-
-
Front end
-
Transcription
-
Request for transcription
-
Verification / adjudication metric
-
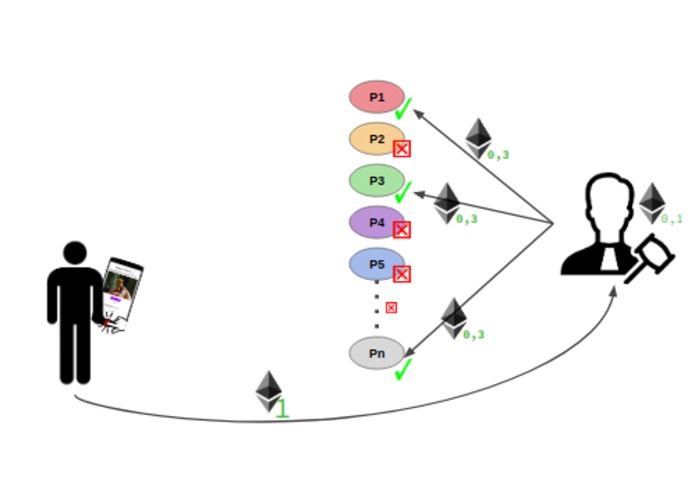
Reward payment transfer

ethberlinzwei-babelfish_3_0
EthBerlinZwei hackathon submission for a decentralized speech-to-text transcription service!
Youtube screencast demo - full e2e
Team
Marcus - Full stack
Magdalena - Data Science
Key innovations
- Productionization of the open source DeepSearch speech transcription model
- New similarity voting metric for automated reward for proper actors in the network
- Intergration with the Ocean Protocol network for data ownership and incentivization
- Concept development for decentralized dispute resolution
- Proof of concept for generalized compute services orchestrated by Ethereum
Concept
Speech to text transcription is the problem tackled in this project. This is furthermore a demo and hack for generalized compute and AI services which are orchestrated, incentivized, scaled, and secured by Ethereum smart contracts!
There exist several popular transcription services, for example, the Google Speech-To-Text API.
But wait, are you willing to give away your sensitive audio speech files to a FANG company? What if you could be rewarded for providing your speech audio file? And what about competition and price discovery?
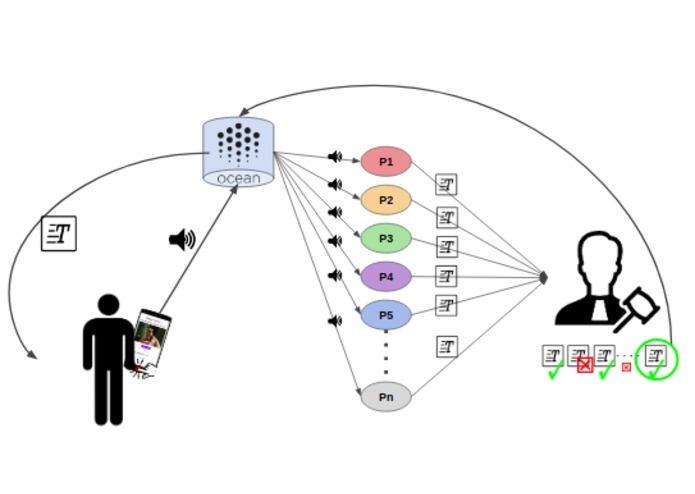
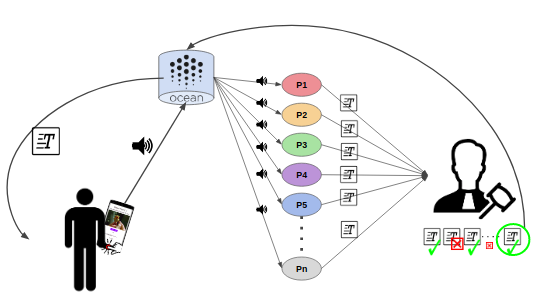
Project babelfish 3.0 envisions and enables a mobile DApp which puts the power back in your hands.
As a user, you specify the price for your data (0 if you want to only purchase the transcription), the reward offered to the processor services, and the number of processor nodes. With these settings, your audio file is securely registered into the Ocean Protocol decentralized data registry.
Next, the processor nodes bid on offering the requested service. The chosen processors execute the transcription task, and submit (oracalize) their results to a Verifier smart contract.
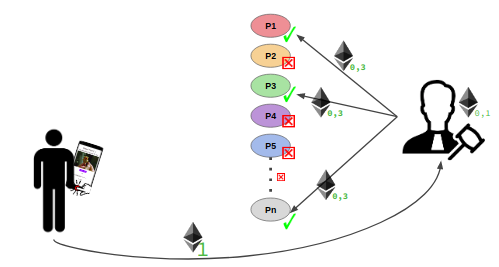
The Verifier gets an input a list of results provided by the processors. It computest the Semantic Textual Similarity which is a base for obtaing fraud score for each transcription she/he got. If the fraud score of a transcription is lower than 0.5, the verifier considers it as fraud and returns 0, otherwise it outputs 1 indicating that the transcription task is verified.
After that, the Verifier distributes equally to all verified processors the amount of ETH she/he got from the client, keeping some amount of ETH as a reward for performing the verification. Finally, one of the verified text files is randomly chosen by the Verifier and sent to the Ocean Protocol. The client then gets the new asset which is a verified transcription of the initial audio file.
Scope of the project
Prior work, libraries,
This project makes use of the open source Ocean Protocol project to register and 'own' data assets.
This project uses the open source DeepSpeech library for transcription.
Implemented
- Interfacing to Ocean Protocol for registration of audio file via python client library.
- Interfacing to Ocean Protocol for download of audio by processors
- Transcription of audio using the open source DeepSpeech tensorflow library and pre-trained model.
- Productionization of the transcription service with Flask
- Simulation of the verifier service
Not implemented / WIP
- Verifier smart contract not programmed or deployed
- Full end-end integration (manual walkthrough, see below)
Project repo organization
/frontend contains the angular front-end interface for the DeepSearch transcription service
/backend contains the development and deployment of the backend transcription service with tensorflow
/scripts contains the ocean protocol integration development
Deep dive: Transcription service
This project employs the DeepSpeech pre-trained model for speech transcription. DeepSpeech is an open source engine, using a model trained by machine learning techniques based on Baidu's Deep Speech research paper. Project DeepSpeech uses Google's TensorFlow to serve predictions.
The model is built using a Recurrent Neural Network, with the architecture presented in the figure below.

