-
-

demonstration
-
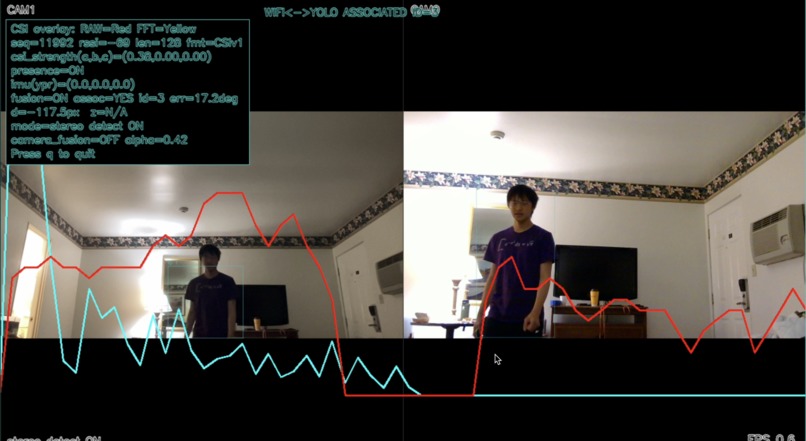
Demo
-
Code Page

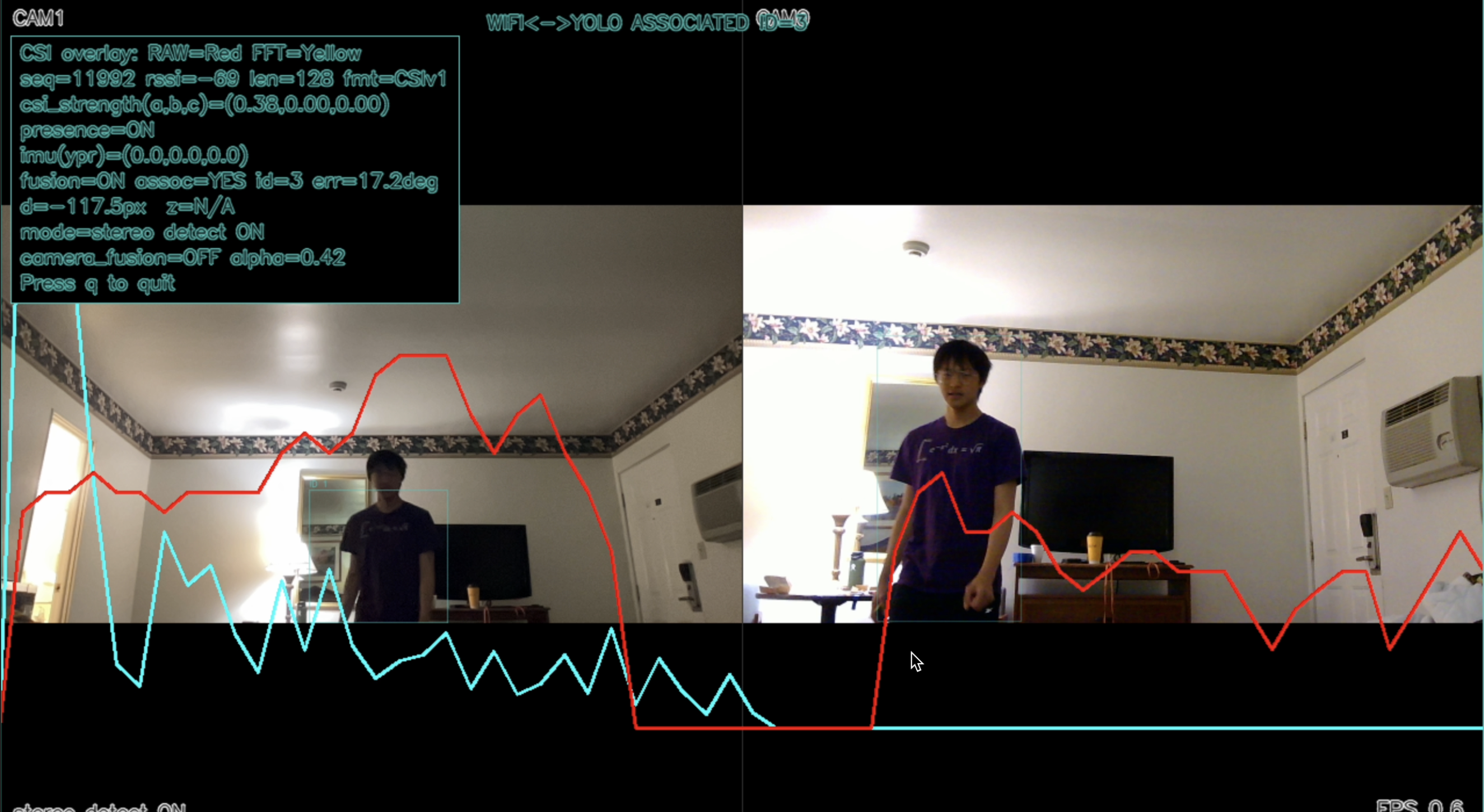
Inspiration
Urban search-and-rescue, disaster response, and smart-city monitoring motivated this project.
In emergency environments, responders face degraded visibility, obstructed line-of-sight, and incomplete situational awareness.
Conventional vision systems fail behind smoke, debris, walls, or weak lighting. Many tracking systems also rely on infrastructure that may be unavailable during crises.
This inspired us to explore a low-cost, ESP-based, remotely deployable multimodal sensing platform that combines computer vision, RF sensing, and intelligent fusion.
Our broader vision is a rescue robot and smart tracking system that can detect, localize, and track targets even in partially occluded or visually compromised environments.
What It Does
Our system is a multimodal smart-tracking platform that integrates visual sensing with radio-frequency signal analysis for real-time target awareness.
It is designed to:
- identify nearby devices through Wi-Fi metadata (signal presence, network identifiers, and MAC-layer information),
- perform visual detection and tracking of humans or objects,
- maintain continuity under conditions where a single modality would fail.
The architecture supports remote operation in constrained or hazardous environments.
The core intelligence stack uses CNN-based pipelines for detection, feature extraction, and cross-modal target association.
We also envision a vision-language reasoning layer using a large multimodal model for scene interpretation, semantic labeling, and operator interaction.
The result is a system that not only senses dynamic environments, but also helps contextualize them in real time.
How We Built It
We built the platform around ESP-based embedded control and sensing hardware, chosen for low power use, fast prototyping, and wireless integration.
The hardware stack combines:
- camera input,
- Wi-Fi/RF sensing,
- mobile actuation/control components.
On the signal-processing side, we implemented phase-based localization and geometric position estimation via trilateration/triangulation frameworks.
On the visual side, we perform object detection and tracking with convolutional models.
A sensor-fusion layer aggregates both pipelines to improve robustness under occlusion, multipath interference, and viewpoint changes.
We integrated remote control and streaming for teleoperation and distributed sensing, and started exploring neural-network-based association methods to align detections across modalities.
The design is modular so individual sensing and inference blocks can be replaced as hardware matures.
Challenges We Ran Into
The main challenges were:
- power limitations,
- calibration instability,
- geometric inconsistency across sensing modalities.
Reliable RF localization required phase coherence, which was hard to maintain under real-world drift, offset, and multipath.
Small synchronization errors quickly produced large localization errors, especially when parallax and coordinate transforms were imperfect.
