-
-
Welcome Page
-
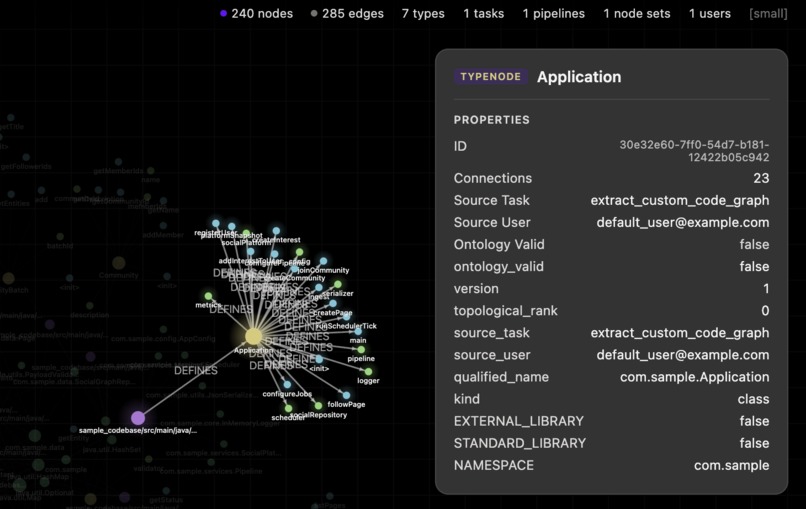
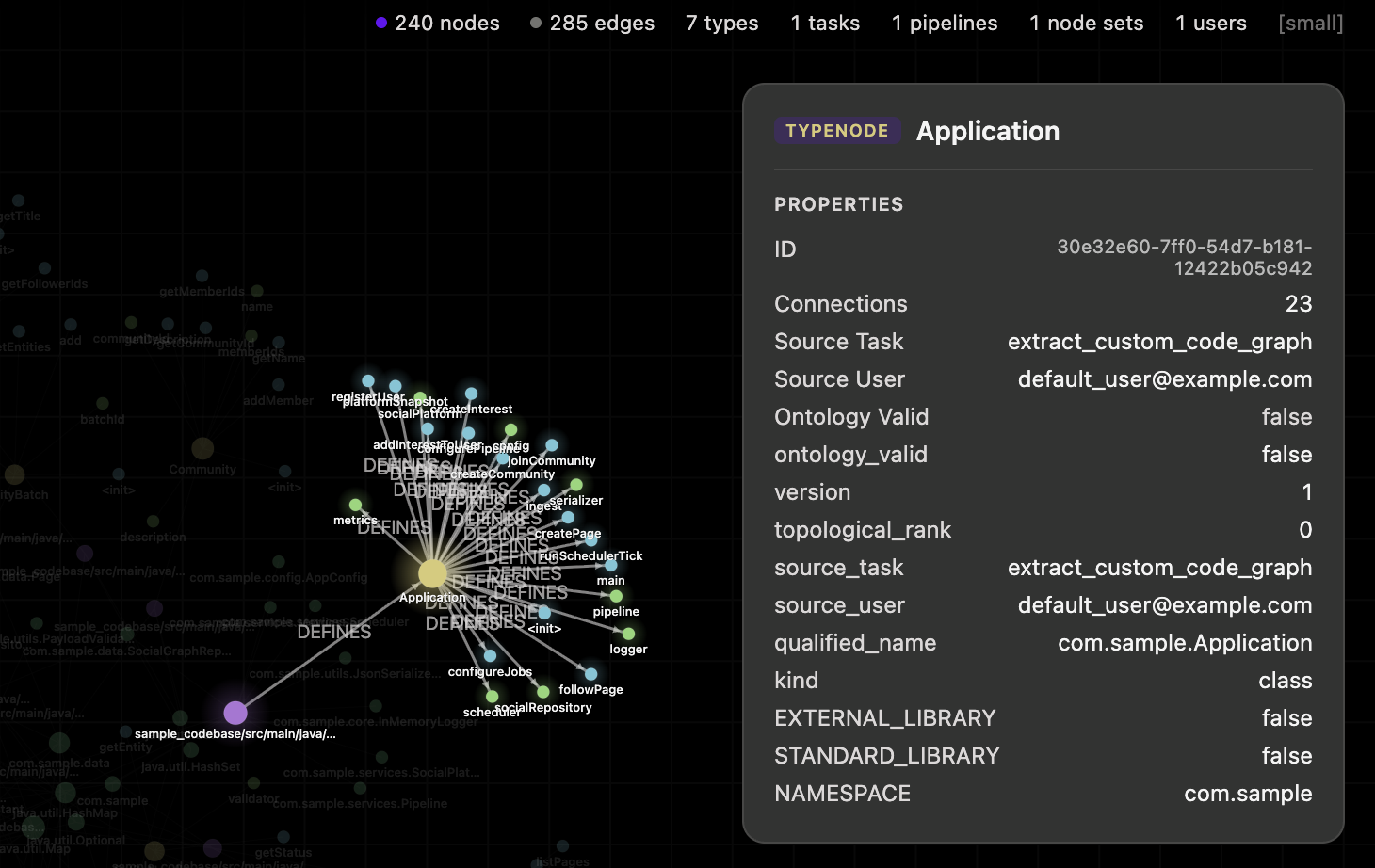
Graphv View: Shows codebase as nodes and edges, connecting dependencies
-
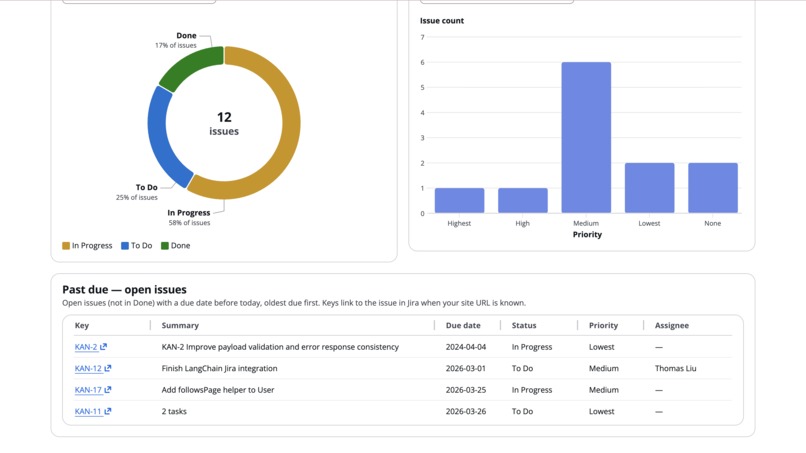
