-
-
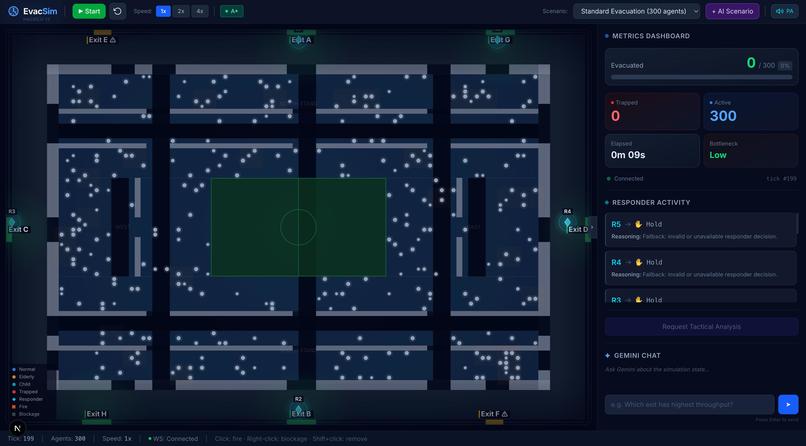
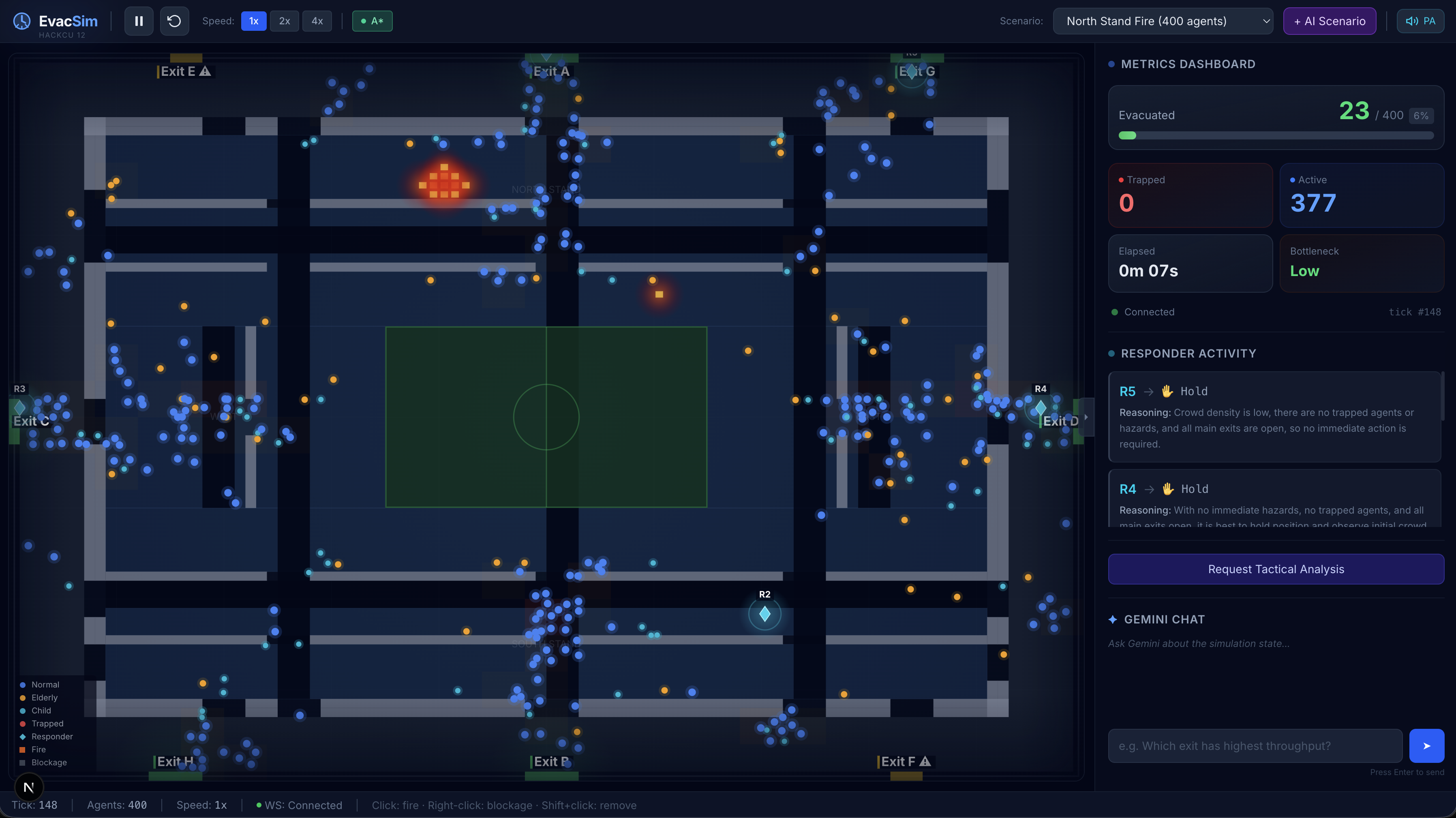
Initial state
-
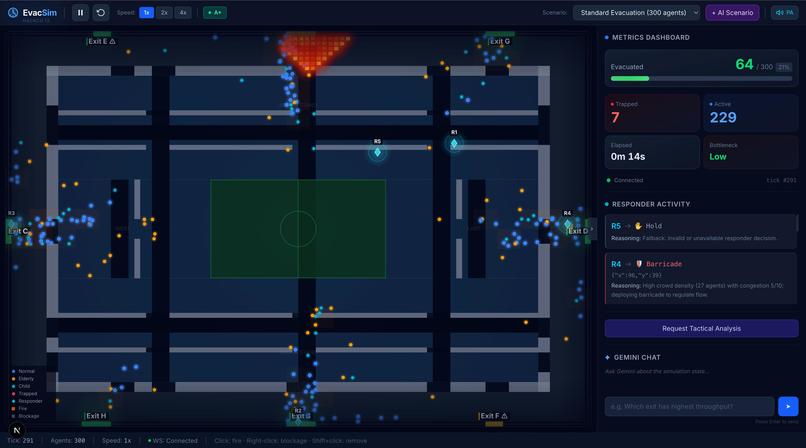
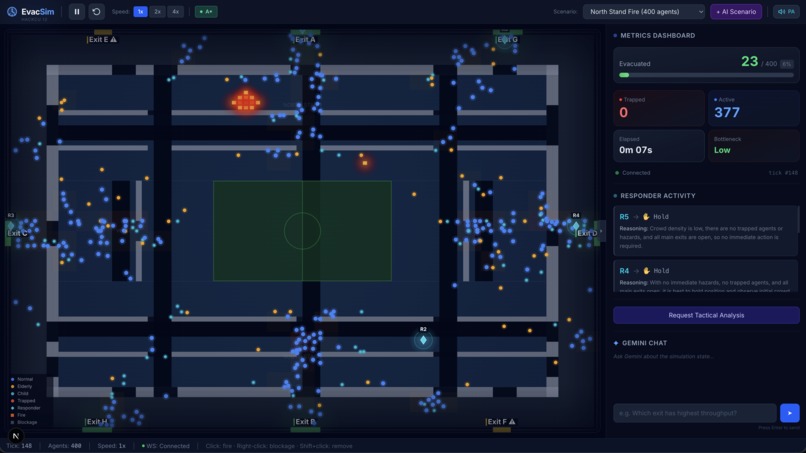
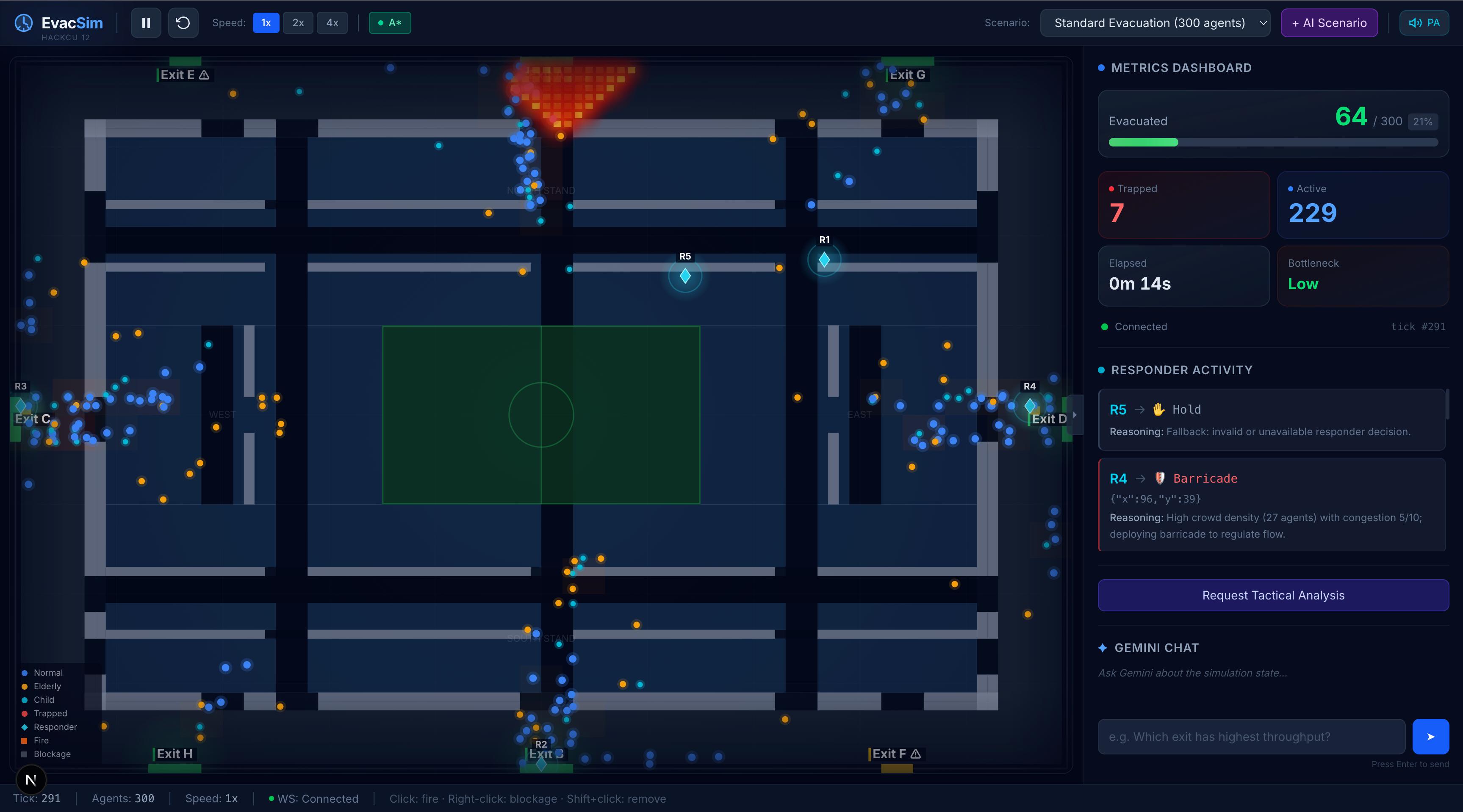
fire hazard started, Responder agents deploying barricades
-
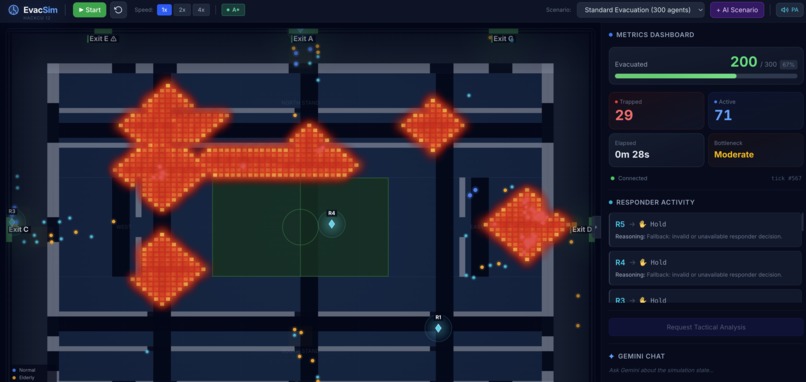
-