We had to repeatedly refine the geometric model and the mapping between camera-space detections and RF-space estimates.
Another challenge was modality mismatch:
- camera pipeline: dense spatial information,
- RF pipeline: sparse, noisy, environment-dependent data.
Achieving robust real-time fusion required careful filtering, alignment, and threshold tuning.
Hardware availability was also constrained, with key tools/components arriving late, so some subsystems were demonstrated independently rather than as a fully optimized end-to-end package.
Accomplishments That We’re Proud Of
We achieved real-time detection and tracking despite hardware, calibration, and schedule constraints.
Even with incomplete tooling and delayed components, we built a functioning multimodal prototype demonstrating the feasibility of combining embedded vision, RF sensing, and remote control.
We are also proud of the architecture itself.
Instead of a single-purpose detector, we built a scalable sensor-fusion foundation where future improvements in antennas, compute hardware, and learning models can be inserted without redesigning the full pipeline.
This makes the project both a working demo and a platform for continued research and engineering development.
What We Learned
This project taught us that embedded intelligence is a systems problem, not just a software problem.
Working with ESP32-class hardware forced tradeoffs across:
- sensing bandwidth,
- compute budget,
- latency,
- energy constraints.
We learned that advanced methods (including MPC-style control) are not always practical under strict memory and power limits.
Algorithmic elegance must be balanced with execution cost and implementation realism.
We also learned that multimodal sensing quality depends heavily on:
- synchronization,
- stable phase references,
- correct coordinate transforms.
Sensor fusion is only as strong as modality alignment.
Finally, we gained practical experience integrating embedded communication, RF handling, real-time perception, and system-level debugging under rapid prototyping constraints.
What’s Next for ESP-Based Smart Tracking Multi-Sensor Fusion
Next, we plan to improve both sensing front-end and compute back-end.
Hardware priorities:
- optimize custom directional antennas (especially Vivaldi-based designs) for stronger beamforming and better directionality,
- improve penetration-aware RF sensing,
- migrate key fusion/signal-processing workloads to FPGA acceleration for lower latency and scalable multi-link processing.
Algorithm priorities:
- faster association methods with better computational complexity,
- more reliable multimodal correspondence,
- stronger tracking persistence in cluttered environments.
We also plan VR-based operator association/visualization for intuitive interpretation of fused spatial data.
Longer term, we aim to strengthen the vision-language reasoning layer, improve geometric localization, and evolve this prototype into a robust rescue and smart-city tracking platform suitable for larger-scale deployment.

Log in or sign up for Devpost to join the conversation.