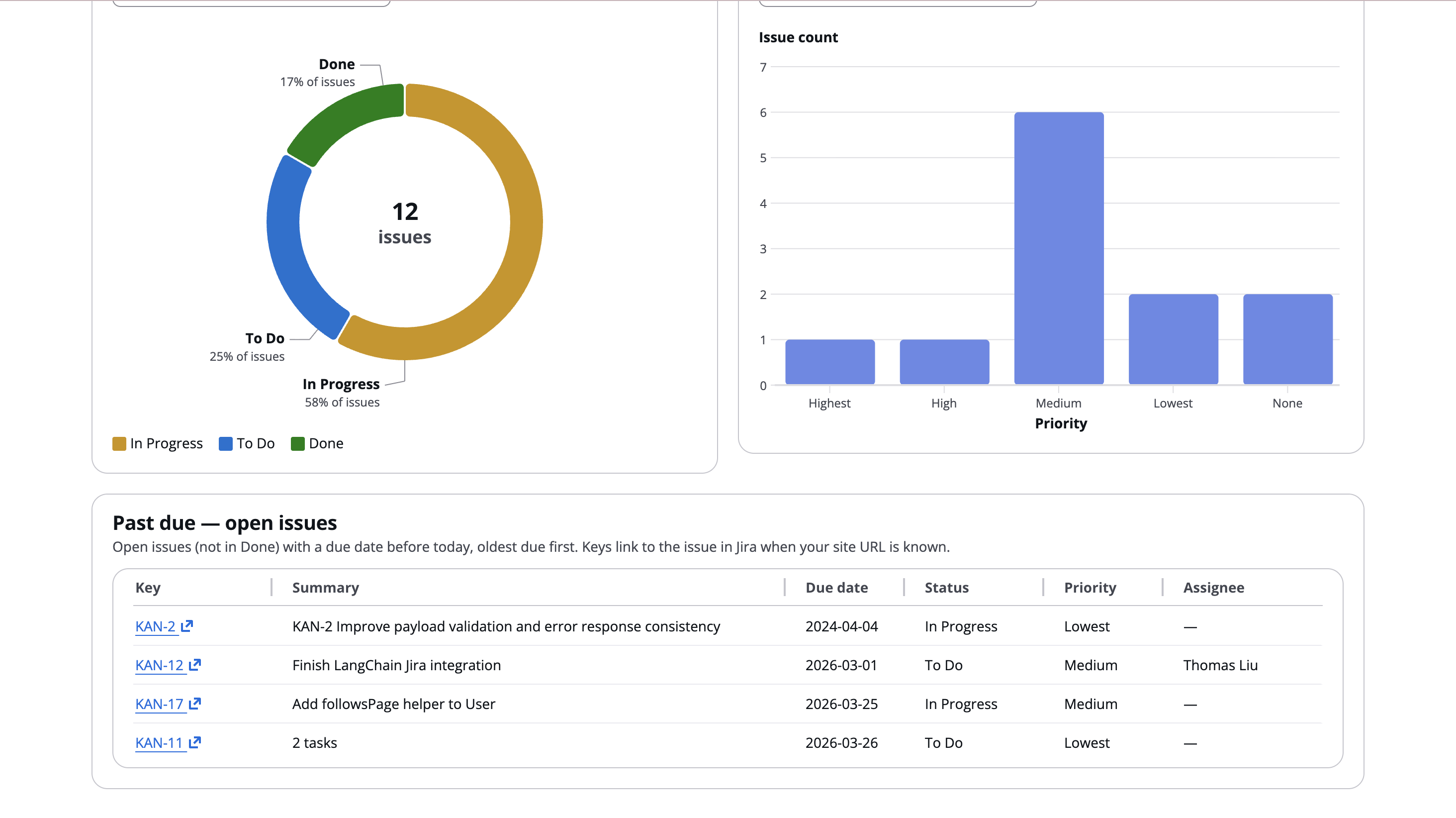
Overview Screen: Key indicators
-
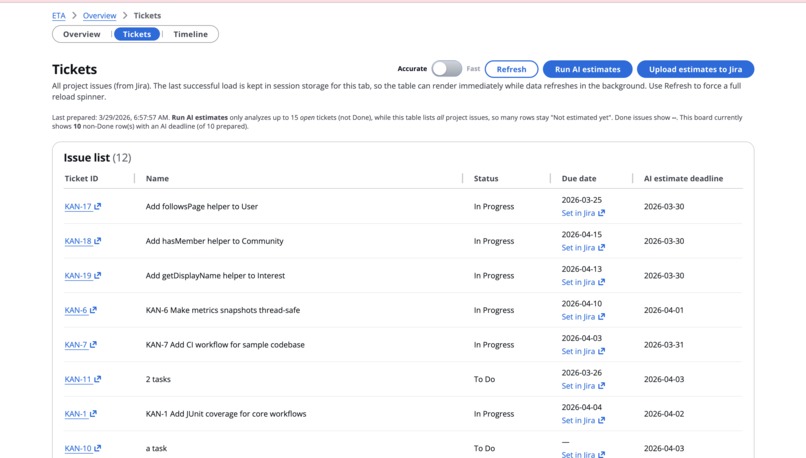
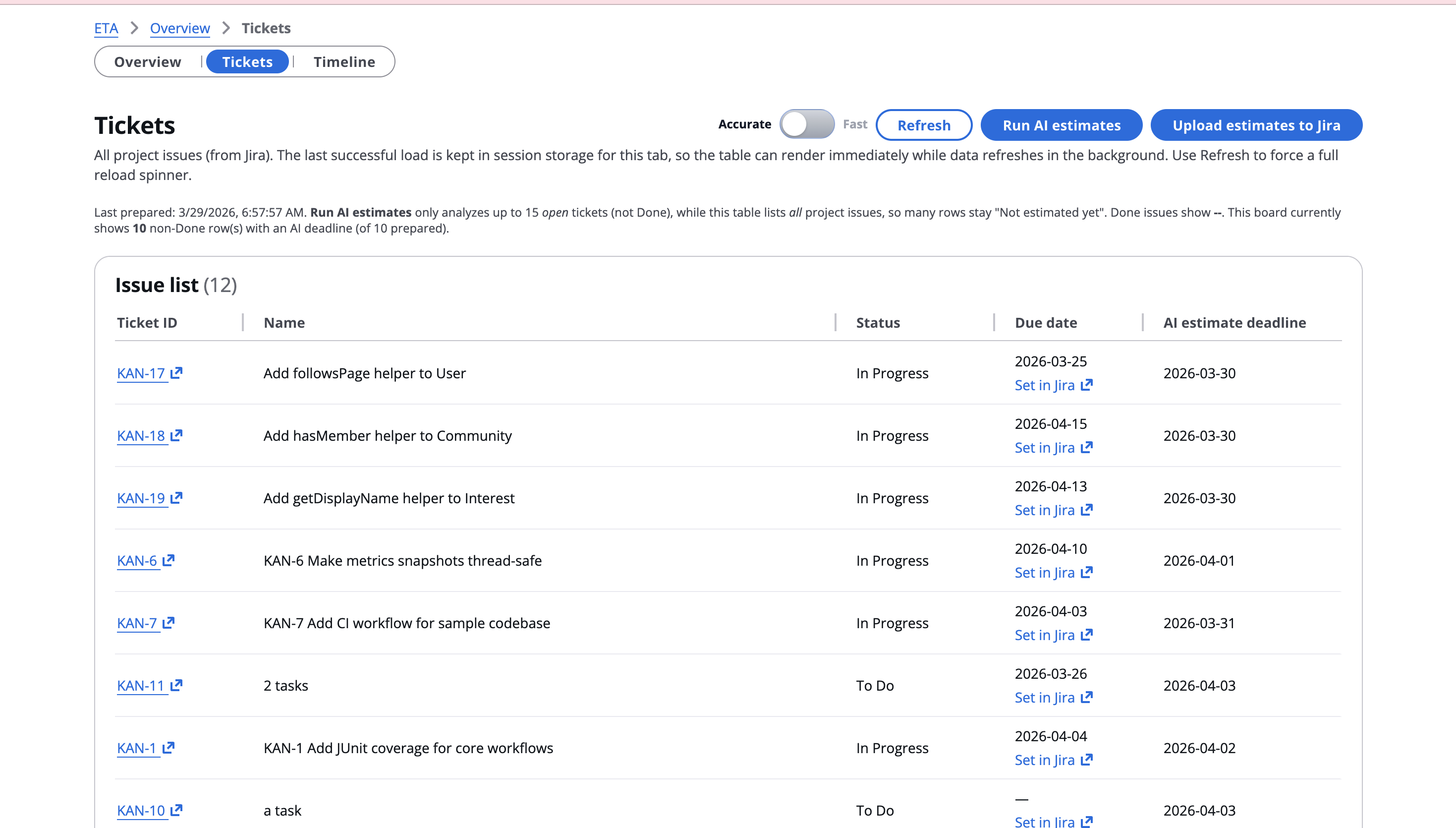
Tickets Screen: Deploy agents for timeline estimation and push to Jira
