




EquiSense
Inspiration
While exploring the stock market ourselves, we realized how overwhelming it is for retail investors. Every day brings hundreds of news articles, Reddit discussions, and conflicting opinions, yet no simple way to understand overall market perception.
We wanted to build a tool that answers one clear question: “What does the market actually feel about this stock right now?”
That idea became EquiSense.
What It Does
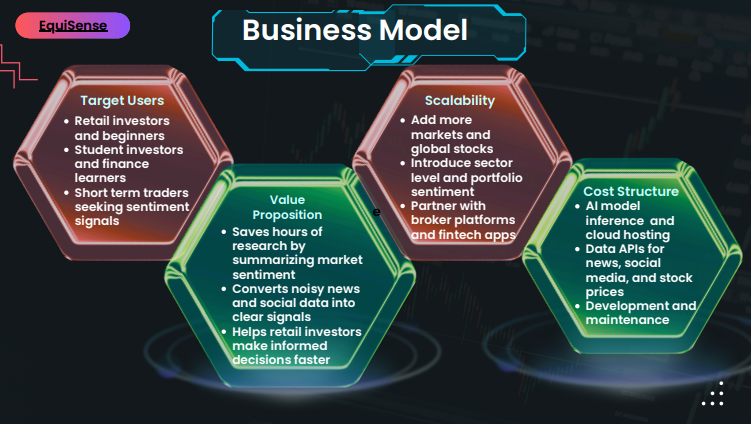
EquiSense is a real-time market sentiment analyser built for retail investors who don't have a research desk behind them.
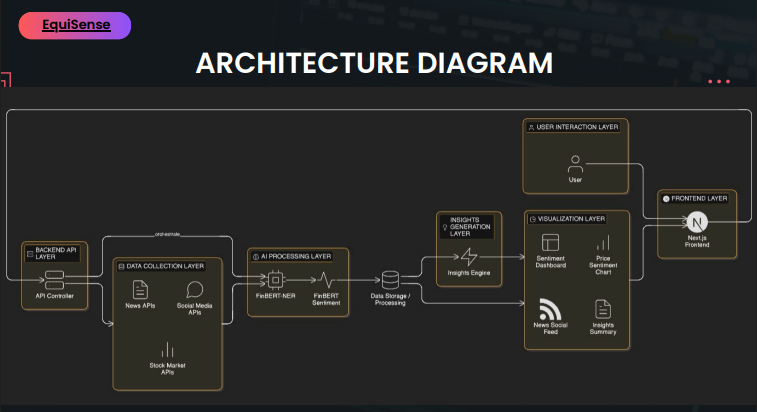
You type in any stock, index, or market topic, NIFTY 50, Reliance, IT sector, whatever you're tracking, and it pulls live news from multiple sources (GNews, NewsAPI, Finnhub, Bloomberg RSS, CNBC RSS) and runs every headline through FinBERT, a sentiment model trained specifically on financial language.
The output isn't just a score. It gives you:
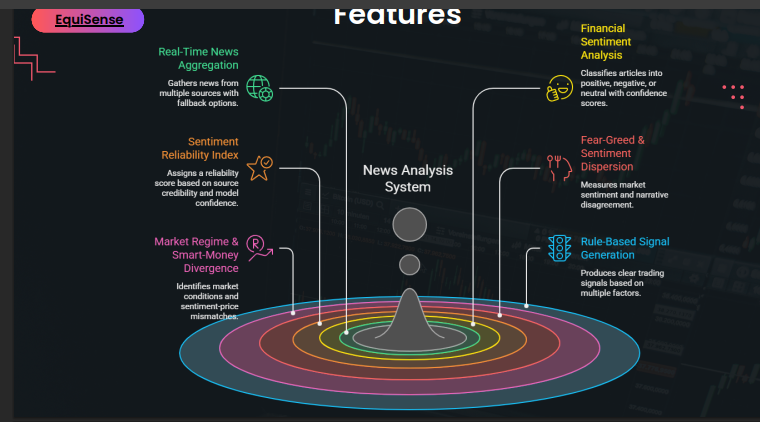
- A Fear / Greed / Neutral breakdown across all articles
- A Sentiment Reliability Index that weights results by source credibility, how recent the article is, and how confident the model is
- Market Regime Detection, whether the market looks Risk-On, Risk-Off, or Event-Driven based on VIX and sentiment dispersion combined
- Smart Money Divergence Alerts, when the news sentiment and the actual price movements are pointing in opposite directions, which is often when something interesting is about to happen
- A Gemini 2.5 Flash generated an analyst note that ties everything together into a plain-English summary with a suggested action
The whole thing runs in your browser, takes about 10 seconds, and costs nothing.
How We Built It
The core stack is Python, Streamlit, HTML and CSS, which let us move fast without getting bogged down. For sentiment, we went with ProsusAI's FinBERT over a general-purpose model because financial language is weird. "Cut" is usually bad, except when it's a rate cut, which is often good. "Volatile" sounds scary but can signal opportunity. General models get tripped up by this constantly. FinBERT was trained on financial news and earnings calls, so it handles the nuance better.
We built a data pipeline that hits five sources in parallel, paid APIs where we have keys, RSS feeds as a free fallback, and de-duplicates by URL so we're not double-counting the same story from syndicated feeds.
