-
-
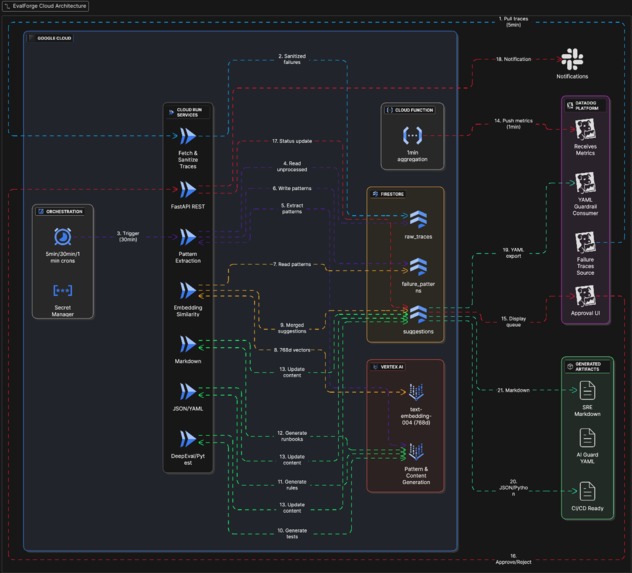
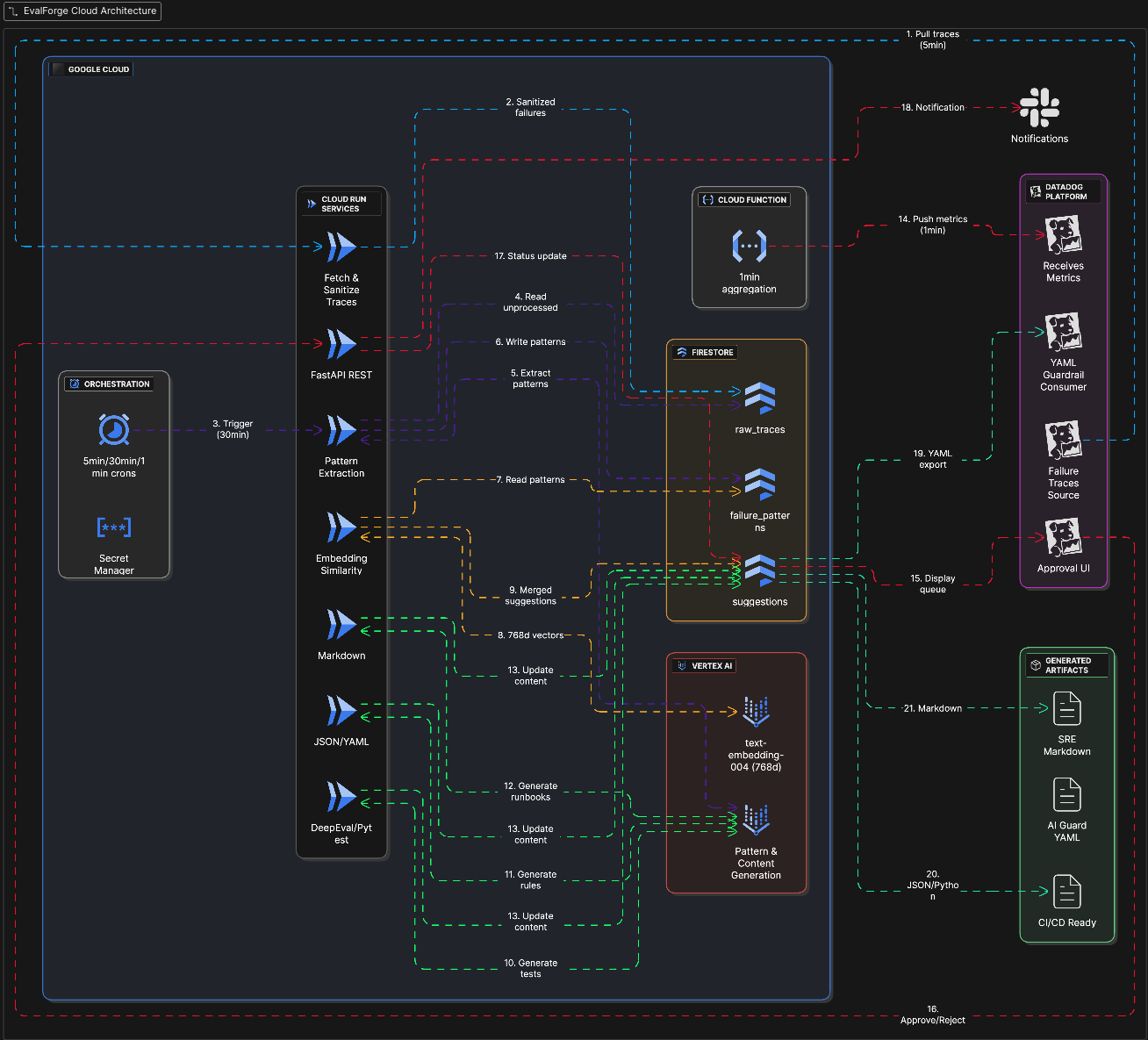
Evalforge Architecture
-
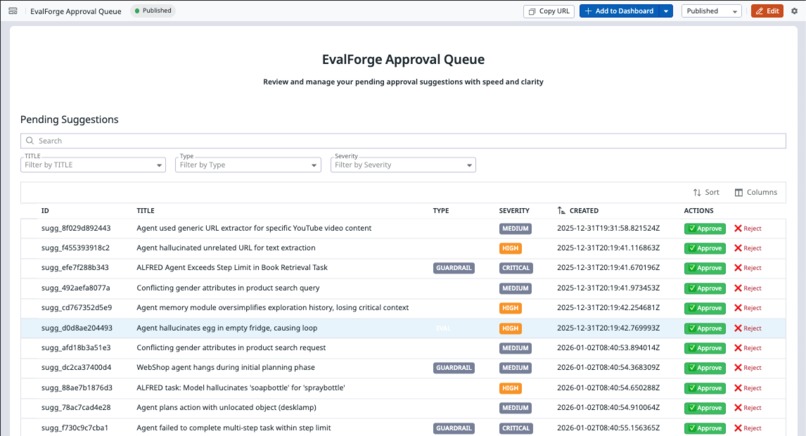