-
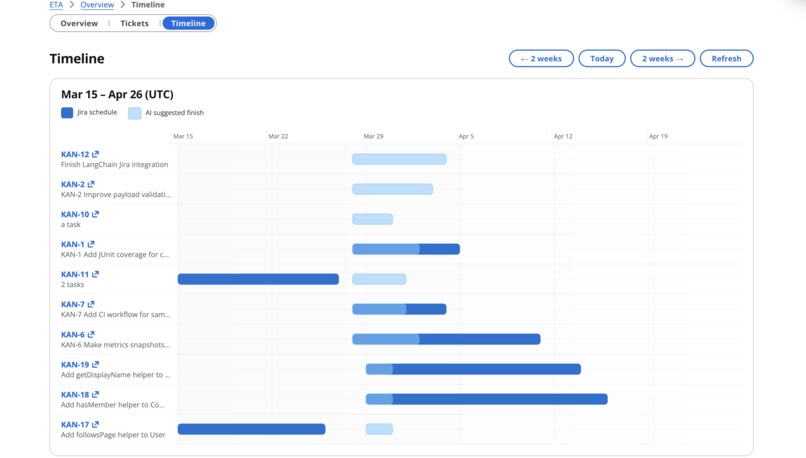
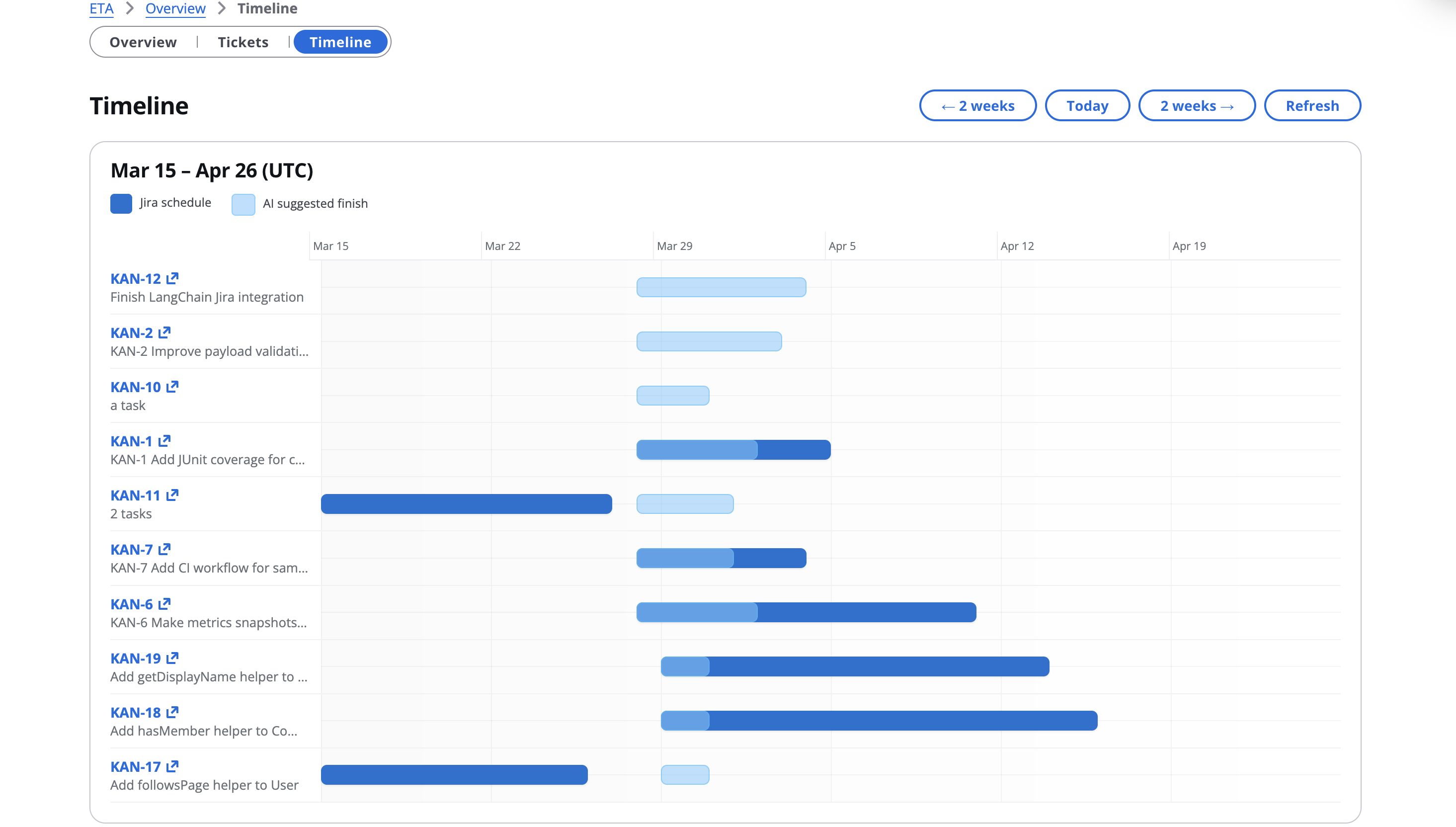
Timeline Screen: Gantt Chart for timeline visualization
-
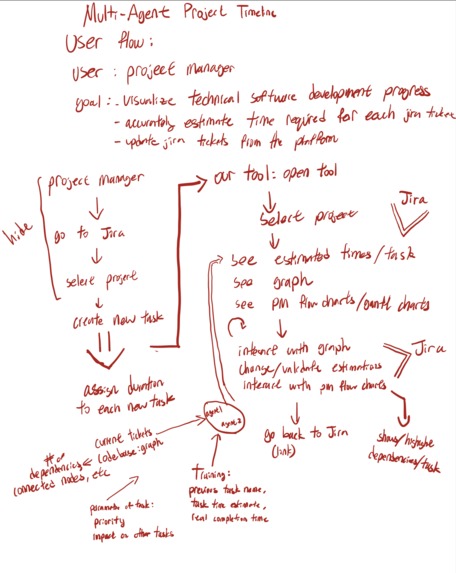
Inspiration
Over 90% of projects fail to meet at least one major objective, and 75% miss their original schedule. The root cause is often poor time estimating. For employees, this means chronic burnout and sacrificed personal time. For businesses, operations stall, forecasts are inaccurate, and employees leave. Having witnessed and experienced this in our previous roles, we wanted to build an enterprise tool that protects all parties with accurate estimations.
