-
-

Why?
-

Landing
-
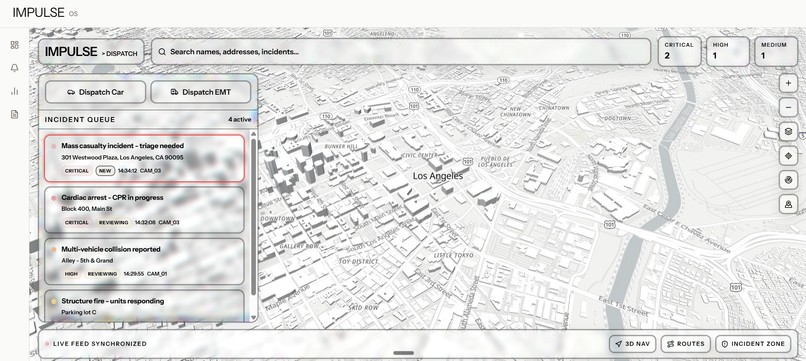
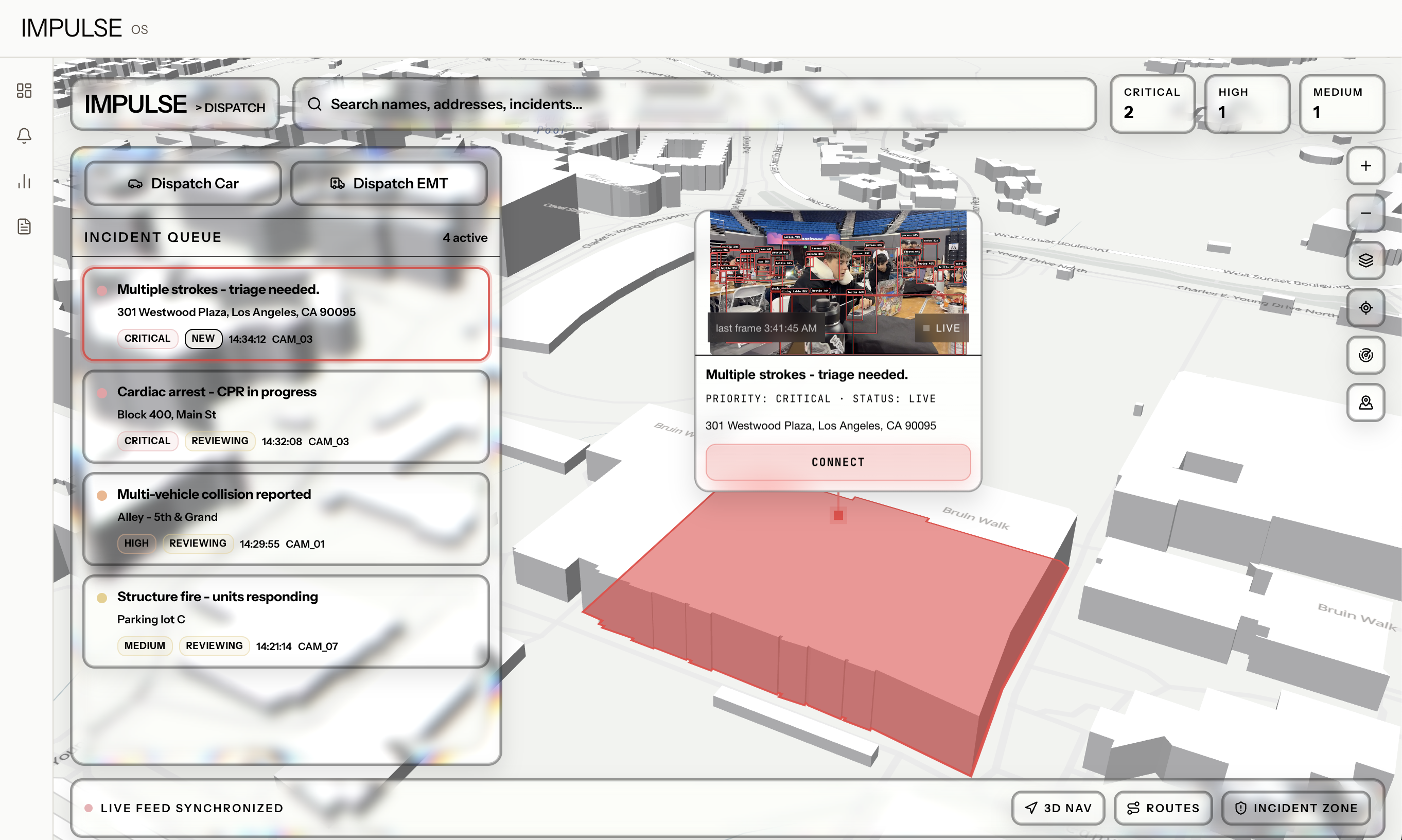
Dispatcher Overview
-
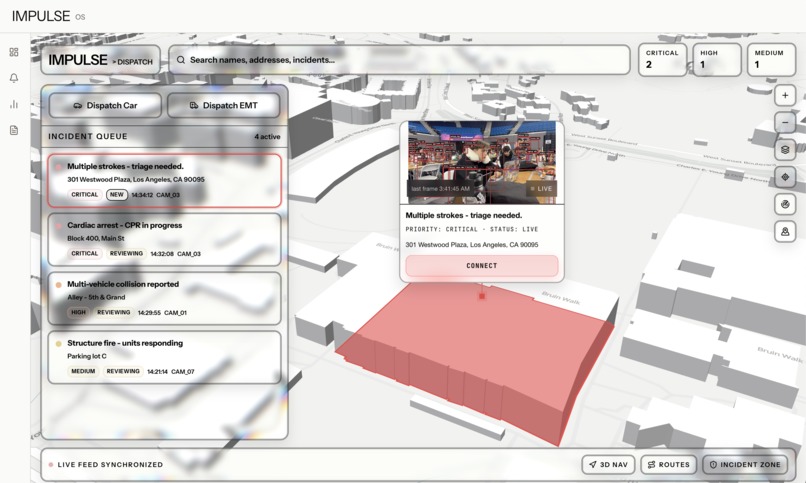
Incident Connection
-
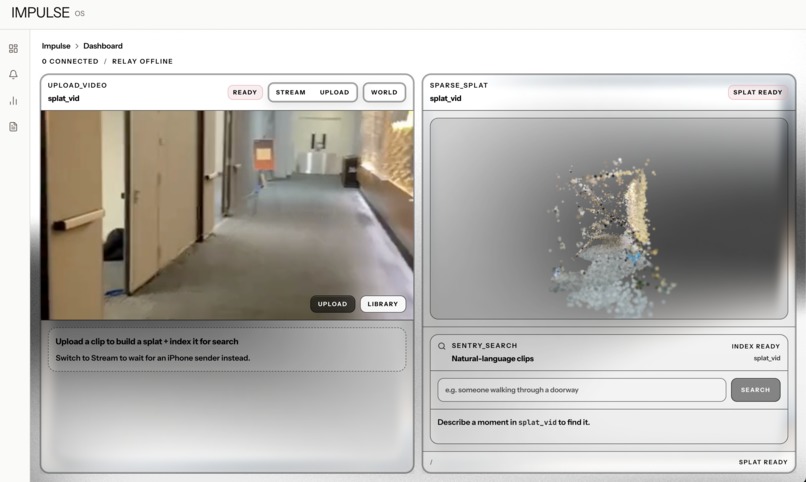
ColMap Escape Replay
-

Tech Design


IMPULSE: Real-Time Command Intelligence for Emergency Responders
Inspiration
When an emergency call comes in, seconds matter.
But the tools dispatchers and field commanders actually use today are shockingly fragmented: one screen for radio, another for maps, another for camera feeds if they're lucky, and no way to ask "what happened in that building five minutes ago?"
We wanted to build the command center we'd want if we were the ones coordinating a response. One unified interface that gives a dispatcher everything: live eyes on the scene, AI-powered situational awareness, searchable incident memory, and the ability to understand the space in three dimensions. All from a phone a first responder already has in their pocket.
The Problem
The stakes couldn't be higher:
- Every minute of delay = 7–10% lower cardiac arrest survival (German Resuscitation Registry / Resuscitation Journal)
- 240M EMS calls annually in the US alone, and dispatchers are overwhelmed (NENA, 2024)
- Cloud AI real-world round-trip latency: 800–2,400ms, dangerously slow for life-safety decisions (Oxmaint, 2025)
Today's systems are fragmented, cloud-dependent, and blind indoors. Responders are flying blind.
