-
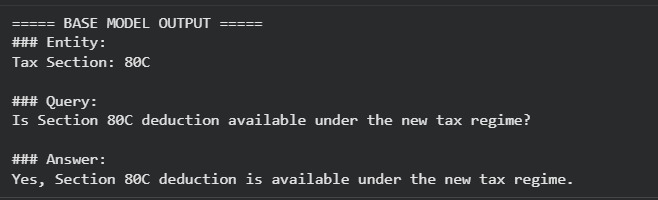
Pre-finetuning output
-

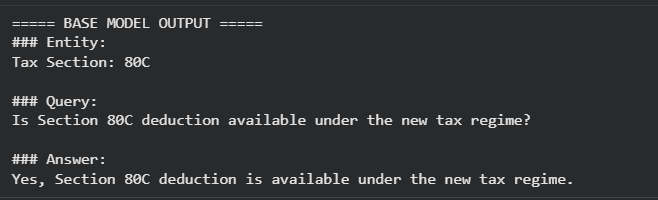
Post-finetuning output

Inspiration
Large language models trained on broad web-scale data often struggle with statutory and regulatory domains, where rules are precise, conditional, and frequently updated. While testing general-purpose models on Indian income tax questions, we observed repeated factual inaccuracies, particularly when distinguishing between the Old Tax Regime and the New Tax Regime.
A recurring failure case involved Section 80C, where models incorrectly claimed that deductions were available under the new tax regime. This highlighted a deeper issue: models were relying on outdated or conflicting web-era information rather than current statutory rules. This motivated us to explore whether parameter-efficient fine-tuning could be used to correct such high-confidence factual errors.
What it does
This project fine-tunes ERNIE-4.5 to answer Indian income tax regime questions accurately for Assessment Year 2024–25.
The fine-tuned model:
- Correctly differentiates between Old and New Tax Regimes
- Avoids hallucinating deductions under the new tax regime
- Produces concise, regime-aware, and legally consistent answers
- Retains general language understanding while correcting domain-specific facts
How we built it
We used LoRA-based parameter-efficient fine-tuning via Unsloth to adapt ERNIE-4.5 using a small, carefully curated dataset.
Key implementation details:
Structured prompts in an ERNIE-style format:
Entity → Attributes → Query → Answer
Answer-only supervision, where loss is applied only to answer tokens
Explicit Old vs New regime contrast pairs to break pretraining biases
LoRA adapters applied to attention and feed-forward layers for efficiency
This approach allowed us to override incorrect pretraining priors while training less than 1% of the model’s parameters.
Challenges we ran into
- Conflicting tax rules embedded in web-trained model priors
- Dependency instability in Colab due to rapidly evolving ML libraries
- Ensuring correct alignment for answer-only loss during tokenization
- Preventing overfitting while working with a small dataset
These challenges required careful dataset design and controlled fine-tuning rather than brute-force scaling.
Accomplishments that we're proud of
- Successfully corrected high-confidence factual errors in the base ERNIE model
- Achieved clear behavioral improvement using a small, targeted dataset
- Maintained model fluency while improving legal and regulatory accuracy
- Demonstrated the effectiveness of LoRA for domain-specific factual correction
What we learned
- Fine-tuning is not just about adding knowledge, but correcting confidence
- Small, high-quality datasets can outperform large noisy corpora
- Prompt structure plays a critical role in factual reliability
- Parameter-efficient methods are well-suited for regulatory domains
What's next for ERNIE fine-tuning using Unsloth
- Expanding coverage to additional tax sections and assessment years
- Incorporating retrieval-based verification for statutory references
- Adding confidence calibration for regulatory responses
- Deploying the model as an interactive tax advisory assistant

Log in or sign up for Devpost to join the conversation.