This submission represents the Euler/X project (Open Source code available at https://bitbucket.org/eulerx/euler-project). In brief, this toolkit builds upon prior efforts, validated in the Taxonomic Database Working Group's (TDWG) 2005 "Taxonomic Concept Transfer Schema" (TCS) standard, to evolve identifiers of biodiversity information from the name- to the taxonomic concept-level. The critical addition of Euler/X to the TCS XML representation approach is the incorporation of (potentially scalable) logic reasoning to obtain multi-taxonomy alignments and visualizations. The toolkit remains in a prototype stage but can presently handle use cases of 500 x 500 concepts per input taxonomy at a time, producing logically consistent, provenance-aware, human- and machine-interpretable alignments of all concept elements represented in these taxonomies. The approach rests on the thesis that much of taxonomy's output - and evolution thereof - can be logically represented and reasoned over using (1) tree-like inputs of individual taxonomies and (2) user-asserted Region Connection Calculus (RCC-5) articulations of the respective subelements in each taxonomy. The approach has been successfully applied to a small but semantically diverse set of use cases, including (e.g.) fine-level concepts of grasses, weevil phylogenies, and primate classifications.
An ambitious sounding summary of the potential impact of Euler/X may be as follows. This approach newly addresses, and may relevantly solve, the "taxonomy problem" that haunts virtually every dynamically updated or unifying biodiversity/phylogeny data platform in which taxonomic names are intended to play a key role as identifiers of congruent taxonomic content. We are beginning to demonstrate, case by case, that taxonomic provenance is amenable to computational logic representation and reasoning, when so far solutions to this problem have resided outside of the logic realm, i.e., primarily in the minds and communications among humans.
Relevant publication (Perelleschus): http://journals.plos.org/plosone/article?id=10.1371/journal.pone.0118247
Manuscript - arXiv (Primates): http://arxiv.org/abs/1412.1025
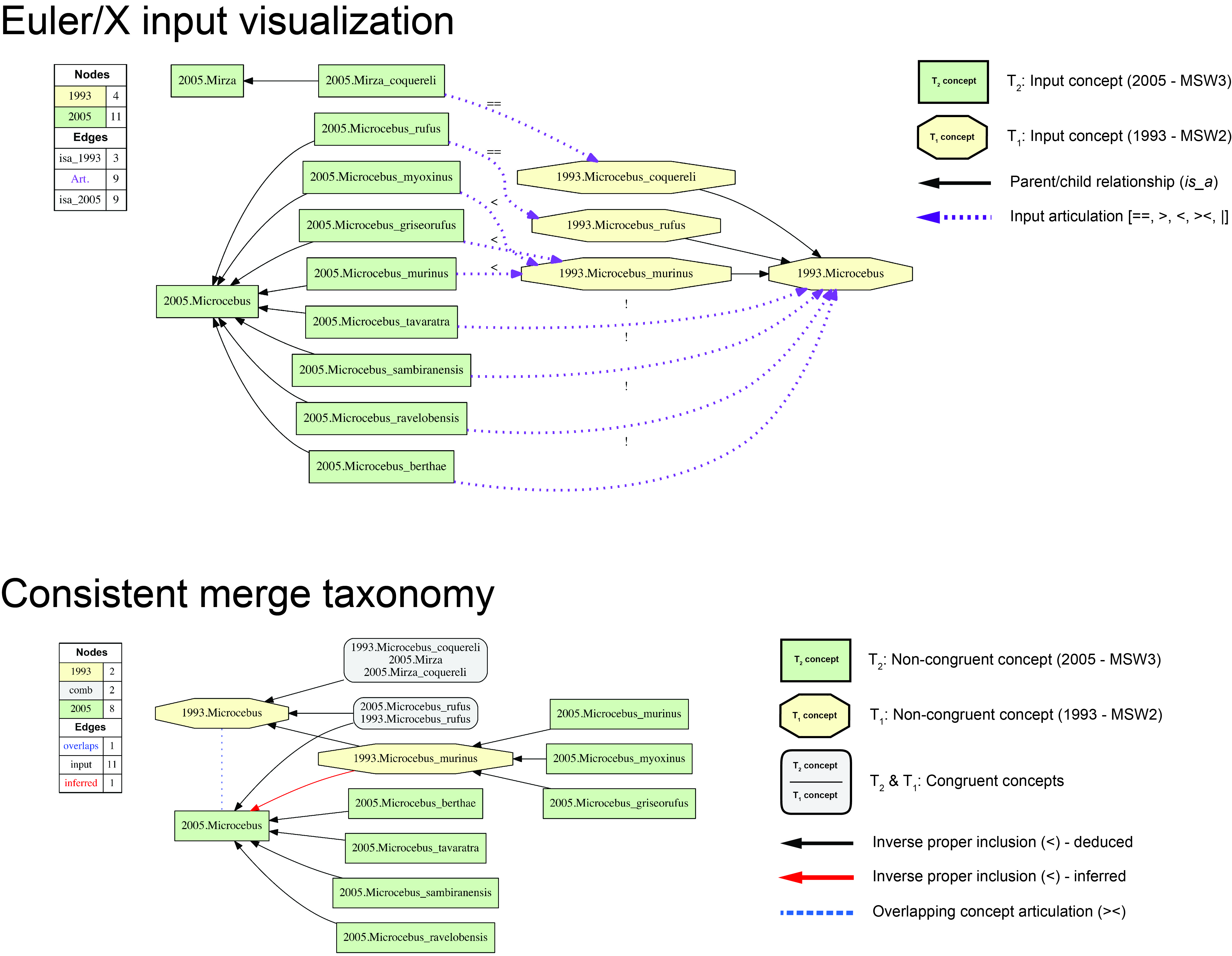
