-
-
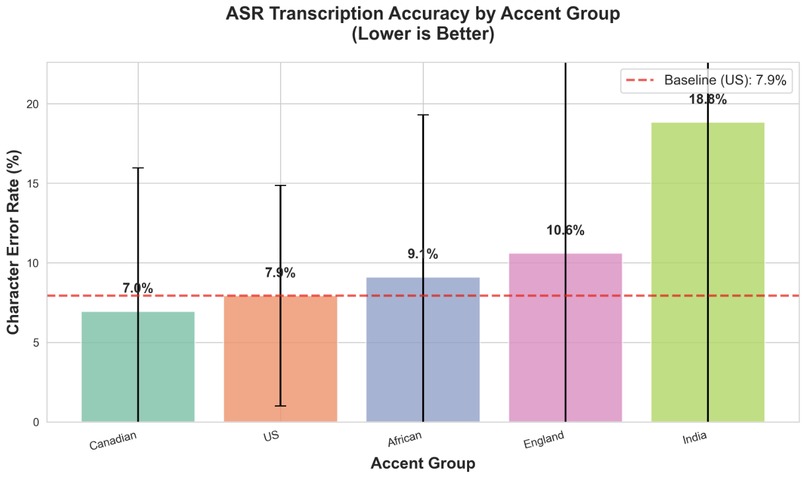
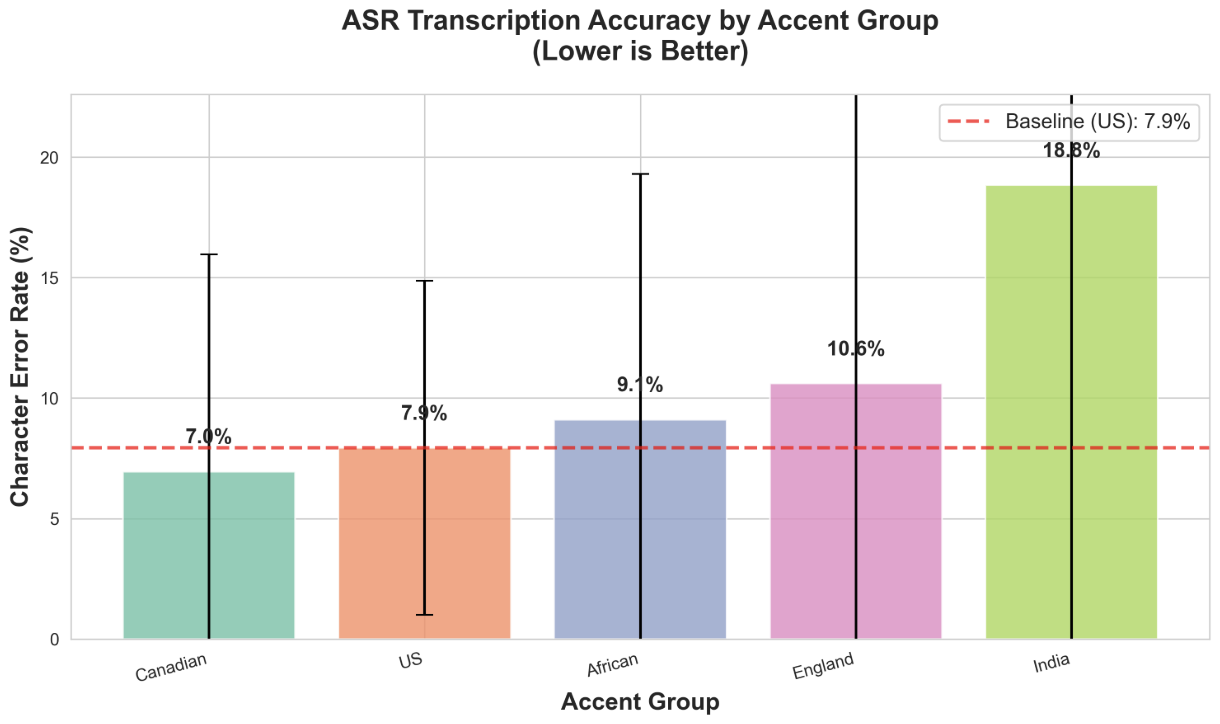
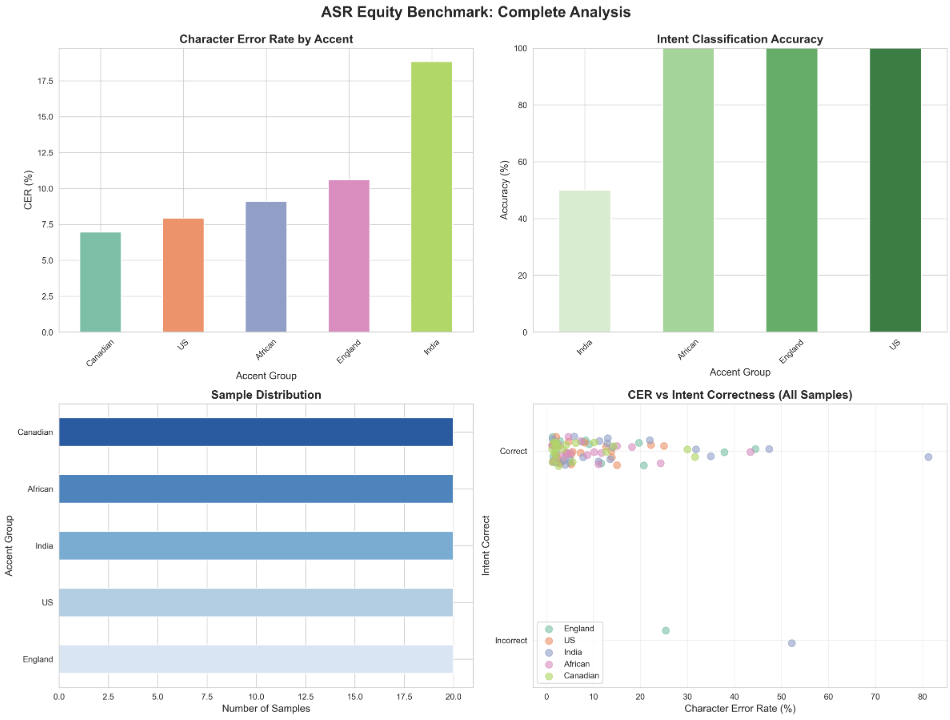
One of the graphs generated by our audio benchmarking algorithm that displays transcription accuracy by demo group
-
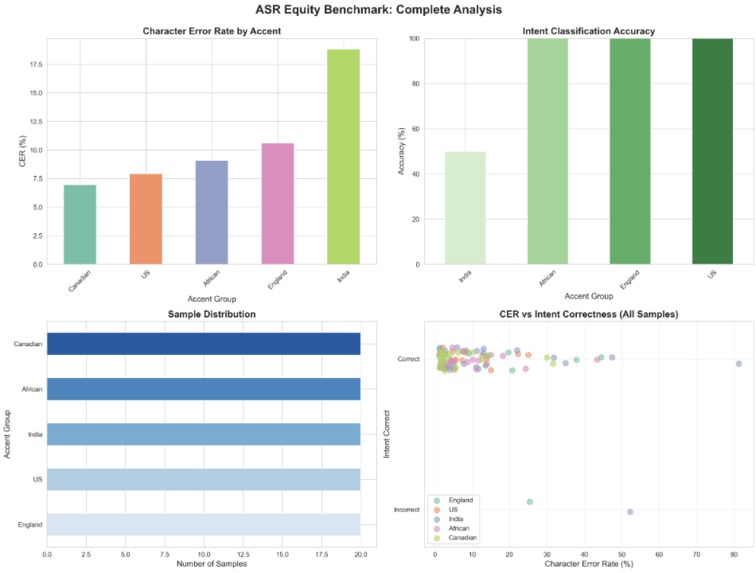
Equality benchmark generated by our algorithm
-
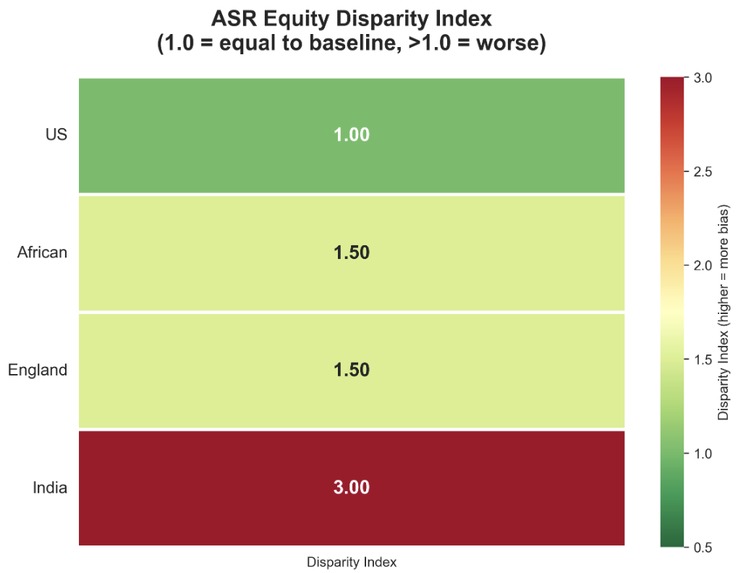