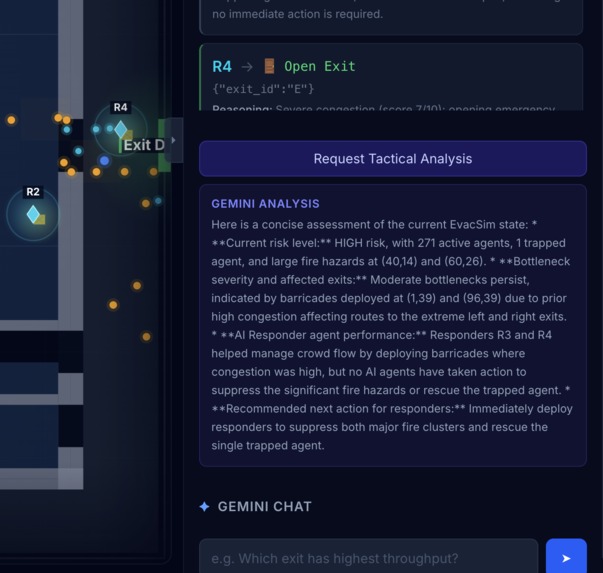
-
Inspiration
Between 1980 and 2022, at least 440 stampede incidents killed over 13,700 people and injured 27,000 more. The problem isn't slowing down - it's accelerating. In 2025 alone, 63 people died in a fire and stampede at a nightclub in Kocani, North Macedonia; 25 were killed in a nightclub fire in Goa, India. The 2022 Itaewon crowd crush in Seoul killed 159. The 2013 Kiss nightclub fire in Brazil killed 242. Nightclubs, stadiums, concert venues - anywhere large crowds meet limited exits, the same failure mode repeats: responders can't see the bottlenecks forming, exits get blocked, and evacuation plans are static PDFs that were drawn months before the event.