Here's the Issue
State consent laws vary widely and HIPAA strictly governs how protected health information can be recorded, stored, and shared. Traditional cloud-based bodycam systems have been nearly impossible to standardize across EMS agencies. But edge AI sidesteps this entirely by processing footage on-device. Sensitive patient data never leaves the camera in the first place.
The operational burden of crafting airtight storage policies, defining activation triggers, and managing who can access cloud-stored footage has deterred most agencies from deploying cameras at all. These challenges are completely eliminated by edge AI, leaving no footage to store, audit, or accidentally expose.
What It Does
IMPULSE is a real-time incident response platform that turns any iPhone into a smart body camera and gives commanders a live, intelligent picture of what's happening on the ground.
For the field responder (iOS app)
- Your phone acts as a wearable smart bodycam, supplying you with a local AI agent with memory. IMPULSE then streams live video back to the command center over WebRTC.
- YOLO object detection runs entirely on-device using ZETIC. No round-trip to a server, no latency.
- YAMNet listens to ambient audio and reasons about it in plain English: "Two people speaking urgently, glass breaking in the background" - not just labels, actual understanding.
For the dispatcher (web dashboard)
- Live Camera View: see what every responder sees, with AI model outputs displayed alongside each feed in real time
- Incident Alert Center: a prioritized queue of incoming alerts (critical / high / medium) overlaid on a 3D MapLibre map. Click any alert to fly the camera to that building. Dispatch a police unit or EMT with one button.
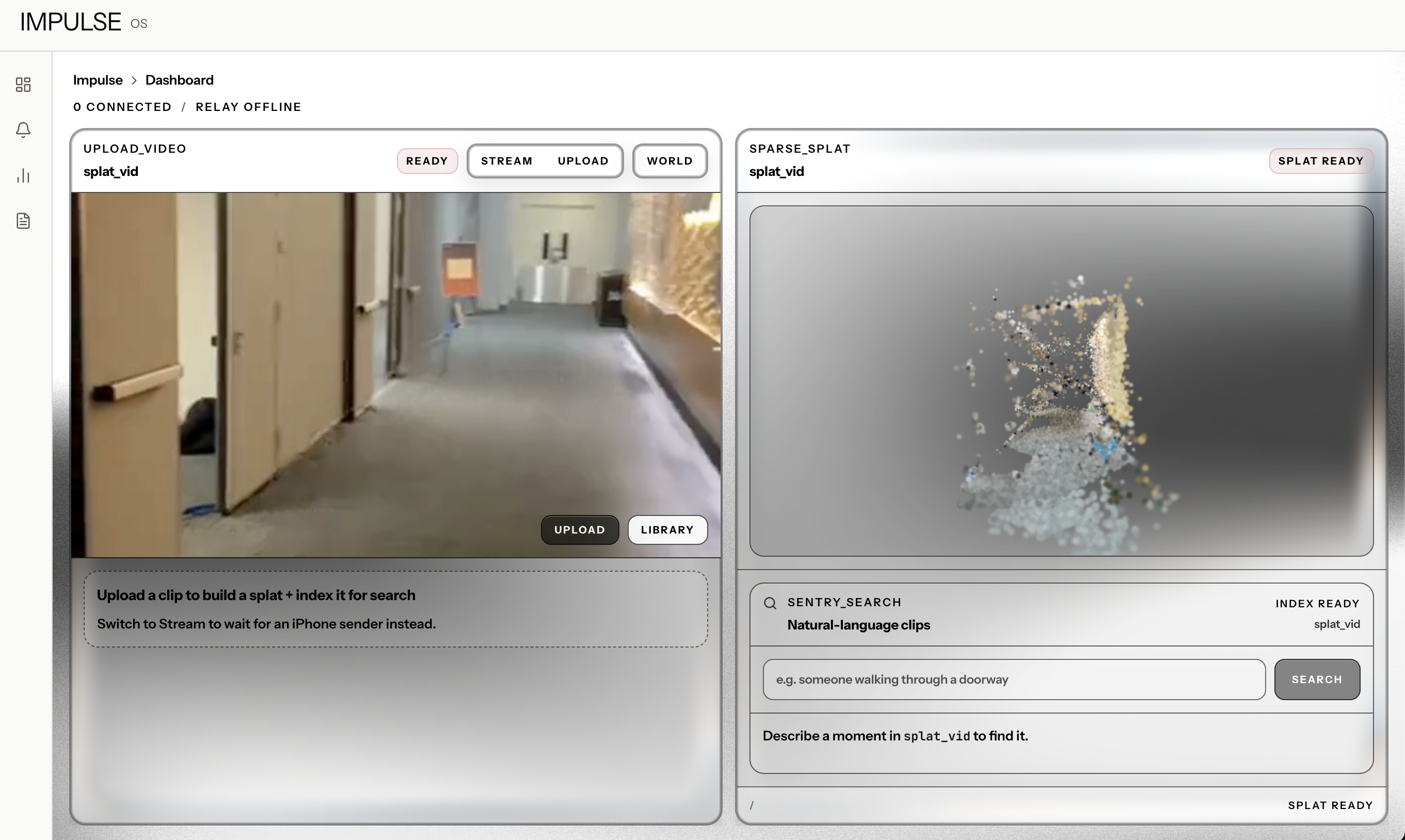
- Semantic Video Search: type "person on the ground" or "smoke in hallway" and get timestamped video clips back, pulled from every camera that has ever fed into the system. Like a Google search for your incident footage.
