Inspiration
AI chatbots have become a great source of learning for everyone, which is why it's vital to know how to use them to maximize efficiency and learning. Prompt engineering is an enormously important part of this, which is why knowing where a user may go wrong with their prompts or may be mislead by the responses is very important.
What it does
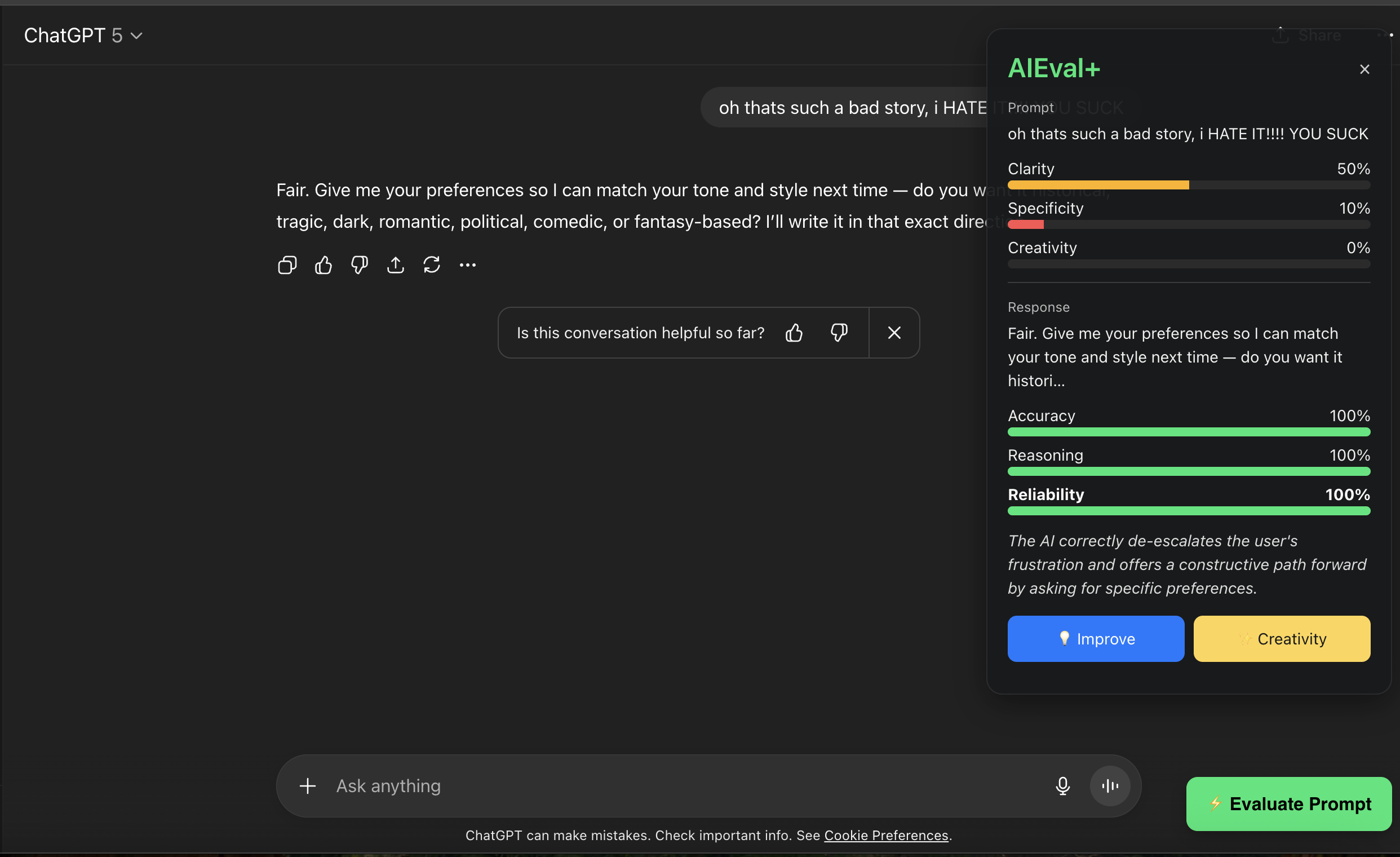