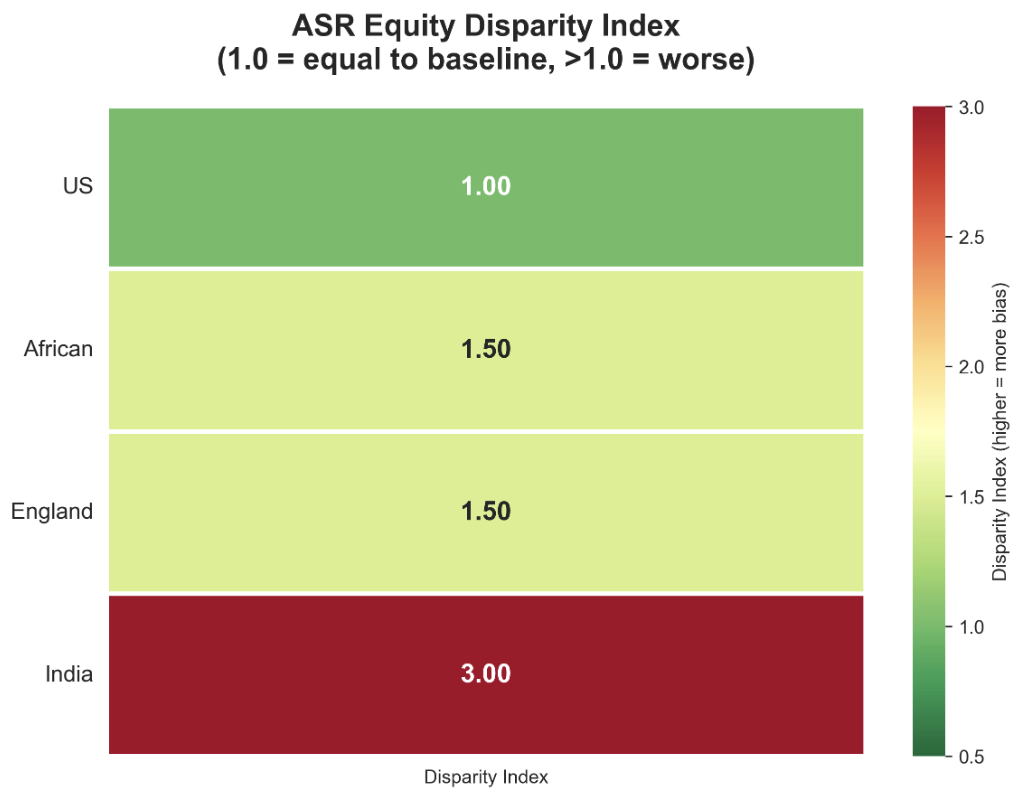
Equity disparity index generated by our algorithm
-
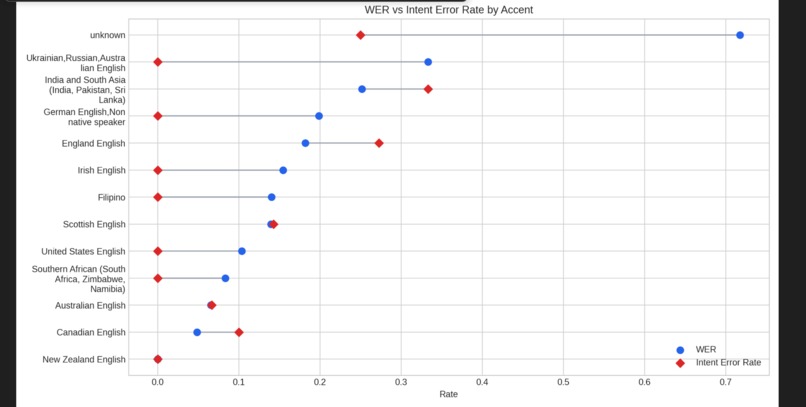
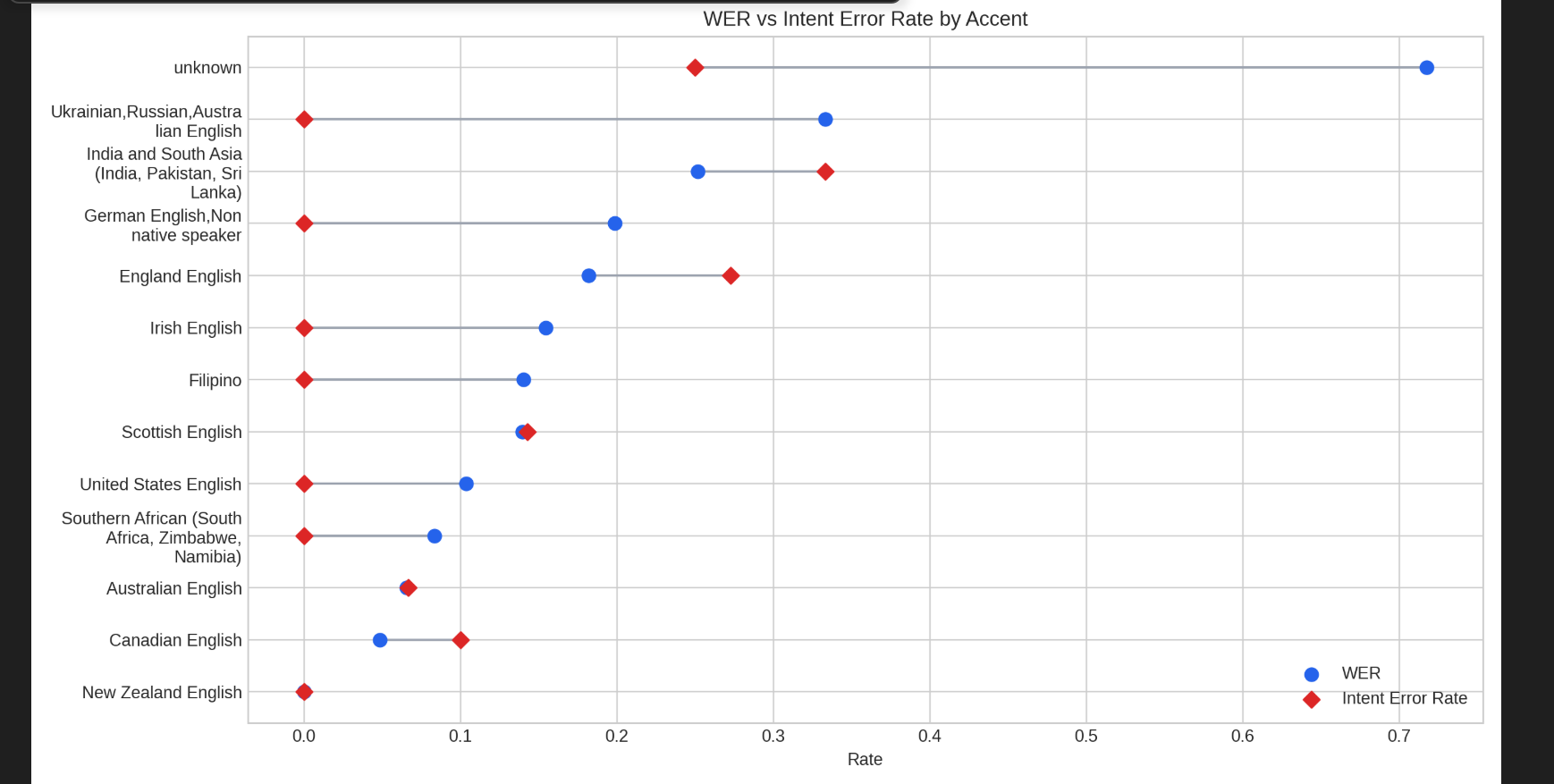
WER vs IER rate generated by our algorithm
-
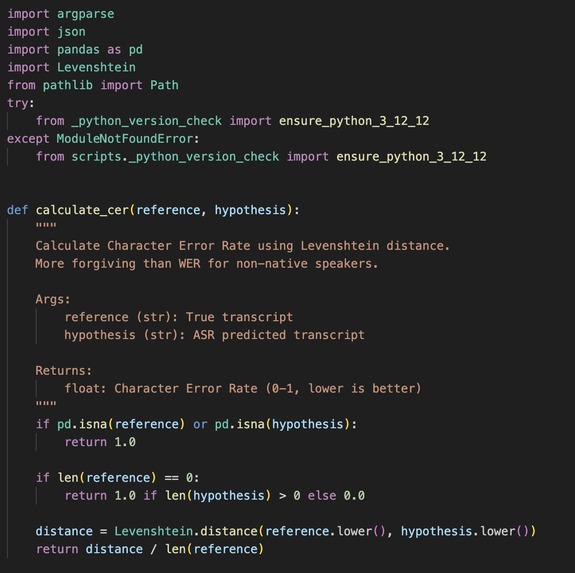
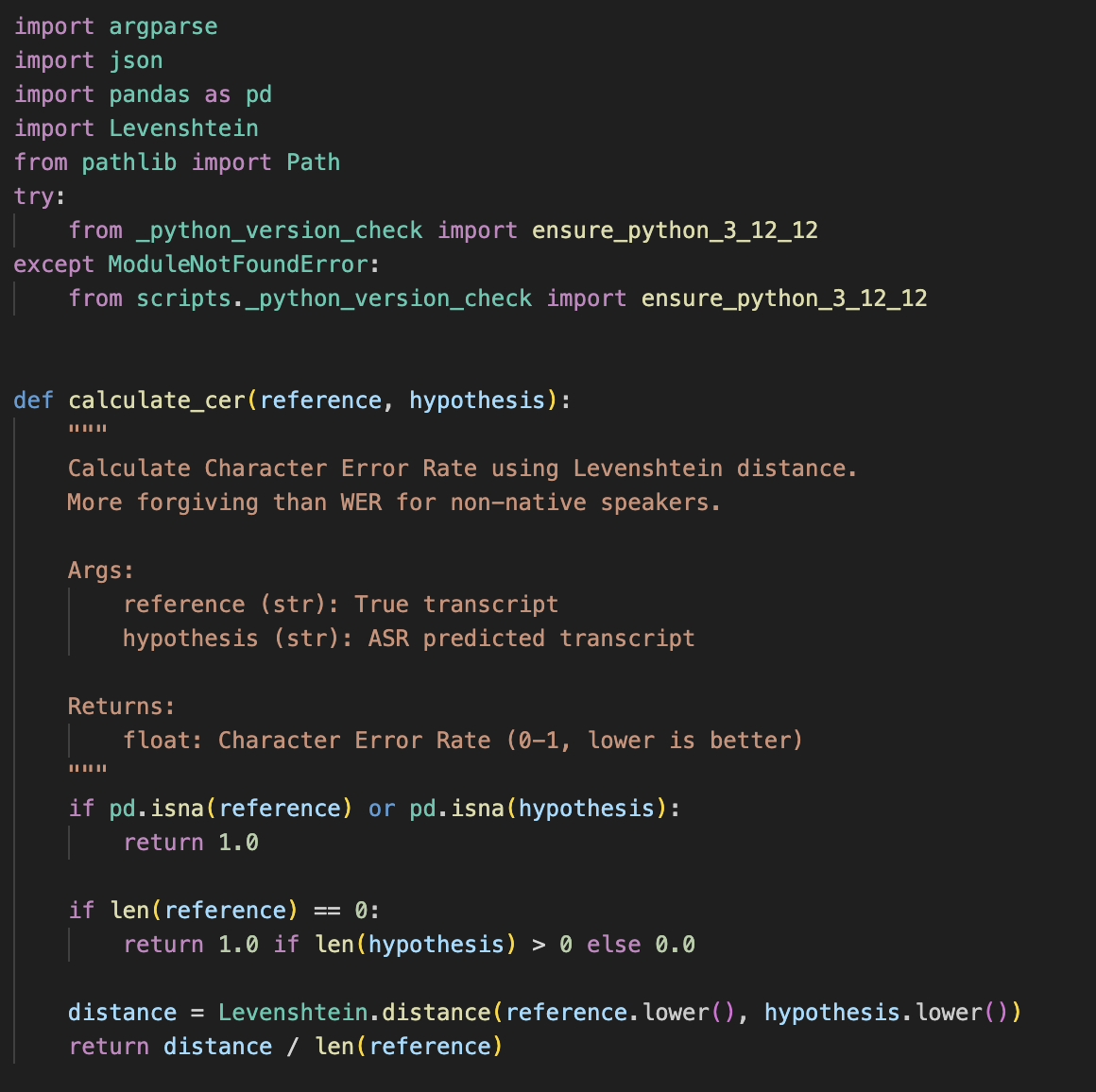
Small snippet of our word error rate calculation algorithm
-