Relevance to GBIF (general example; adopted from arXiv manuscript): "Consider using the term "Microcebus murinus" to query specimen occurrences documented in the Global Biodiversity Information Facility. As of December 2014, this query returns some 560 records whose respective years of acquisition range from 1883 to 2011. We can immediately identify an opportunity to incorporate provenance with RCC-5 articulations in order to render the query more taxonomically granular and reliable. In particular, the two MSW standards endorse two non-congruent taxonomic concepts whose respective labels share the name component "Microcebus murinus". The earlier 1993.Microcebus_murinus is properly inclusive of (>) the later 2005.Microcebus_murinus. Suppose that each of the 560 GBIF records was identified explicitly to either the MSW2 or MSW3 primate classification standard. Many biodiversity data platforms allow contributors to specify the classification scheme used to identity specimens. We could then exploit the reasoner-confirmed and -augmented set of logically consistent RCC-5 articulations to formulate queries of the following types.
(1) Return all records identified to the name Microcebus murinus (optionally, with synonyms or algorithmically matched names). This query corresponds to the current capability of many portals and services. What follows reaches beyond name-based resolution. (2) Return all records identified to the concept Microcebus murinus sec. Groves (1993) and, alternatively, Microcebus murinus sec. Groves (2005). Draw the alternative specimen-based distribution maps. (3) Translate all identifications of records to MSW3-endorsed concepts into their corresponding identifications to MSW2-endorsed concepts. This direction of specimen-to-concept identification translation is usually more feasible than the inverse query, because the MSW3 classification is more granular. (4) Highlight 'problem specimens' potentially identifiable to multiple non-congruent concepts, given the set of aligned classification standards that were used (over time) to carry out identifications. (5) Display records in this target region as identified according to the most, or least, granular concept-level taxonomy. (6) For any set of specimens or ancillary biological data identified to any pair of concepts (there are 153,111 such pairs in the Prim-UC), assess whether the specimens/data can be integrated based on the reasoner-inferred set of MIR. Four out of five articulations – congruence (==), proper inclusion (>), inverse proper inclusion (<), and exclusion (|) – represent direct, unidirectional (>, <) or bidirectional (==, |) provenance information to resolve this query.
The above queries and others that leverage taxonomic provenance information via RCC-5 articulations are needed to build more semantically powerful biodiversity data portals."

Log in or sign up for Devpost to join the conversation.