We asked: what if emergency responders had AI co-pilots? Not dashboards to look at after the fact - autonomous agents that observe a crowd in real time, reason about what's going wrong, and take action before the crush happens.
The 2026 FIFA World Cup gave us the perfect scenario. Stadiums with tens of thousands of fans. Multiple exits. Fire, structural collapse, blocked corridors. Limited time. We built EvacSim to simulate exactly that - and to prove that AI responders can materially improve evacuation outcomes.
What it does
EvacSim is a real-time digital twin of a World Cup stadium running a two-tier agent system:
Tier 1 - The Crowd (200–500 agents, algorithmic)
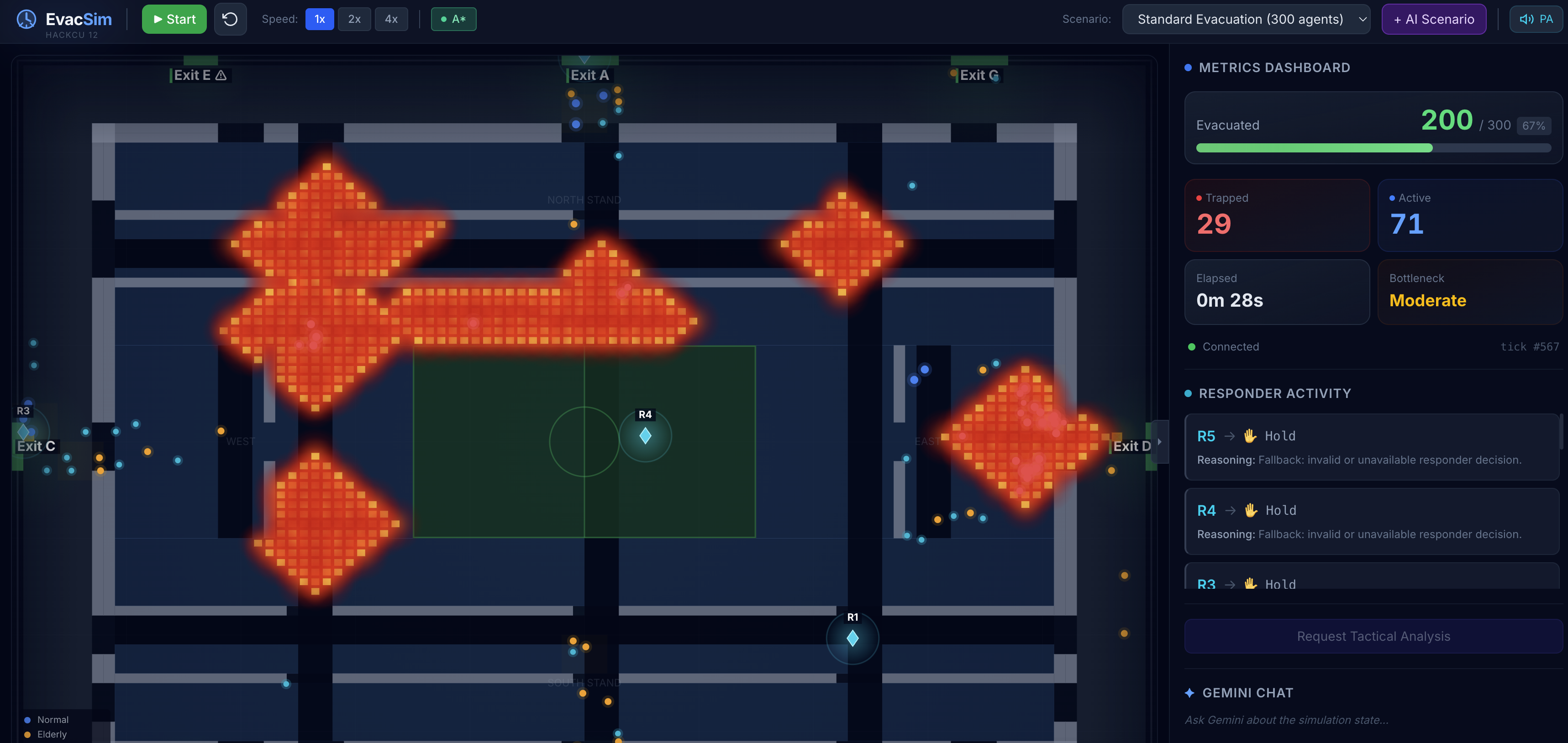
Lightweight particles following Dijkstra-based flow fields. Each cell in the stadium grid stores a direction vector pointing toward the nearest safe exit. Agents sample their cell's vector every tick - (O(1)) per agent - and combine it with separation and jitter forces for realistic crowd behavior. Fire cells carry a cost penalty of 500, so agents naturally route around danger without being explicitly told to. Agents stuck for 50+ ticks get A* fallback pathfinding to escape corners the flow field can't resolve. Agents caught directly in fire are immediately trapped.
Tier 2 - The Responders (5–10 agents, Gemini-powered)
This is what makes EvacSim more than a physics sim. Every ~3 seconds, each Responder agent:
- Observes its local sector - crowd density, trapped agents, nearby fires, exit status
- Decides by calling Gemini Flash with its observation and available actions
- Acts on the simulation grid - and hundreds of crowd agents change direction as a result
Available actions:
- Redirect flow - Penalize a congested exit's weight, boost an underused one. The flow field recomputes and the crowd pivots.
- Open emergency exit - Unlock an exit that's normally closed, creating a new escape route.
- Deploy barricade - Place a physical barrier to keep the crowd away from a hazard zone.
- Hold position - The sector is under control; no action needed.
Responders spread across the stadium using nearest-available bottleneck assignment - they never all rush to the same exit. They're aware of each other's recent actions (passed as context to Gemini) to avoid contradictory decisions.
Interactive chaos