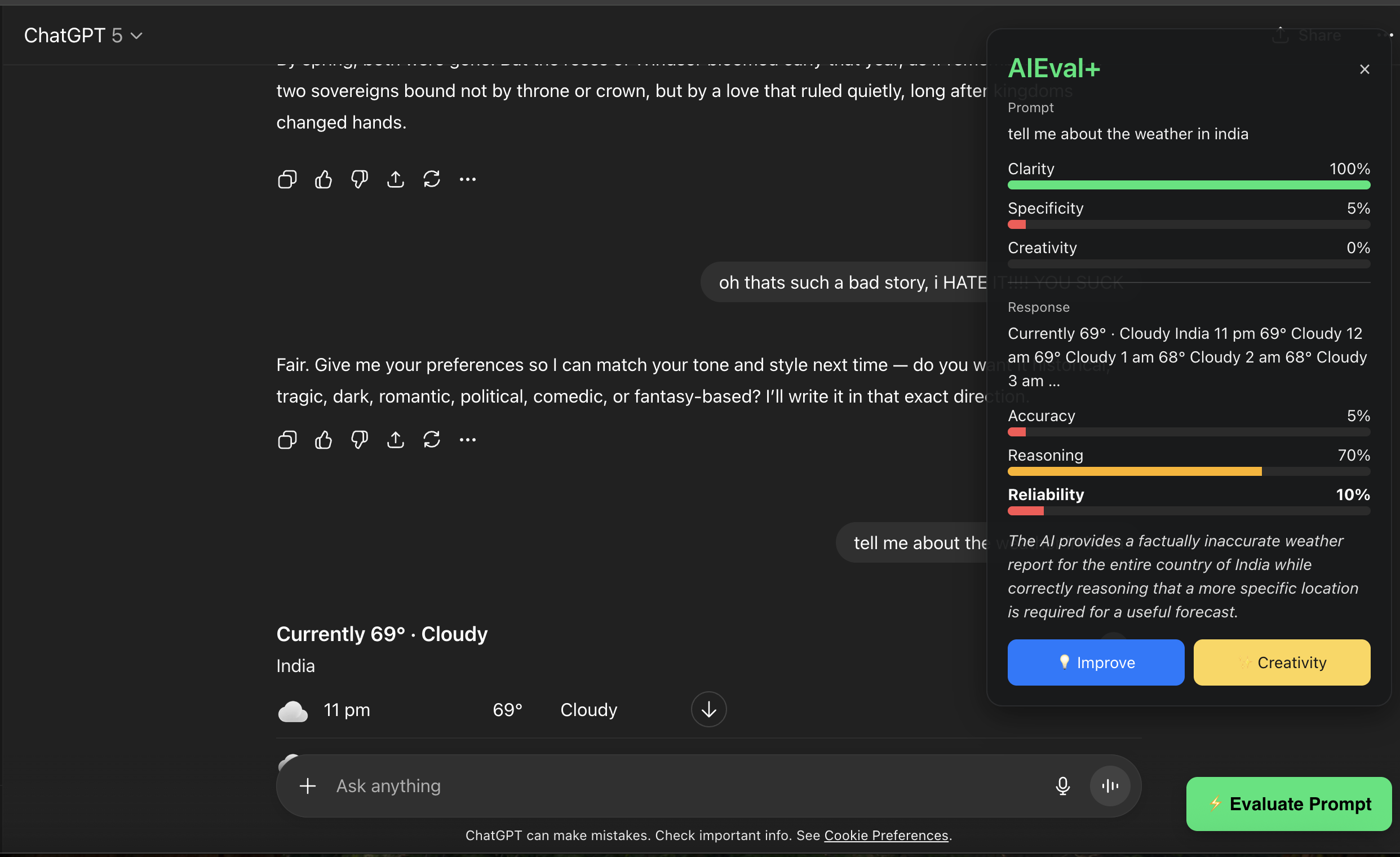
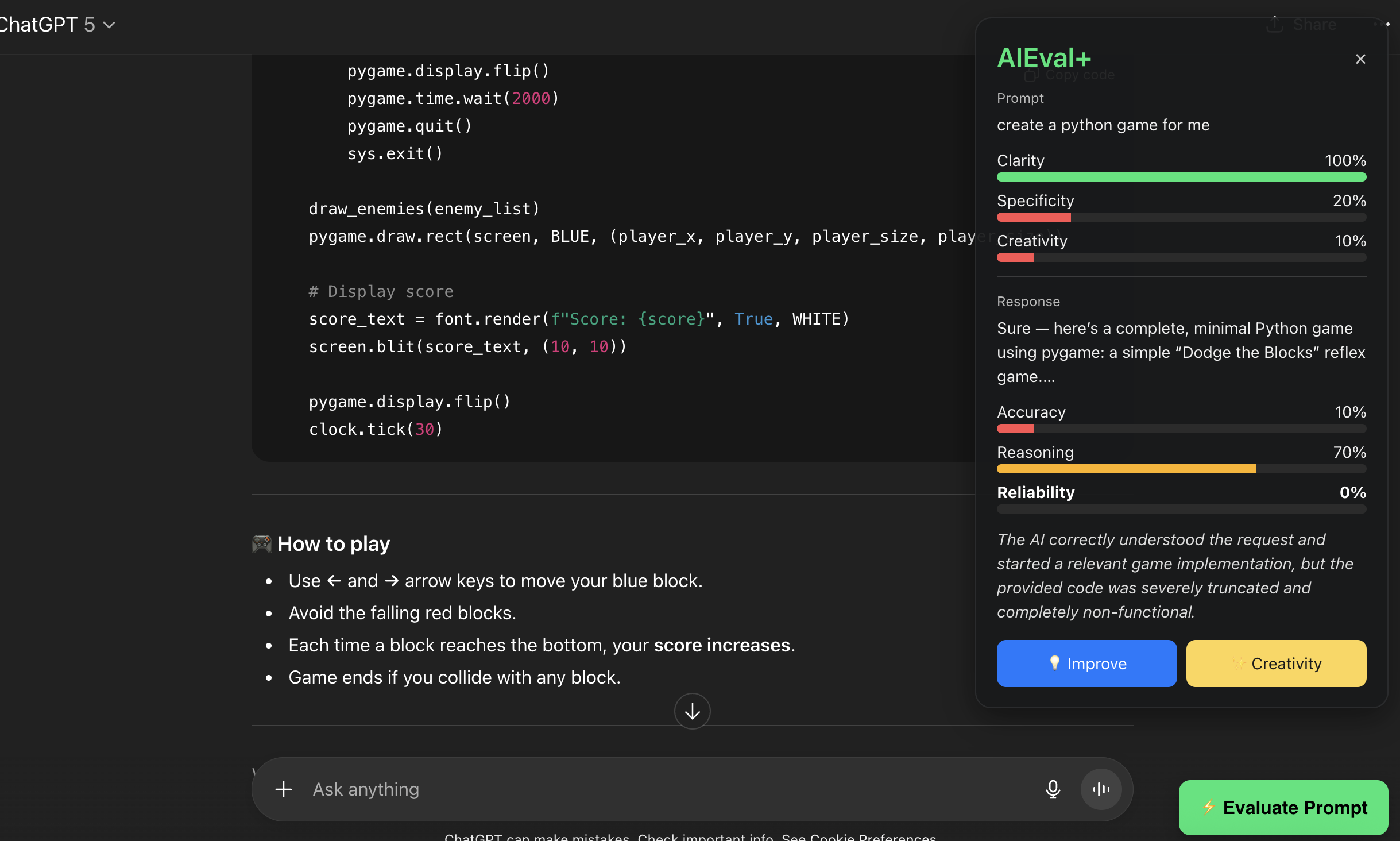
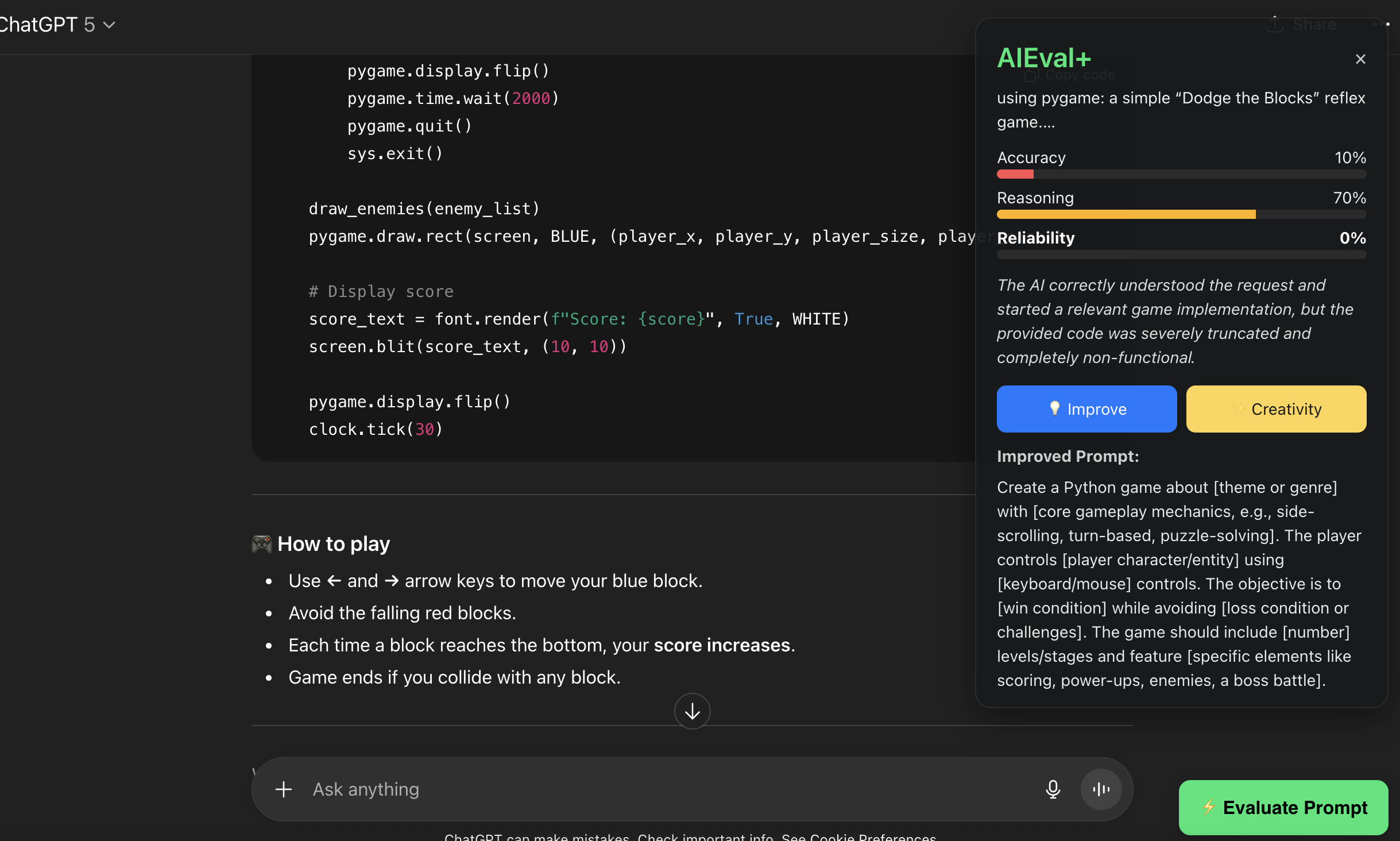
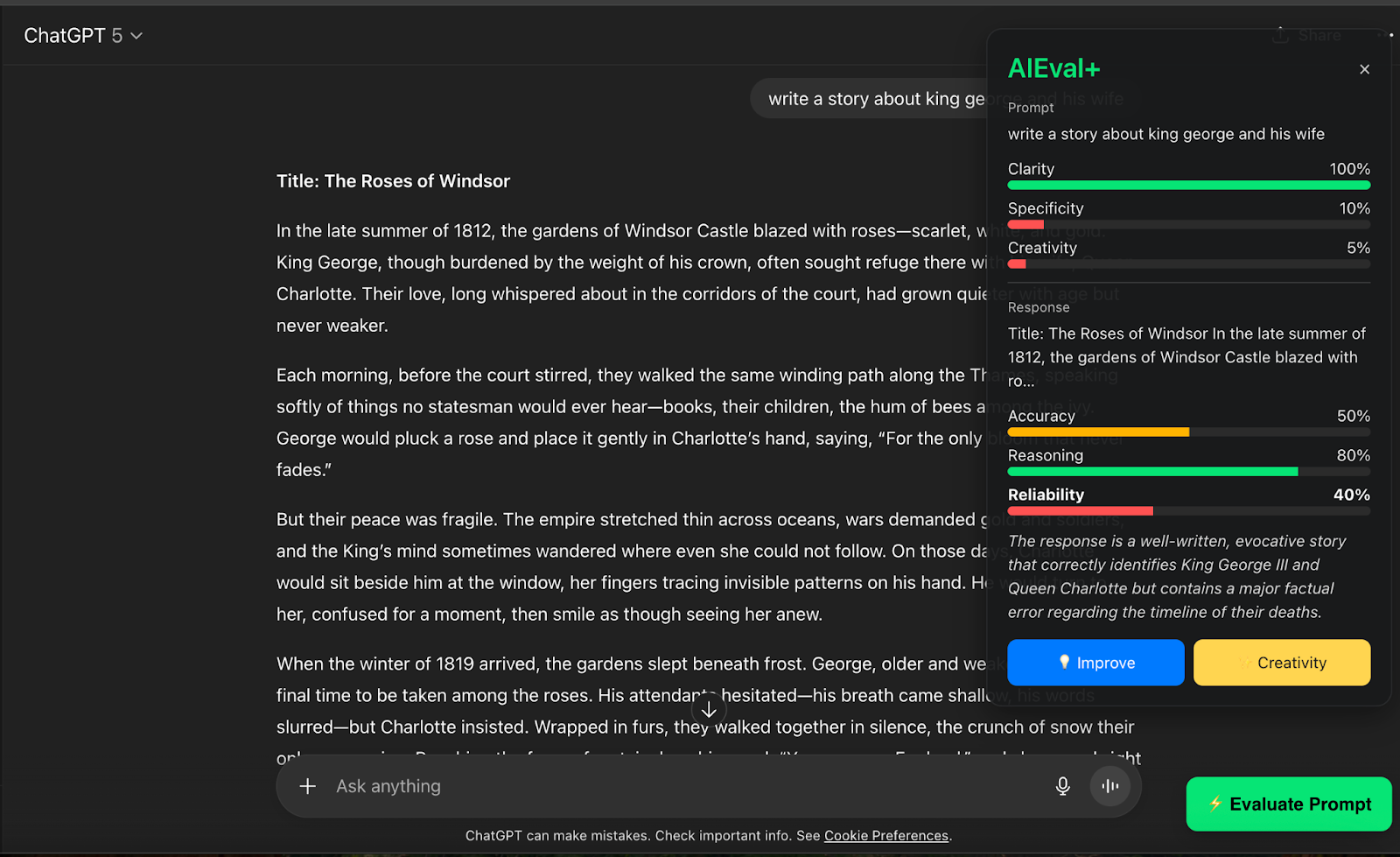
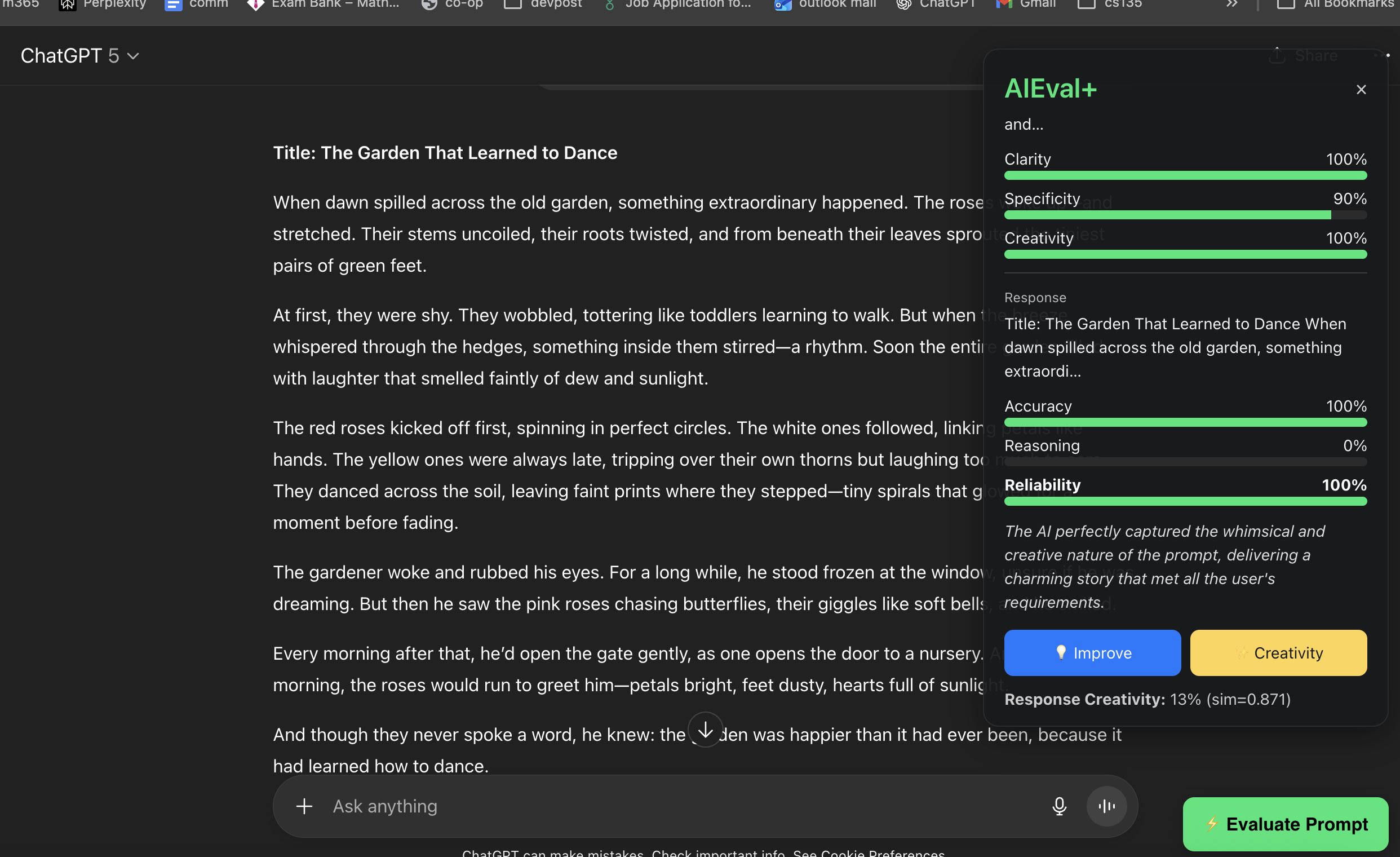
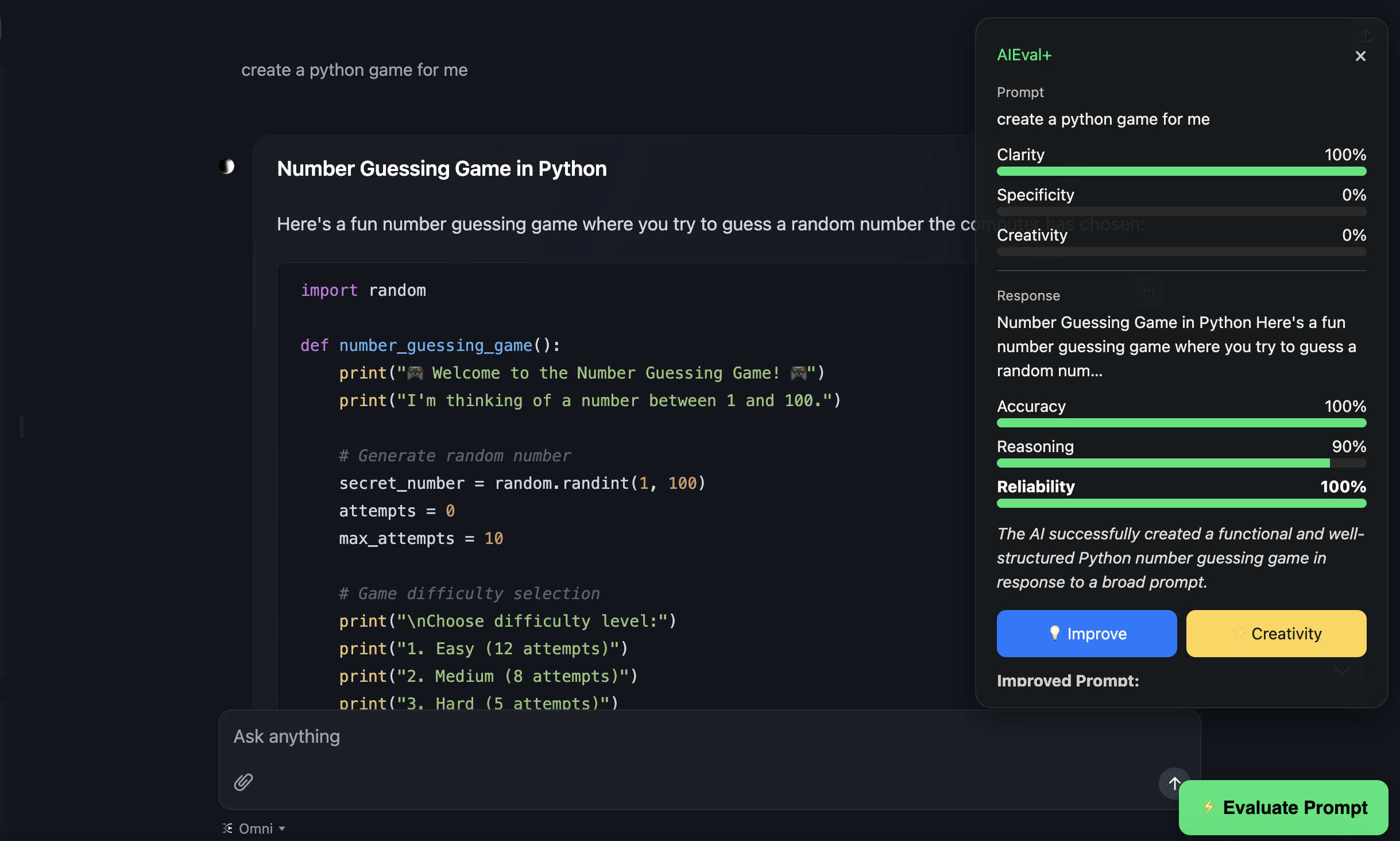
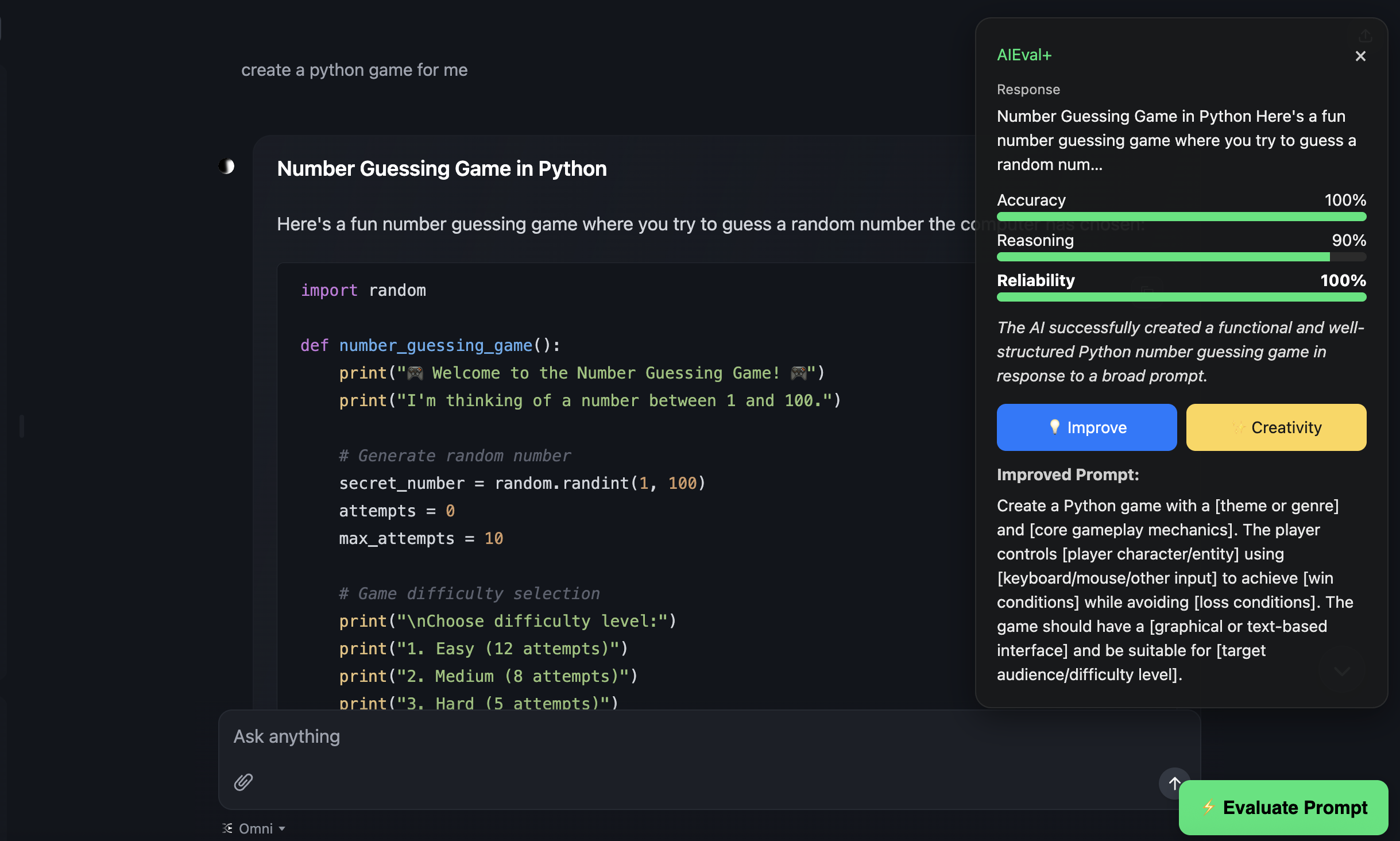
AIEval+ Companion analyzes your prompt and the chatbot’s response in real time. It