- 3D Scene Reconstruction: upload footage from the field and IMPULSE builds an interactive 3D point cloud of the space using COLMAP, viewable right in the browser with orbit controls.
All of this runs on an ASUS GX10 sitting on-site as the central hub, with no cloud dependency required for the core loop.
Why Edge AI Beats Cloud
| Concern | Cloud Processing | Edge AI (On-Device) |
|---|---|---|
| Patient privacy (HIPAA) | High risk: PHI leaves the device and travels over a network to third-party servers | Low risk: all inference runs on-device; no PHI ever transmitted |
| Data transmission | Raw video streamed to remote servers; interception risk during transit | No video leaves the device; only anonymized metadata or alerts shared if needed |
| Business associate agreements | Required with every cloud vendor that touches the footage under HIPAA | Not required: no third party handles PHI |
| Latency | Round-trip adds 800–2,400ms in real-world conditions; unsuitable for real-time decisions | Millisecond inference locally; supports real-time alerts and decision support |
| Connectivity dependency | Fails or degrades in areas with poor cellular coverage (rural EMS, basements, disaster scenes) | Fully offline-capable; works in any environment |
| Cost at scale | Ongoing cloud compute + bandwidth + storage costs per agency | One-time hardware cost; no recurring compute fees |
| Hospital handoff risk | Camera still uploading when entering the ED, capturing other patients' PHI | Processing stays local; no incidental capture of bystanders hits a server |
How We Built It
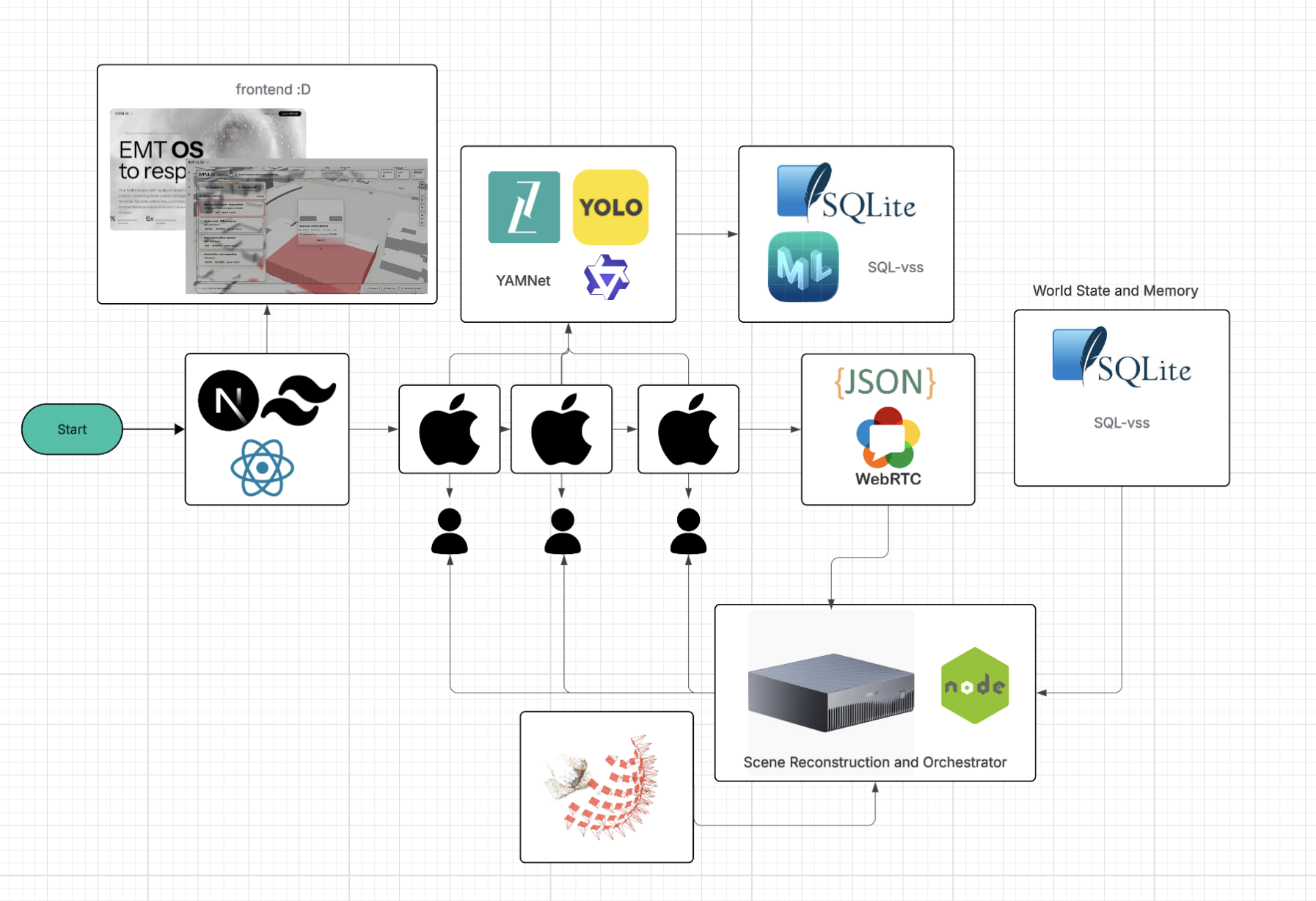
The system is a monorepo with four tightly integrated components:
iOS App: On-Device Intelligence
We used ZETIC Melange (v1.6.0), an SDK that compiles and runs ML models directly on Apple chips. This lets us run YOLO and Qwen2.5-Omni 3B on-device with no server round-trips.