The Sentiment Reliability Index was something we designed ourselves. Raw sentiment percentages felt misleading, if you have 3 Bloomberg articles and 27 random blog posts, a 60% positive reading means very different things. So we built a weighted score: source credibility (Bloomberg = 1.0, random aggregator = 0.6), recency decay (articles older than 72 hours get low weight), and model confidence. That composite score is what we actually surface.
Market regime and divergence detection sit on top of that, using India VIX from yfinance combined with sentiment dispersion to classify what kind of market environment you're in.
Finally, we pipe a structured prompt to Gemini 2.5 Flash to generate the analyst-style summary. We deliberately constrained the prompt so it only talks about what you searched for. Early versions would go off on tangents about global macro when you just wanted to know about one stock.
Challenges We Ran Into
Getting FinBERT to actually run was the first wall. PyTorch doesn't install cleanly in every environment, and we spent more time than we'd like to admit debugging import errors and version conflicts before settling on a setup that works reliably. We also built a keyword-based fallback so the app doesn't just die if the model fails to load, not ideal for accuracy, but it keeps things functional.
RSS feeds are a mess. Bloomberg's feed structure changes, CNBC's summary fields are full of HTML tags, and feedparser handles malformed XML in unpredictable ways. We had to write custom cleaning logic and add enough try/except blocks that a bad feed silently fails instead of crashing the whole fetch pipeline.
The Gemini API deprecation caught us off guard. We started with google.generativeai, got a FutureWarning about it being deprecated mid-build, had to figure out whether to switch SDKs mid-project. We ended up sticking with the stable package and updating the model string to gemini-2.5-flash once we confirmed it worked.
Reliability of the sentiment itself is an ongoing challenge. FinBERT is good but not perfect. Headlines are short and context-light, which means edge cases are common. We don't have a clean solution, the SRI score is our way of being honest about uncertainty rather than pretending the output is more precise than it is.
Accomplishments That We Are Proud Of
Honestly, the thing we're most proud of is that it works end-to-end on real data. Not a demo with hardcoded outputs, actual live news being pulled, classified, and summarised in real time. For two first year ECE-AI students building a financial NLP tool from scratch, that felt like a real milestone.
The Sentiment Reliability Index is something we're genuinely happy with. It came from a frustration with how misleading raw percentages can be, and the fact that we designed a formula ourselves rather than just reporting model output makes it feel like our own contribution rather than just gluing APIs together.
The divergence detection also surprised us, when we tested it on historical news cycles, it flagged some genuinely interesting moments where sentiment and price were decoupled right before a significant move. That wasn't guaranteed to work and it did.
And the UI came out cleaner than either of us expected. We're engineers first, design is usually an afterthought. This time we actually paid attention to it and it shows.
What We Learned
We learned that financial NLP is genuinely hard in ways that general NLP is not. The domain specificity matters a lot, you cannot just throw a general sentiment model at market news and trust the output. Choosing FinBERT was the right call and we understand why now.
We also learned how to work with multiple async data sources and fail gracefully. The try/except architecture across the whole pipeline is not pretty code, but it's robust code, and we had to learn the difference.
On the product side, we learned that the output being trustworthy matters more than it being impressive. The SRI score exists because we kept asking ourselves "would we actually act on this?" and the answer kept being "depends." Building something you yourself would use forces a different standard of honesty.
What's Next for EquiSense
A few things we want to build that we didn't have time for:
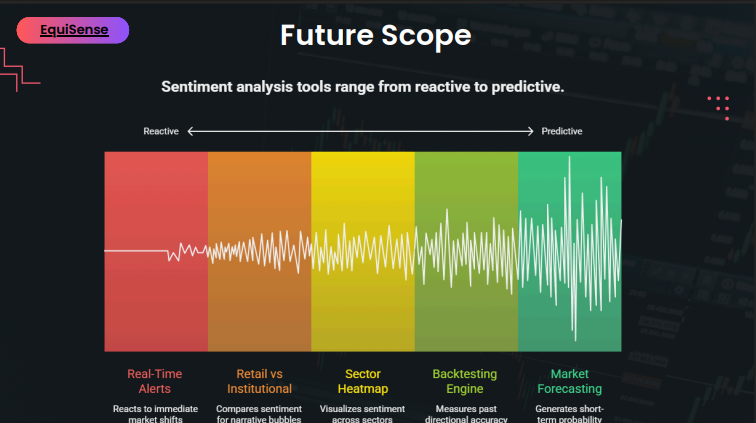
Portfolio-level sentiment. Right now you search one stock at a time. The next step is letting you drop in your entire portfolio and getting a consolidated sentiment view across all your holdings, which ones have deteriorating news flow, which ones are seeing positive momentum.
Alerts. Sentiment shouldn't require you to open a dashboard. A daily WhatsApp or Telegram message with the top sentiment shifts in your watchlist is the kind of thing that would actually change how retail investors stay informed.
Options flow integration. PCR is simulated right now because real-time NSE data isn't free. If we can get access to actual options flow data, the divergence detection becomes significantly more powerful.
Better backtesting. The directional alignment check in the current build is illustrative, not rigorous. We want to run it against actual historical data to understand where sentiment leads price and by how much, turning the conceptual signal into something with real predictive grounding.
Mobile. The Streamlit app works on mobile but wasn't designed for it. A proper React Native or Flutter app with push alerts would make this something people actually have open during market hours.
The core in,sight that retail investors deserve the same quality of sentiment intelligence as institutional desks, isn't going anywhere. This is just version one.

Log in or sign up for Devpost to join the conversation.