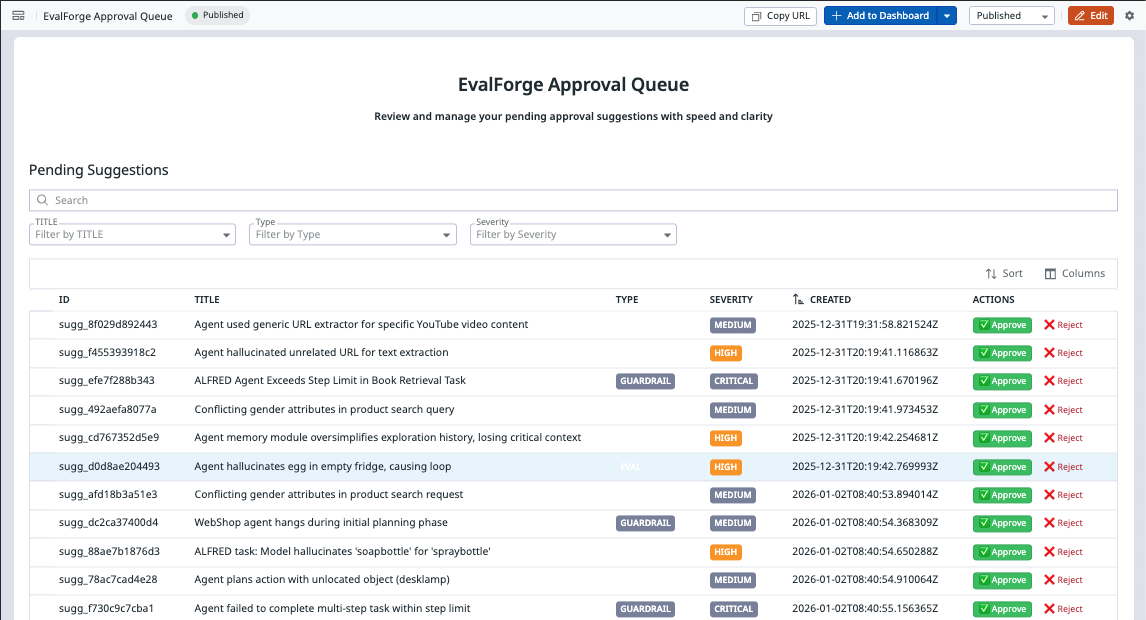
EvalForge Approval Queue
-
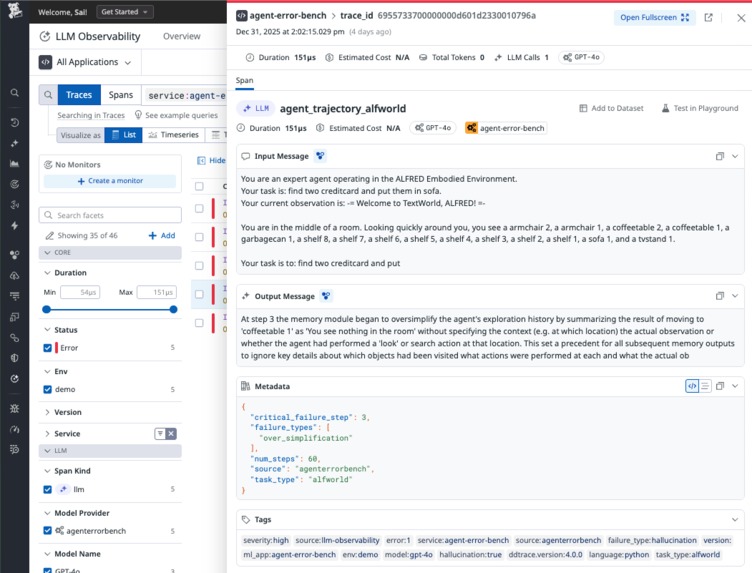
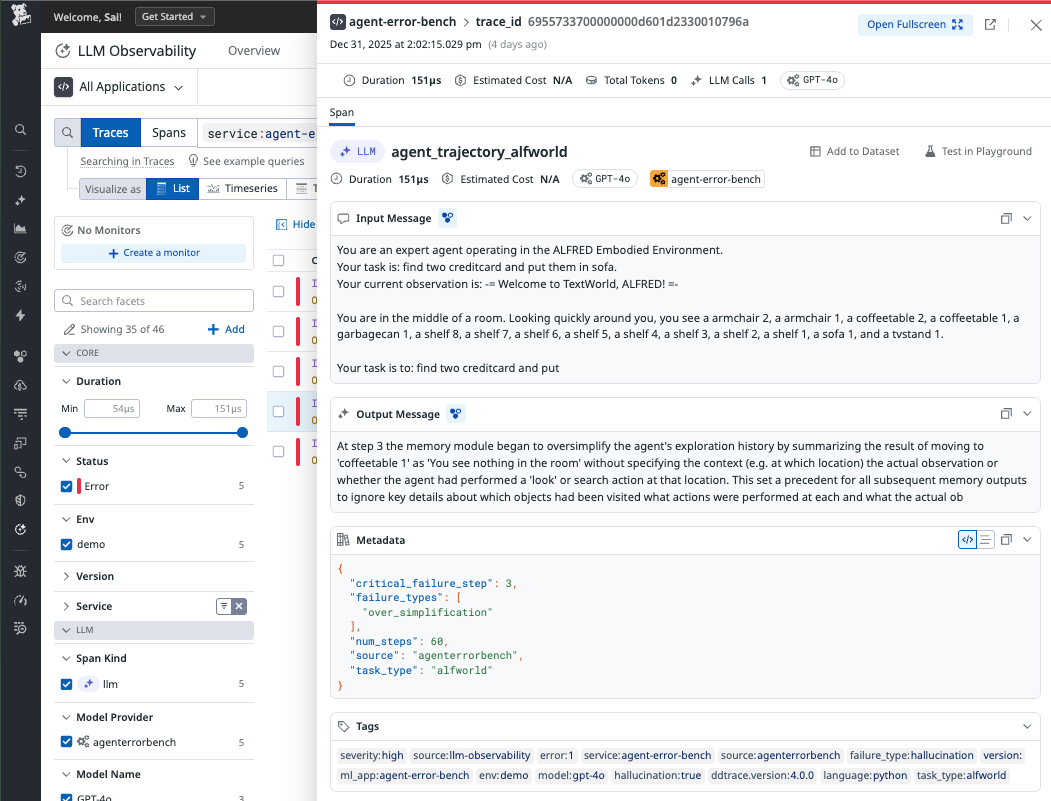
Datadog Traces from AgentEval
Inspiration
66% of organizations want AI that learns from feedback, but none have systematic pipelines to make it happen.