What it does
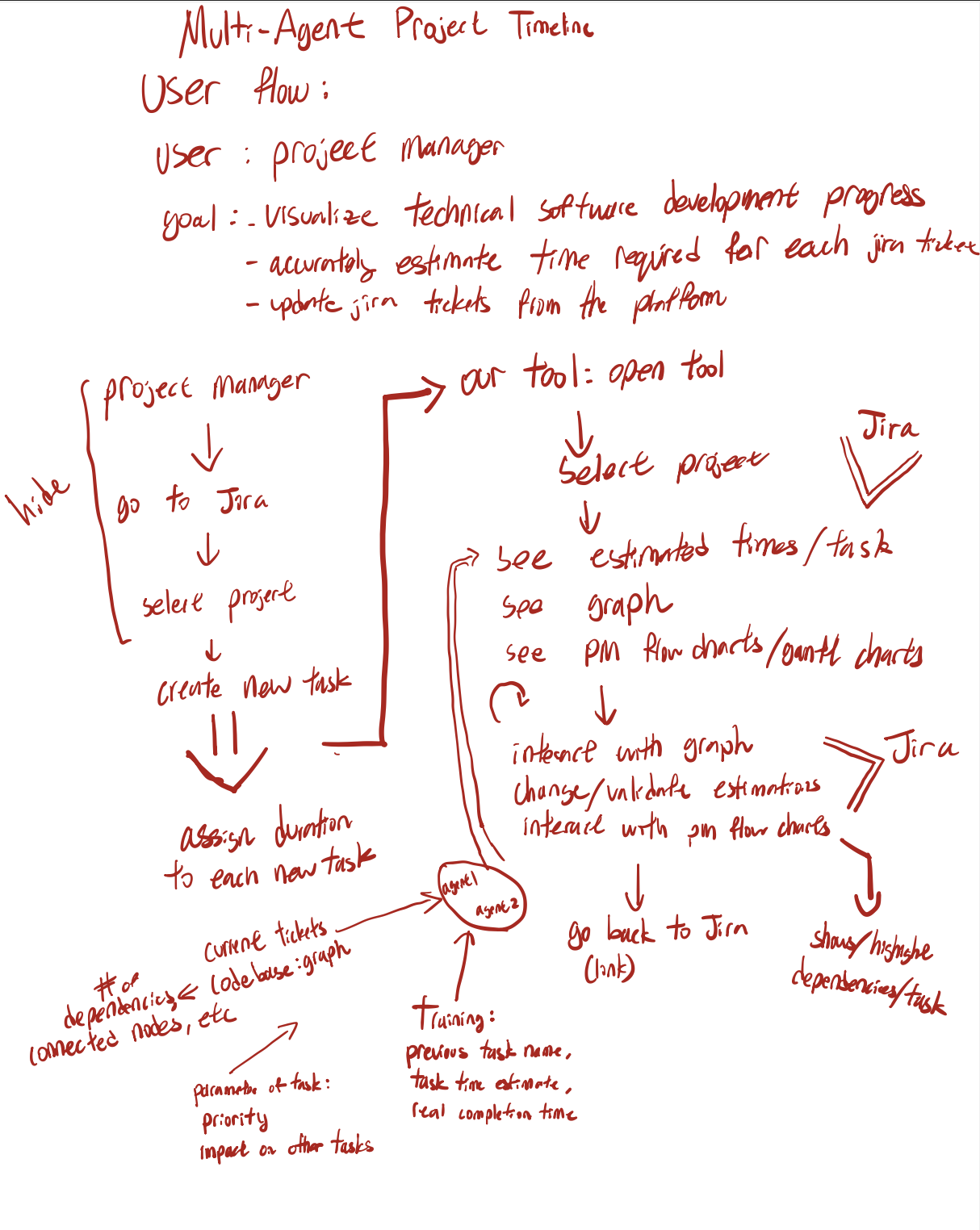
ETA (estimated time of arrival) is a multi-agent service that enables project managers and team leads to improve and automate work timeline estimation.