Judges can inject disasters mid-simulation - click to drop fire, right-click to add a blockage, shift-click to remove obstacles. The crowd reroutes. The responders adapt. A dual-voice ElevenLabs PA system narrates it all: a male PA voice for stadium announcements, a female narrator calling out every responder decision in real time. Every run is saved to MongoDB Atlas for comparison.
How we built it
Architecture
The backend is a headless game server - a Python FastAPI app running a fixed-timestep simulation at 20 ticks/second. The tick loop is pure computation: no await, no I/O, no API calls. Agent updates, pathfinding, collision detection, and metric computation all happen synchronously within the tick. After each tick, the state is serialized to JSON and broadcast via WebSocket.
The frontend is a Next.js 14 app with a critical performance constraint: agent positions never touch React state. WebSocket payloads are written to a mutable useRef - the "state buffer" - bypassing React's virtual DOM entirely. A standalone requestAnimationFrame loop reads from the ref and draws to an HTML5 Canvas. We lerp (linearly interpolate) between server ticks to produce smooth 60fps animation from 20fps data:
$$\text{rendered_pos} = \text{prev_pos} + (\text{curr_pos} - \text{prev_pos}) \times t$$
where (t) is the interpolation factor between the last two server ticks.
Pathfinding at scale
Individual A* per agent is (O(V \log V)) per agent per tick. With 500 agents, that's 500 pathfinding calls every 50ms - unacceptable. Instead, we compute one Dijkstra flow field per exit over a 100×80 numpy grid. Each cell stores a 2D direction vector pointing toward the lowest-cost neighbor. Agents sample their cell in (O(1)). Flow fields only recompute when the grid changes (grid.dirty = True), so the amortized cost is near-zero between obstacle events.
Spatial hashing keeps neighbor lookups at (O(1)) amortized instead of (O(N^2)). The stadium is divided into buckets; agents only check for neighbors in their own + adjacent buckets.
Gemini API - 5 integration points, one autonomous agent system
Most hackathon projects use an LLM to describe what's happening. EvacSim uses Gemini to decide what happens next. The responder's decision physically changes the simulation grid - flow field weights shift, exits unlock, barricades appear - and 200–500 crowd agents immediately respond to the new environment. Gemini isn't a chatbot sidebar. It's the brain of an autonomous multi-agent system.
