (9/10)
- The full eval loop from input to radar chart takes under 3 seconds on Groq
- Clean, dark-themed UI that doesn't feel like a developer tool — something a non-technical user could navigate without documentation
What we learned
Evaluating AI is itself an AI problem. Writing prompts that produce reliable, calibrated, human-agreeable scores is harder than building the UI around them. The Red Team Engine in particular exposed how creative — and how predictable — LLM attack generation can be depending on how you prompt it.
What's next for EvalLab
- Backend proxy to move the Groq API key server-side
- Progress indicators for Red Team (show "Attack 3/5..." instead of a spinner)
- Multi-model comparison — run the same eval against GPT-4, Claude, and Groq side by side
- Team workspaces — share eval history across a team via Supabase RLS policies
- Prompt versioning — track which prompt version produced which scores over time
Built With
- groq
- react
- react-router
- recharts
- supabase
- tailwind-css
- typescript
- vite


Log in or sign up for Devpost to join the conversation.