Inspiration
The traditional academic equivalency process is slow, manual, and inconsistent. Students transferring between universities or across countries often lose credits due to delays and subjective evaluation systems. Institutions spend weeks reviewing syllabi manually, creating administrative bottlenecks and financial loss for students.
Equira was inspired by the need to automate and standardize this process using semantic AI, transforming equivalency evaluation from a human-dependent workflow into a fast, data-driven system.
What it does
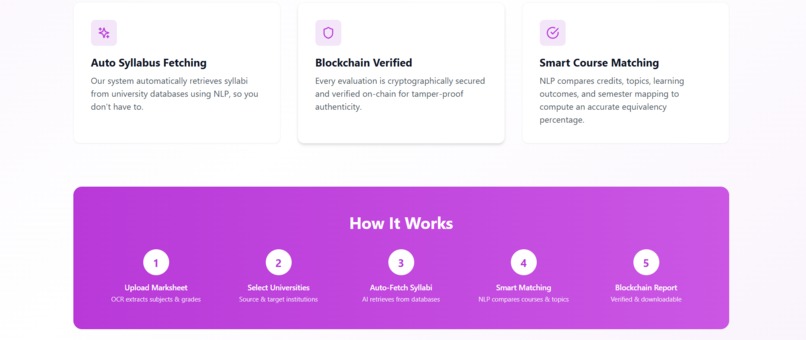
Equira is an AI-powered academic equivalency engine that compares course syllabi using semantic analysis.
It:
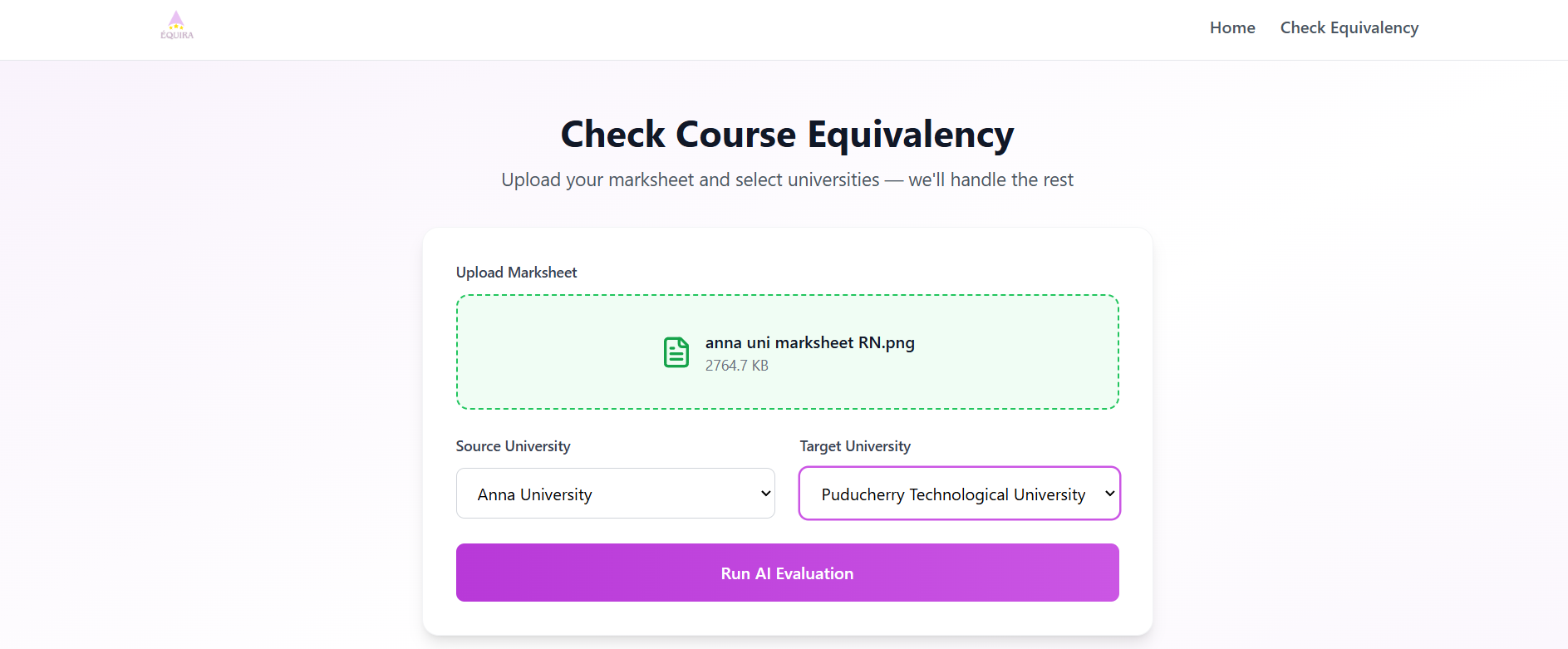
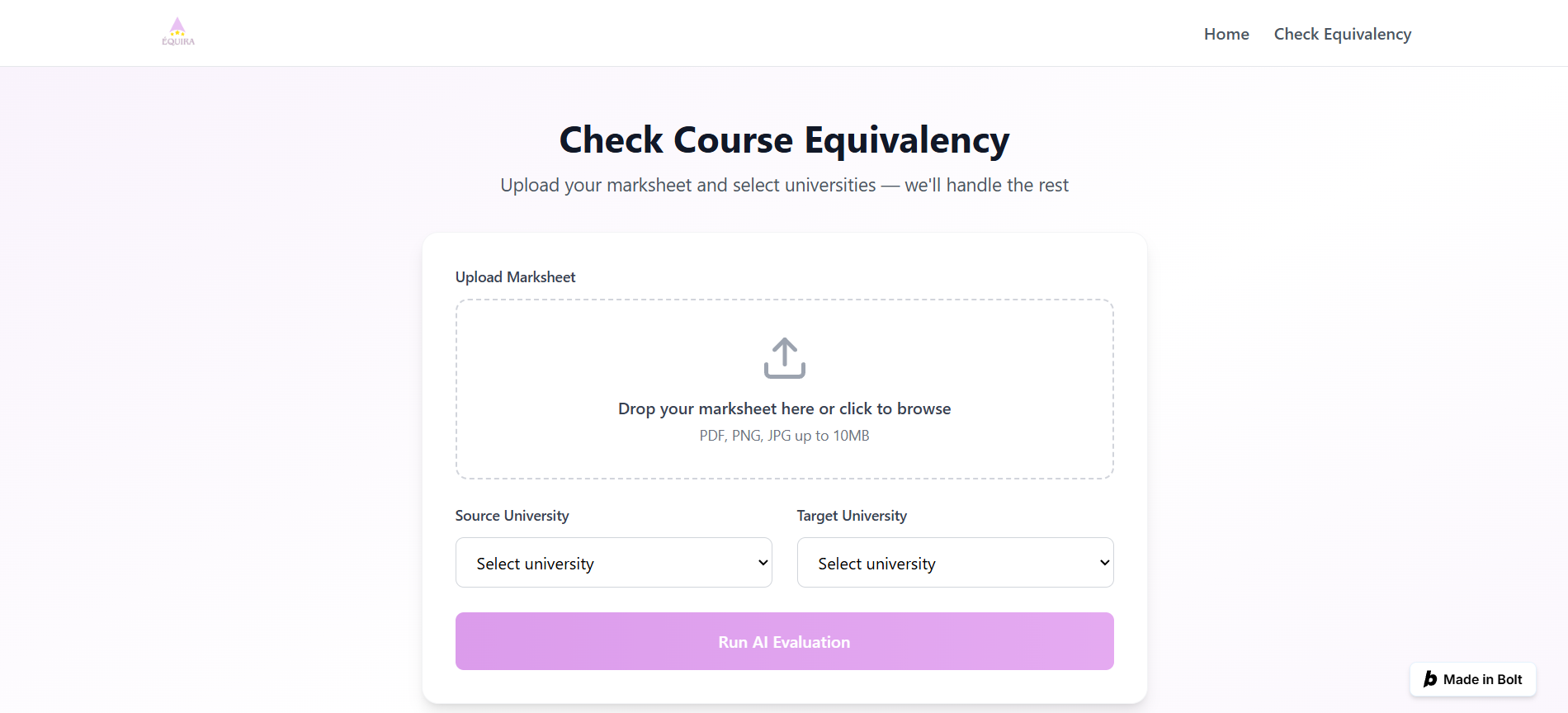
Accepts uploaded course syllabi
Extracts structured content using NLP
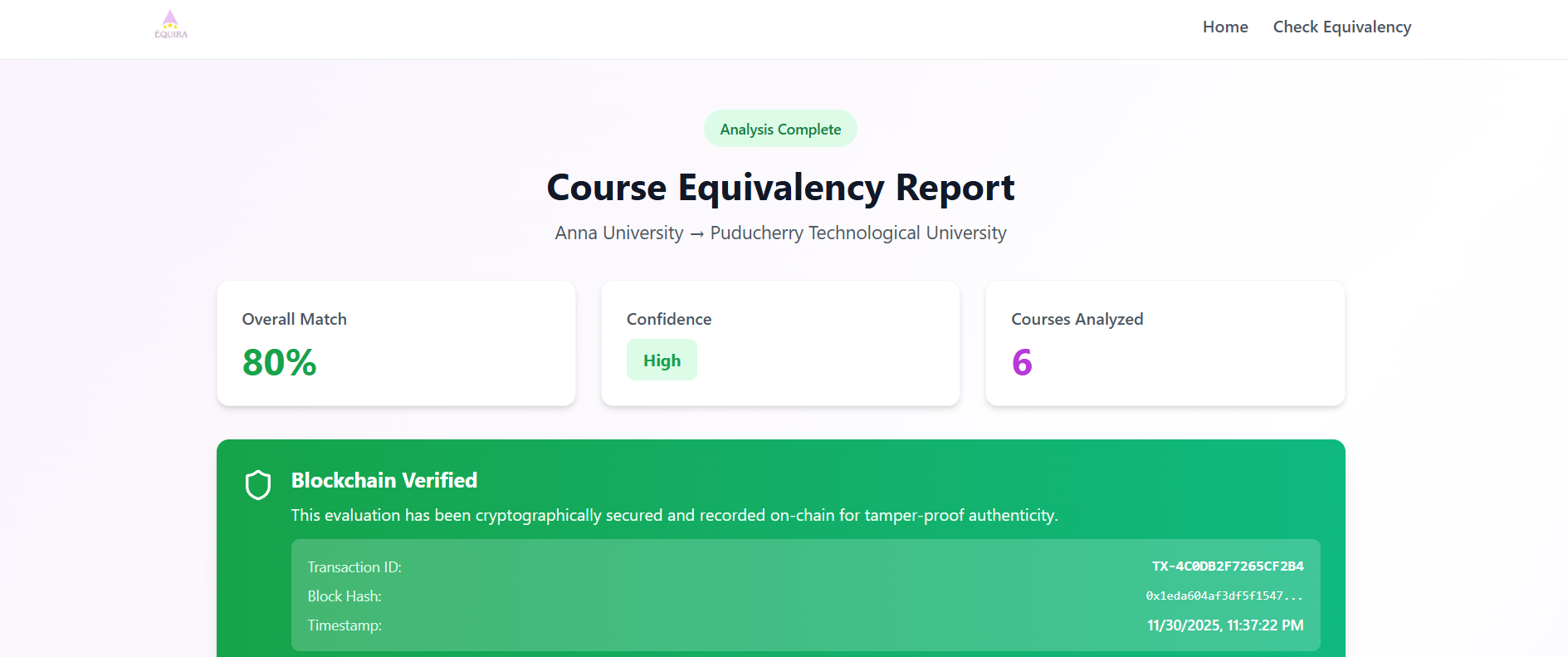
Computes semantic similarity using a fine-tuned language model