Why Gemini specifically: Flash's low latency (~1–2s) makes it viable for real-time decisions inside a simulation running at 20 ticks/second. The response_mime_type="application/json" flag gives us reliable structured output without regex hacks - critical when one bad parse would crash the sim. We call all 5 responders in parallel via asyncio.gather (~1.7 calls/sec), well within rate limits.
Five integration points:
- Responder Agent Brain (primary) - Each of 5–10 responders calls
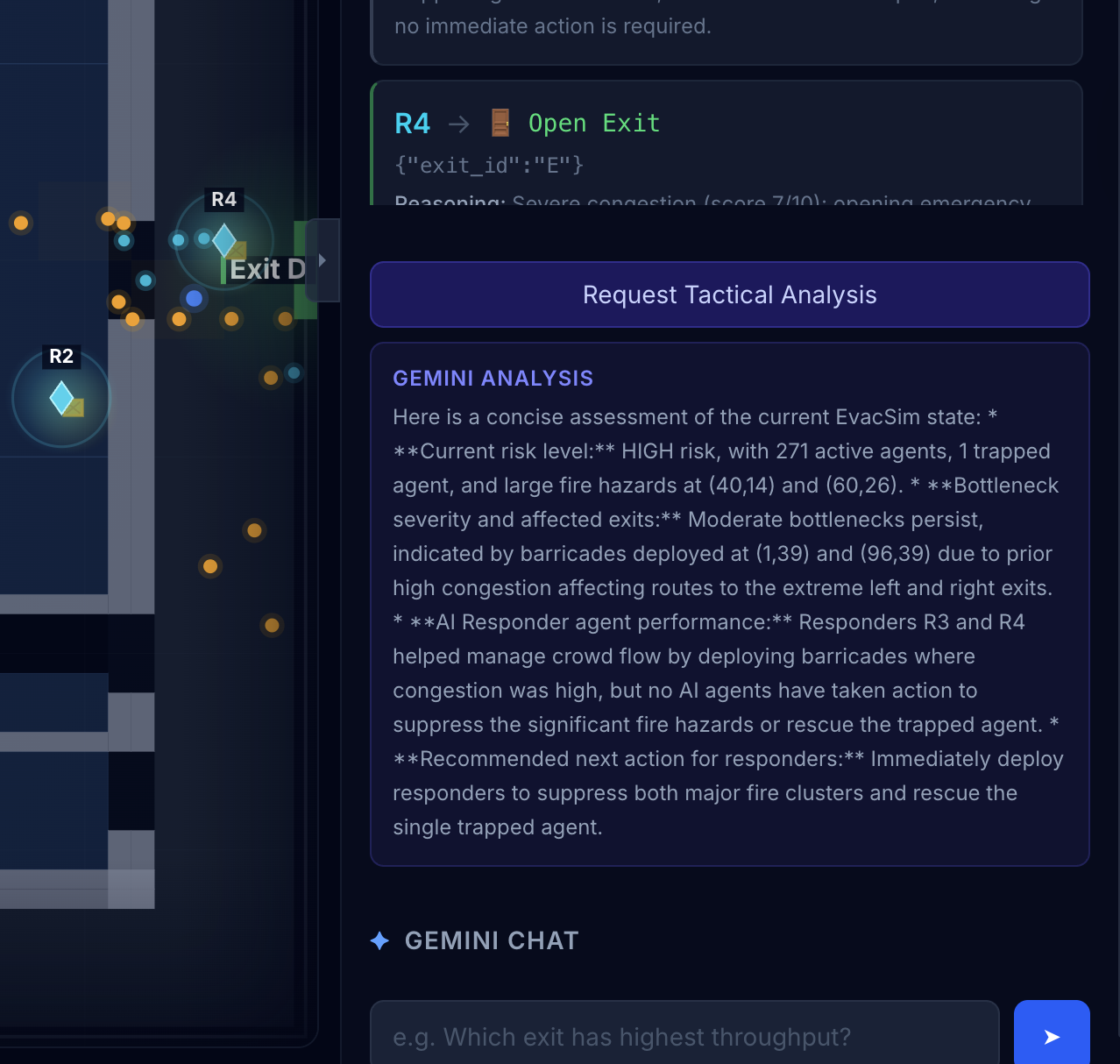
gemini-2.5-flashevery ~3 seconds with a structured observation of its local sector. Gemini returns a JSON action (redirect_flow,open_emergency_exit,deploy_barricade,hold_position) with reasoning. The action directly mutates the simulation grid, causing hundreds of crowd agents to physically reroute. Responders are aware of each other's recent actions (passed as context) to avoid contradictions. - Tactical Analyst - Periodic assessment of overall evacuation state, including evaluation of responder performance ("Responder 2's redirect reduced bottleneck severity by 40%").