The model API has been wrapped with Python-Flask (back-end), and presented using a simple front-end (angular).

Deep dive: Verifier
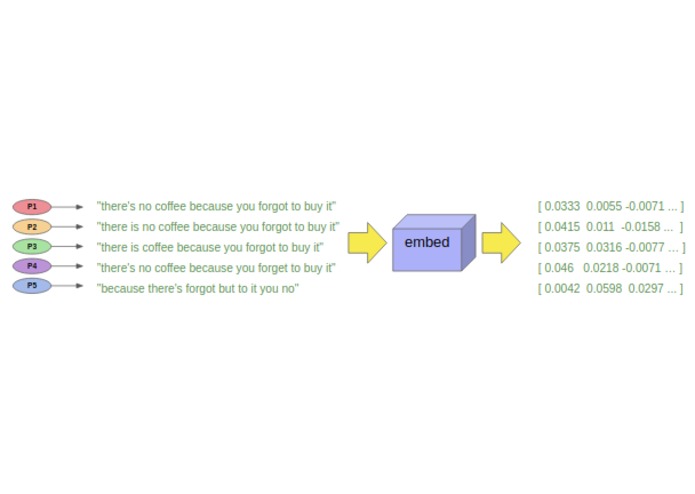
Once a Verifier gets a list of transcriptions from the processers, he/she encodes each text into high-dimensional vectors using Universal Sentence Encoder.