The Qwen audio pipeline is a two-stage memory-swap architecture. The audio encoder and LLM decoder can't coexist in RAM on most phones, so we load the encoder, run it to get embeddings, unload it, then load the decoder and inject the embeddings via runWithEmbeddings. The result is a multimodal LLM doing real audio reasoning on a phone, streaming tokens in real time.
Frames and model outputs stream to the hub over WebSocket, upgrading to WebRTC when available for lower latency.
Semantic Search: PostgreSQL + OpenAI
Our indexing pipeline (scripts/index_videos.py) samples one frame every 8 seconds with ffmpeg, sends each frame to GPT-4o-mini for a vivid natural-language caption, then embeds that caption with text-embedding-3-small.
Those embeddings go into PostgreSQL + pgvector, alongside the timestamps, per-model text outputs (YOLO, STT, YAMNet), and the full raw JSONB payload. Search queries are embedded the same way and matched via HNSW cosine similarity. The result is a search engine that understands intent, not just keywords.
3D Reconstruction: COLMAP
For sparse reconstruction, we built a full COLMAP pipeline: ffmpeg extracts frames, then a feature extractor (DSP-SIFT, 24k keypoints/image), exhaustive matcher, mapper, and a point triangulator second pass to squeeze out more environment points. The output points3D.bin gets converted to our LBMP binary format and served directly from the GX10 for the dashboard to fetch.
Central Hub: ASUS GX10
The GX10 runs the frame relay server (Node.js WebSocket), the database API (FastAPI), and PostgreSQL. It's the single point of truth for the incident: all cameras connect to it, search queries hit it, and all model outputs land in it, with no cloud dependency for the core loop.
iOS App ──WebRTC/WS──▶ GX10 (frame relay + search API + Postgres)
iOS App ──JPEG frames──▶ GX10 (COLMAP 3D reconstruction)
GX10 ◀──────────────── Dashboard (Next.js)
Figma wireframes: https://young-spiny-52981385.figma.site/
Built With
- asus-gx10
- cloudinary
- colmap
- docker
- next.js
- python
- react
- typescript
- websocket
- zetic-melange











Log in or sign up for Devpost to join the conversation.