- Natural Language Query - Chat interface. "Why did Responder 3 redirect traffic?" gets a contextual answer referencing live simulation data and the responder decision log.
- Scenario Generator - Describe a disaster in plain English → get back a structured JSON scenario with timed events. Uses
response_mime_type="application/json"for reliable parsing. - Post-Run Report - After-action review using
gemini-2.5-prothat grades each responder's decisions and analyzes bottleneck causes.
Responder hardening (the anti-crash architecture)
Every Gemini response passes through a Pydantic ResponderDecision model with Literal action types and typed param models (RedirectParams, ExitParams, BarricadeParams) before touching the grid. On validation failure → hold_position. No exceptions. Raw LLM output never touches the simulation.
Responders decide in parallel (asyncio.gather - all 5 call Gemini simultaneously, ~1–2s total), but apply sequentially with conflict checks. If Responder 2 redirects to Exit C while Responder 4 just barricaded near Exit C, Responder 4's action is downgraded to hold_position. If a responder redirects toward a blocked exit, the action is rejected entirely.
ElevenLabs - dual-voice audio layer
Voice isn't a bolt-on - it's a core UX layer that makes the simulation feel like a real stadium broadcast. We designed two distinct voice personas for two information channels:
| Voice | Role | When it speaks |
|---|---|---|
| Adam (male, authoritative) | Stadium PA system | Emergency events: fire detected, exit closures, evacuation start/end |
| Bella (female, conversational) | Live narrator | Every AI responder decision, tactical observations, flow changes |
Judges know what kind of information they're hearing based on the voice alone. The PA voice says "what's happening." The narrator says "what the AI is doing about it."
Pre-generated cache for zero latency: Common PA phrases (evacuation start, fire detection, exit closure, all-clear) are generated at server startup via pregenerate_pa_cache(). When a fire breaks out during the demo, the announcement plays instantly - no waiting for API round-trips.
Technical challenge: ElevenLabs streams chunked binary audio that standard <audio> elements can't handle. We built a Web Audio API pipeline: receive base64 chunks over WebSocket → decode to ArrayBuffer → AudioContext.decodeAudioData() → AudioBufferSourceNode with queue-based scheduling via onended callbacks for gapless playback. Falls back gracefully to browser SpeechSynthesis when the API key is unavailable.
MongoDB Atlas - the audit trail
MongoDB Atlas via motor (async driver) with 4 collections serving distinct purposes:
scenarios- Stadium layouts, exit configs, timed disaster events. Schema-flexible documents handle variable numbers of exits and events naturally.runs- Complete run metrics (evacuated, trapped, evacuation time, per-exit throughput, bottleneck severity) saved on every simulation completion. Enables cross-run comparison.responder_decisions- Every individual AI responder decision logged with action, params, reasoning, tick number, and responder ID. This granular audit trail makes autonomous AI behavior transparent and queryable.trajectories- Periodic agent position snapshots for replay and post-run heatmap analysis.
All writes are async and fire-and-forget - the simulation never waits for MongoDB.
Google Antigravity - the development multiplier
Antigravity wasn't a code autocomplete - it was our parallel development orchestration layer. We ran 4 concurrent agent workstreams in the Agent Manager, each with isolated context but shared awareness of the project architecture.
Skills files (.agent/skills/) encoded our WebSocket message format, Canvas performance rules (refs not state), and backend conventions (async-only, Pydantic validation on all Gemini responses) once - every agent respected them. This meant independently-developed modules integrated on the first try with zero interface mismatches.
Browser-in-the-loop smoke-tested Canvas rendering, WebSocket connectivity, and obstacle injection without manual QA. We maintained phased roadmaps per workstream that kept agents on track across the 24-hour sprint. Antigravity turned a 4-person team shipping ~5,800 lines of code into what felt like a 12-person team.