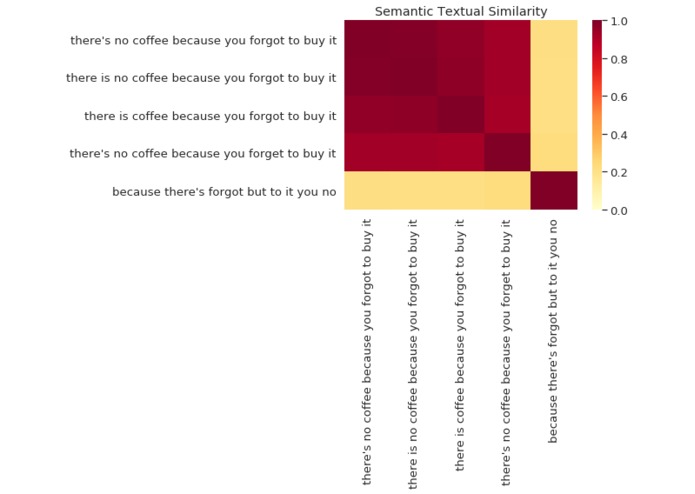
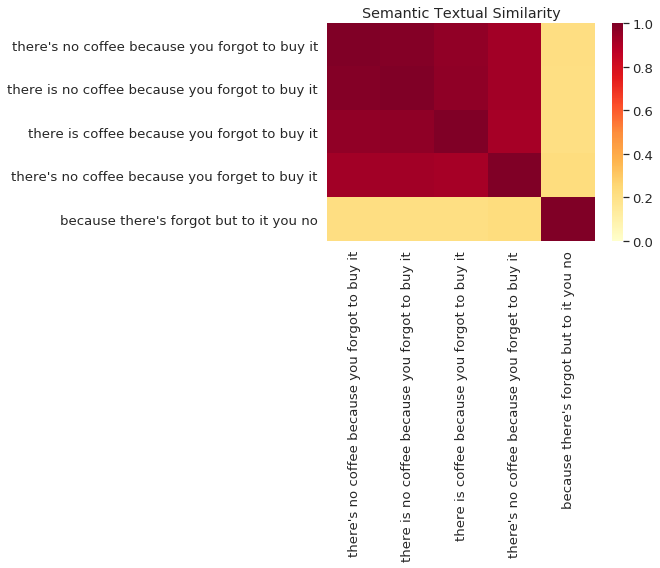
As next, the Verifier pairwise computes semantic similarity of the transcriptions which is a measure of the degree to which two pieces of text carry the same meaning. The semantic similarity of two sentences can be trivially computed as the inner product of the encodings. The following figure visualizes how the transcriptions are similar to each other where 1 is the highest and 0 the lowest semantic similarity score.

Then, for each transcription the Verifier computes the Fraud Score which is simply the average semantic similarity score between one transcript and the remaining ones produced by other processors. In our example, the fraud scores would be the following: 0.774652, 0.77324998, 0.76432037, 0.75055325, 0.21729597. We consider each transcription with fraud score below 0.5 as not verified (returning 0) and all others as verified (returning 1). The Verifier returns a list made of zeros and ones (in our case: 1, 1, 1, 1, 0; this means that all but the last transcript are verified).
Deep dive: End to end user story
Youtube screencast demo - full e2e
Step 1: Client uses mobile phone to store audio

Step 2: Client registers audio into Ocean Protocol
python 0_publish_audio.py \
--url https://public-data-seeding.s3.eu-central-1.amazonaws.com/Test+Video+/testcoffeeshort.wav \
--price 10 \
--reward 50 \
--number-nodes 3
Command line API parameters;
--urlthe url of the asset--pricethe demanded price to download the asset (can be 0)--rewardthe offered reward for the processing job--number-nodesthe number of processors requested for this job
Increasing the number of processing nodes will increase the reliability of the transcription due to the voting mechanism, but can decrease the incentive for nodes to participate.
Youtube screencast demo - register audio
Step 3: Processor nodes bid on the open job, and purchase the audio asset
python 1_processor_purchase_file.py \
--did did:op:f8252ea7a645475a9c519a241112ab292ff66b7d4a2049a5862b34bcfa507c30
Command line API parameters;
--didthe Decentralized IDentifier of the registered audio asset to purchase
Youtube screencast demo - consume audio
Step 4: Processor nodes transcribe the audio, and submit results for verification
Processor nodes download the asset from the Ocean Protocol and convert it into a text file using the deepspeech library. Then, they send the resulting transcription to the Verifier and wait for verification.
Step 5: Verification process and transmission of final text transcription
The Verifier gets the transcriptions from all the participating processor nodes and performs the step described previously (see Deep dive: Verifier). After that, it distributes equally to all verified processors the amount of ETH she/he got from the client, keeping some amount of ETH as a reward for performing the verification. Finally, one of the verified text files is randomly chosen by the Verifier and sent to the Ocean Protocol. The client then gets the new asset which is a verified transcription of the initial audio file.
Built With
- amazon-web-services
- angular.js
- python
- tensorflow




Log in or sign up for Devpost to join the conversation.