Inspiration Inventory mismanagement due to inaccurate demand forecasting often leads to overstocking or stockouts. Our goal was to leverage machine learning to enhance the accuracy of SKU estimation, ultimately optimizing inventory planning and reducing operational costs.
What it does
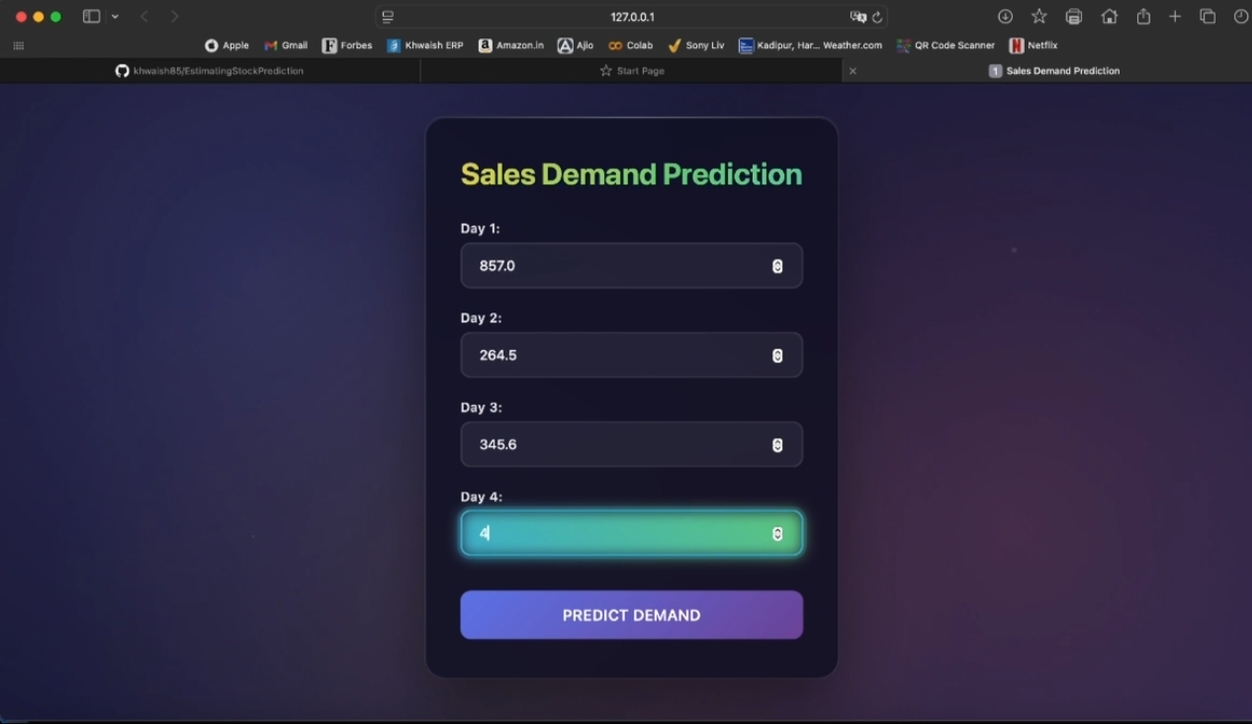
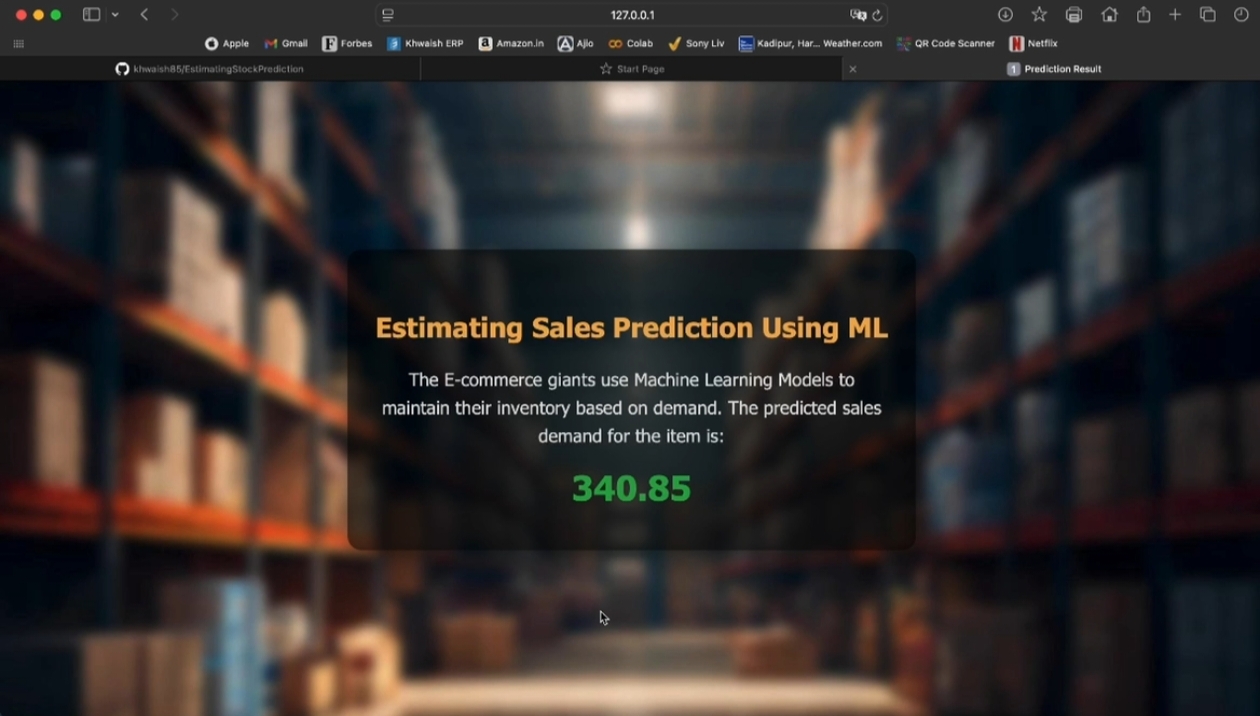
The system predicts the required quantity of Stock Keeping Units (SKUs) for a given period using historical sales data and relevant features. It helps businesses make data-driven inventory decisions, improving efficiency and minimizing waste.
How we built it
We collected and preprocessed historical sales data, engineered features like seasonality and promotional effects, and trained multiple machine learning models such as Random Forest and XGBoost. The best-performing model was deployed in a user-friendly interface for real-time SKU estimation.
Challenges we ran into
Handling missing or inconsistent data across different SKUs
Capturing seasonality and promotional impacts accurately
Balancing model performance with interpretability
Limited data for new or slow-moving SKUs
Accomplishments that we're proud of
Achieved high prediction accuracy with minimal overfitting
Developed a scalable pipeline adaptable to different product categories
Improved inventory forecasting performance over baseline methods
What we learned
The importance of domain knowledge in feature engineering
How different models respond to time-series patterns and noise
The value of combining statistical techniques with machine learning for better results
What's next for Estimating Stock Keeping Units using ML
Integrating external data sources like weather and competitor pricing
Incorporating deep learning models for better temporal understanding
Deploying the solution in a real-time inventory management system
Expanding to multi-location forecasting and demand clustering











Log in or sign up for Devpost to join the conversation.