Challenges we ran into
The 20fps re-render apocalypse. Our first version stored agent positions in useState. React re-rendered the entire component tree 20 times per second. With 500 agents, the browser froze. The fix was architectural: agent data lives in a useRef, and a decoupled requestAnimationFrame loop draws directly to the Canvas. React never knows the agents moved.
Gemini inside the tick loop. Early on, someone await-ed a Gemini call inside the simulation tick. The tick that normally takes 5ms suddenly took 1.5 seconds. The simulation stuttered visibly. We refactored responder decisions into a completely separate async coroutine (responder_loop) that runs alongside the tick loop. The tick stays pure; AI happens in parallel.
LLM output is a liability. Gemini occasionally returned markdown instead of JSON, or JSON with wrong field names, or creative reinterpretations of the action schema. In a simulation that runs 20 ticks/second, one bad parse crashes everything. We enforced response_mime_type="application/json" and wrapped every response in Pydantic validation with a hold_position fallback. The sim hasn't crashed from a Gemini response since.
Audio streaming is harder than it looks. ElevenLabs sends chunked binary audio. Standard <audio> elements can't handle it - they expect a complete file or a properly segmented media stream. We switched to the Web Audio API, decoding each chunk into an AudioBuffer and scheduling playback with precise timing to avoid gaps.
Responder conflicts. Two responders acting simultaneously can contradict each other - one redirects traffic to Exit C while another deploys a barricade near Exit C. We implemented sequential application with a conflict detection pass that downgrades contradictory actions to hold_position.
Accomplishments that we're proud of
- A genuine multi-agent AI system - not a chatbot bolted onto a dashboard. Gemini-powered agents observe, reason, and act on a live simulation. Their decisions physically change how 500 agents move.
- 5 distinct Gemini integration points - from autonomous responder brains to natural language queries to scenario generation. This is one of the deepest Gemini integrations you'll see at a hackathon.
- Smooth real-time rendering - 20fps server data rendered at 60fps with lerp interpolation, spatial hashing for (O(1)) neighbor queries, and numpy-accelerated Dijkstra under 5ms per recomputation.
- Two AI voices narrating the action - a stadium PA system and a live narrator calling out every responder decision. When other teams show silent dashboards, ours speaks.
- Zero-crash AI pipeline - Pydantic validation, conflict detection, and
hold_positionfallbacks mean the simulation survives any Gemini output, every time. - Interactive disaster injection - judges click to drop fire, collapse exits, and add blockages mid-run. The crowd and AI adapt in real time.
- ~5,800 lines of code shipped in 24 hours across a full-stack real-time application.
What we learned
- Never put high-frequency data in React state. (20 \text{ ticks/s} \times 500 \text{ agents} = 10{,}000) position updates per second. React's virtual DOM reconciliation can't handle it. Mutable refs + a standalone render loop is the pattern for real-time Canvas apps.
- The tick loop is sacred. A simulation engine is a game server. The tick must be pure computation - no
await, no I/O, no network calls. Everything else runs in separate async tasks. - Always validate LLM output. Structured JSON mode (
response_mime_type) gets you 95% of the way. Pydantic gets you to 99.9%. Thehold_positionfallback covers the rest. Never let raw model output touch production state. - Flow fields are magic. One Dijkstra computation per exit gives every agent (O(1)) pathfinding per tick. The alternative - per-agent A* - would be (O(N \cdot V \log V)) per tick and completely infeasible at scale.
- Conflict detection is essential in multi-agent systems. Autonomous agents acting in parallel will contradict each other. Parallel decide + sequential apply with conflict checks is the pattern.
What's next
- GPS-enabled wearables: EvacSim can integrate with GPS-enabled wristbands and smart devices to track attendees in real time and deliver personalized evacuation instructions in multiple languages using Gemini.
- Scale to real stadium capacity: 10,000+ agents with GPU-accelerated flow fields and LOD rendering
- Voice commands: Speech-to-text for judges to inject disasters by speaking ("Start a fire near Gate 7")
- Multi-run A/B testing: Compare responder strategies head-to-head on identical scenarios
- 3D visualization: Three.js renderer with stadium geometry imported from architectural CAD files
- Real-world deployment: Partner with event safety firms for training and pre-event scenario planning
Built With
- a*
- animations
- antigravity
- api
- css
- cursor
- dijkstra's
- elevenlabs
- fastapi
- gemini
- grpc
- html5
- mongodb
- next.js
- numpy
- python-3.12
- react
- react-18
- tailwind-css-v4
- tts
- typescript
- websockets










Log in or sign up for Devpost to join the conversation.