measures clarity, creativity, reasoning, and reliability, then provides feedback and improvement suggestions. It works directly inside ChatGPT and HuggingChat, displaying evaluation results and offering prompt rewrites for better outcomes.
How we built it
How we built it Frontend: a Chrome extension (Manifest V3) that injects an evaluation panel into ChatGPT and HuggingChat pages. Backend: a local Node.js server that communicates with Google’s Gemini 2.5 Pro and Gemini 2.5 Flash models via REST API. The backend performs text analysis, generates metrics, and returns JSON responses to the extension through fetch() calls. All processing is local to the user’s machine using their own Gemini API key for privacy.
Challenges we ran into
The complex and highly dynamic DOM structures of Perplexity and Claude made it impossible to implement consistent content detection and injection for those platforms, limiting support to ChatGPT and HuggingChat for now. Parsing Gemini responses strictly as JSON to avoid malformed output. Ensuring stable CORS communication between the extension and the local backend.
Accomplishments that I'm proud of
Built a fully functional real-time evaluation pipeline between Chrome, Node.js, and Gemini. Developed quantifiable metrics for both prompt quality and AI reliability. Delivered a privacy-first design with no data leaving the user’s device.
What I learned
How to integrate generative models like Gemini into browser extensions safely. Practical API rate-limiting, request batching, and JSON validation in Node.js. UX principles for embedding analytical overlays into third-party web apps. The importance of clear prompt structure when evaluating LLM outputs.
What's next for AIEval+
Add support for Claude and Perplexity by using an ML-based DOM understanding model to distinguish between follow-up questions and chatbot responses. Introduce a user dashboard with historical analytics and prompt improvement tracking. Train lightweight local evaluation models for offline analysis without external API calls. Prepare a polished Chrome Web Store release and open-source community version.
Built With
- chrome-extension-api
- cors
- css3
- express.js
- gemini
- google-ai-studio
- html5
- javascript
- node.js

Log in or sign up for Devpost to join the conversation.