Generates equivalency scores and structured reports
The system reduces evaluation time from weeks to seconds while maintaining high consistency.
How we built it
We built Equira using:
A curated dataset of 10,000+ labeled course equivalency mappings
A fine-tuned BERT-based model adapted to academic content
Python backend for model inference
React-based frontend for uploading and viewing results
Secure hosting for demonstration and testing
The model was trained on labeled equivalency pairs and evaluated using train/test splits to measure generalization performance.
Challenges we ran into
Cleaning and structuring academic syllabus data from inconsistent formats
Creating labeled equivalency pairs with clear validation criteria
Ensuring the model generalizes across different universities
Avoiding overfitting during fine-tuning
Building a functional MVP while managing limited infrastructure
Accomplishments that we’re proud of
Successfully building a working MVP interface
Fine-tuning a domain-specific semantic model
Achieving strong performance on labeled evaluation data
Structuring a scalable architecture for future institutional deployment
Filing intellectual property related to the equivalency evaluation framework
What we learned
Academic data is messy and requires significant preprocessing
Domain adaptation is critical for meaningful semantic matching
Clear labeling standards improve model performance significantly
Early prototyping accelerates clarity and iteration
Validation metrics must be carefully interpreted to avoid overconfidence
What’s next for Equira
Expand the labeled dataset for broader coverage
Improve generalization across international universities
Deploy a production-ready SaaS infrastructure
Onboard pilot institutions
Develop institutional dashboard and API integrations
Transition from prototype to revenue-generating platform
Built With
- ai










Log in or sign up for Devpost to join the conversation.