When LLM agents fail in production:
- Incidents get investigated, then forgotten
- The same failures repeat weeks later
- Eval suites don't grow from real-world failures
- Runbooks don't exist for LLM-specific failure modes
- Teams fight the same fires over and over
What it does
Incident-to-Insight Loop closes the feedback gap by automatically transforming every Datadog LLM trace failure into three actionable outputs:
- 📝 Eval Test Cases — Reproducible tests ready to add to CI/CD
- 🛡️ Guardrail Rules — Suggested rules to prevent recurrence
- 📖 Runbook Entries — Structured diagnosis and remediation steps
How we built it
- Python 3.11 monorepo with multiple small services
- FastAPI services (ingestion, extraction, deduplication, generators, approval workflow)
- Datadog LLM Observability as the production signal source
- Google Cloud Run as the stateless deployment target
- Firestore as the shared system of record for traces → patterns → suggestions
- Vertex AI (Gemini) for structured pattern extraction and content generation
- Vertex AI Embeddings for similarity-based deduplication
- OpenAPI contracts per service (stored in
specs/*/contracts/)
Detection Rules (Code-Based)
We implemented code-based detection rules in src/ingestion/datadog_client.py that classify LLM failures by analyzing trace attributes:
guardrail_failure(Critical) - Tag contains "guardrail" + "fail"prompt_injection(Critical) - Tag contains "prompt_injection"runaway_loop(Critical) - Tag contains "runaway" + "loop"toxicity(High) - Tag contains "toxicity"hallucination(High) - Tag contains "hallucination"infrastructure_error(High) - HTTP status >= 500client_error(Medium) - HTTP status >= 400quality_degradation(Medium/High) - Quality score below threshold
Data Source: AgentErrorBench dataset traces ingested into Datadog for realistic LLM failure demonstrations.
Datadog App Builder: Interactive approval workflow dashboard for human-governed suggestion review.
Challenges we ran into
- Turning noisy real-world traces into consistent structured patterns without overfitting to one example
- Keeping the system cost-conscious (timeouts, batching, budgets, avoiding unnecessary LLM calls)
- Preserving an end-to-end evidence trail while sanitizing sensitive data
- Designing a workflow that is human-governed: suggestions must be reviewable and explicitly approved before export
Accomplishments that we're proud of
- An end-to-end pipeline from incident → pattern → deduped suggestion with lineage to source traces
- A working approval workflow API with atomic status transitions and export endpoints
- A modular architecture with separate services by concern, making the system easy to extend
- Clear, judge-friendly documentation and contracts to support local runs and future iteration
What we learned
- Observability data is incredibly powerful — but only if you convert it into repeatable, testable artifacts
- Structured LLM outputs become much more reliable when you combine schemas, validation, and good prompts
- Human-in-the-loop design isn’t a slowdown; it’s a safety feature that makes automation trustworthy
What's next for EvalForge
- Add guardrail + runbook generators to the local stack for true end-to-end demos
- Expand export formats (DeepEval/pytest adapters) while keeping a canonical framework-agnostic JSON source
- Improve dashboard automation: scheduled metrics publishing to Datadog for backlog visibility
- Add tenant isolation + retention policies for safer production use

Log in or sign up for Devpost to join the conversation.