Rather than performing tedious, 'gut-feeling' estimations for task due dates in Jira, ETA deploys agents that analyze Jira ticket parameters and the relevant portion of a repository to create accurate suggested times. The repository is converted into a knowledge graph, allowing an agent to easily find the nodes relevant to a ticket and its dependencies. The graph also assists as a UI feature, allowing PMs to see task dependance on other nodes, or how reliant other nodes are on a ticket.
A series of dashboards show parameters relevant to task duration estimation, and a page allows PMs to add and update existing tickets with the Agent-provided times. A tab lets PMs visualize and present the impact of their choices by generating Gantt and other project planning charts.
How we built it
Our platform is architected around two specialized AI agents that jointly handle repository understanding, timeline estimation, and Jira workflow automation.
Agent 1: Codebase Intelligence and Timeline Prediction
Agent 1 is powered by Gemini and is responsible for generating timeline estimates for active tickets. It takes in the full codebase, active and historical Jira tickets, and historical ticket resolution times. By combining repository context with historical patterns, the agent can produce informed estimates for future and ongoing tickets.
To support large-scale repository reasoning, we use Cognee to ingest repo code and construct a knowledge graph over the codebase. In this graph representation, entities such as classes, functions, interfaces, and modules are modeled as nodes, while relationships such as CONTAINS, CALLS, IMPORTS, and EXTENDS are modeled as edges. This converts the repository from a flat collection of text into a structured graph outlining the dependancies.
We then use LangGraph to build a GraphRAG-based retrieval agent on top of that knowledge graph. This enables connected, context-aware retrieval during inference, allowing the system to reason over structural relationships in the code rather than relying solely on embedding similarity or keyword matching. As a result, Agent 1 can retrieve more relevant technical context and generate better-grounded ticket timeline predictions.
Agent 2: Jira Workflow Automation
Agent 2 is built on K2 Think V2 and manages all platform interactions with Jira. It utilizes somes custom tools built on top of the Jira Cloud Platform REST API, enabling direct read/write operations on project-management data.
Deployment Both agents are exposed through a frontend implemented in HTML and TypeScript, which serves as the primary interaction layer for end users. The system is deployed with the backend hosted on Render and the frontend hosted on Vercel.
Challenges we ran into
Configuring cache was taking longer than expected due to extensive graph queries; fixed and runs quickly. Embeddings with Gemini was expensive, used calculated rate limiter. Due to API privacy laws in Jira, no usernames could be stored. Instead we tracked assignees by mapping user IDs through a reverse search rather than using name and email.
Accomplishments that we're proud of
- Despite having little experience in frontend development, we think out website looks pretty good!
- Our visualization tool is robust and works well for helping devs see how the code fits together
- Had fun using and integrating K2 Think V2 for the first time
- Our platform supports a full project lifecycle, from estimation to ticket creation within a single interface.
What we learned
- LLMs are super powerful, but the correct context info and structure is everything in getting the best performance.
- Seems as if every layer of enterprise can be massively scaled and made more efficient through the incorporation of AI tools to work with people.
What's next for ETA
Training Jira Agents on previous Jira task description and real completion time (Linear Regression) Support multiple repos for the same Jira project Implement a feedback loop for all dependent task time updates on the UI
Built With
- cognee
- css
- geminigcp
- html
- java
- k2thinkv2
- python
- restapi
- typescript

Log in or sign up for Devpost to join the conversation.