Final Write Up
Poster
Original Idea
Title
Artsy Image Generation with text input - extended implementation of ControlGAN
Who
Andy Truss- atruss Orion Bloomfield- obloomfi Joel Manasseh - jmanass1 Eshaan Mangat - emangat
Introduction
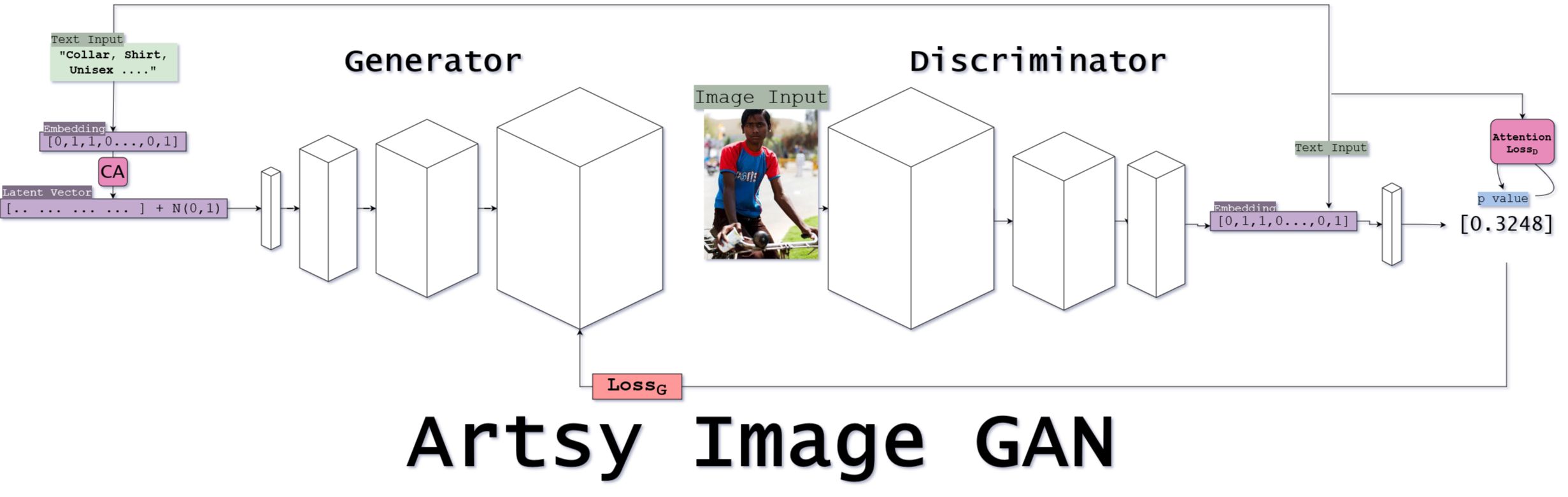
We are implementing a Generative Adversarial Network that can take in an input text, reference an input database, and generate novel images. Text-based image generation is an exciting emerging field in deep learning, which has growing capabilities and popularity - (see neuralblender for a very impressive new implementation of this effect). With our implementation of ControlGAN, we are hopeful to build on the paper’s implementation as well as implement some sort of “Creativity” score that encourages more “artistic” outputs.
Related Work
This project is an extended implementation of the ControlGAN paper link where we are attempting to add a more “artistic focus” to the network with added scoring metrics to behave more like Neural Blender link. The whole image generation framework is built upon the general GAN framework describe in this paper: link
Data
We will probably be using a standard image dataset such as Imagenet. We will fine-tune the number of images we will be using during the implementation, but significant preprocessing will not be necessary.
Methodology
AttnGAN - a bidirectional RNN that encodes sentences into feature maps. We will be using a pretrained model, as 1) it would add a lot of scope to the project to perfect an LM RNN, would not be able to train a network as well as pretrained alternatives, and do not want our whole project to be bottlenecked by poor textual context. (If we have extra time, we will attempt our own feature map RNN that will be akin to our setup of the LSTM in project 3, but with added Attention. If so, we will be training this model with the text input from hw3, as well as any other sentence datasets we can find.) ControlGAN - From the paper, we will be following the implementation of connecting the text encoder (AttnGAN) to the attention-based GAN. Of this, loss is considered by comparing the reference image of the labeled-set with perceptual loss to the fake image. A word-level discriminator is used to build on the perceptual loss. Within this as well, if we have time, we will be implementing some “creativity metric” that can work within the perceptual loss network to encourage image generation that is more fluid and art-like, not attempting to just recreate the reference set completely. (We will be looking at other reference papers later for inspiration on “creativity” once we complete the rest of the network)
Metrics
For image generation, even after making a successfully low-loss network, we will be collecting our test results of new text inputs in a folder to share in our presentation. Although all judgements are qualitative, we would hope that 1) we can first implement the same ability as the reference paper to recreate lifelike imagery, but 2) with a different metric scheme involved, see if the new images created can still retain aspects of the image-accurate ControlGAN, while applying more stylistic creativity.
Ethics
Why is Deep Learning a good approach to this problem? Words do not have singular meanings. For example, the word “vase” does not necessitate the image of a white porcelain decorative container perfectly perched on a side desk. A vase could be any number of colors or shapes or have any number of use cases. This is why Deep Learning is the optimal way to approach the issue of image generation from natural language. Deep learning allows us to attempt to understand words the way humans naturally do, with context and connotation, and thus, in our case, create images which accurately portray the essence of the words we are fed.
How are you planning to quantify or measure error or success? What implications does your quantification have? We are planning on measuring success by the qualitative output of the GAN from general text inputs. Obviously, we want the network to be able to create a realistic image based on the text input, but we also hope to add some artistic value to the image as well. That does raise the implication that everyone has biases towards what constitutes good art. Because it is difficult to numerically define success, our qualitative judgment should not be too based on personal preference to what looks good/bad/realistic or not.
Division of labor
Orion -> Responsible for the development of model architecture Eshaan -> Responsible for preprocessing and visualization Joel -> Responsible for write up and presentation Andy -> Responsible for debugging
Check-ins
Built With
- python
- tensorflow


Log in or sign up for Devpost to join the conversation.