Societal impact calculations and planning whiteboard
-
Speech to text transcription used to catch errors in transcription using our algorithm
-
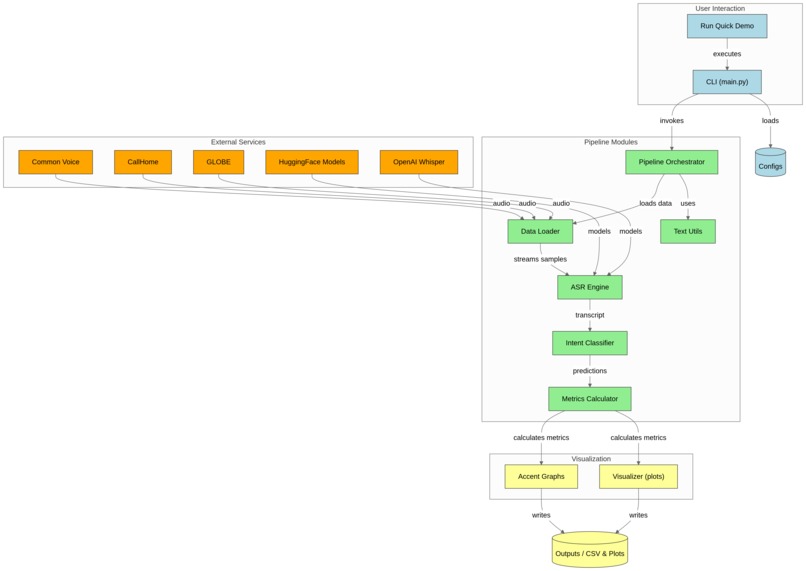
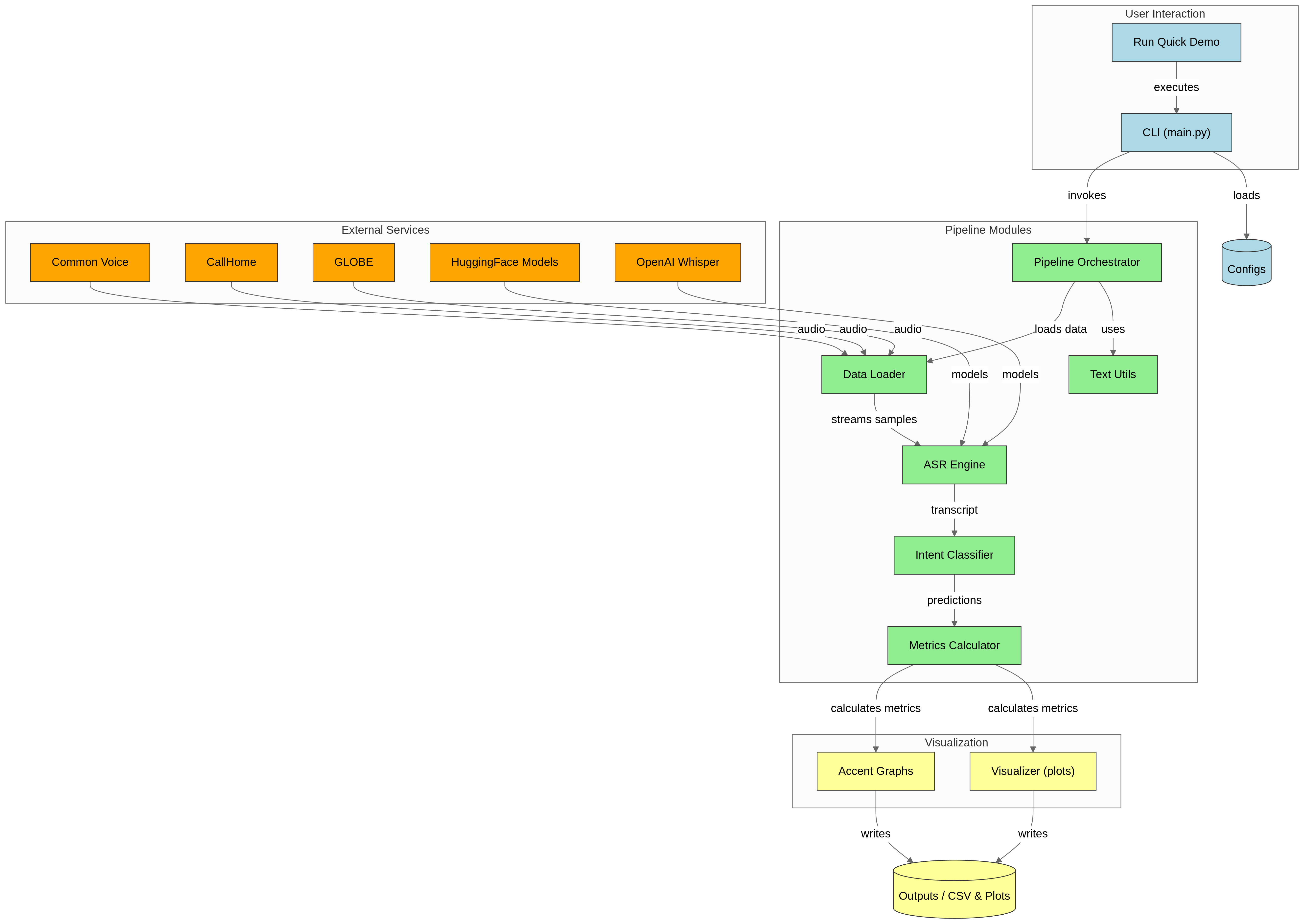
UML model

Inspiration
We come from immigrant families, and one of our teammates, Richard, moved from China three years ago. He and our parents regularly struggle with automated phone systems that fail to understand accented speech. These aren’t edge cases—they’re everyday experiences. EqualVoice was inspired by seeing how voice AI systems that claim high accuracy still systematically fail people like our families. We realized that these small misunderstandings have huge consequences: banks and businesses lose billions every year due to misinterpreted calls. For example, Bank of America is estimated to lose $3.2 billion annually from customer service inefficiencies, while companies that misinterpret just two calls a day can lose over $8,800 per year. Studies show that 27% of customers abandon voice calls, and 75% of them do so because they feel misunderstood.
⸻
What it does
EqualVoice benchmarks how speech recognition errors disproportionately affect accented speakers and tracks how these errors cascade into downstream failures such as incorrect intent classification, misrouted calls, and increased resolution time. It transforms abstract metrics like word error rate into real-world consequences, quantifying both access inequity and operational cost. By connecting transcription errors to measurable impact, EqualVoice shows businesses exactly where their voice AI systems fail their most vulnerable customers.
⸻
How we built it
We worked with terabytes of open speech data spanning thousands of audio recordings to simulate realistic customer support scenarios. Audio was processed through an ASR pipeline, followed by intent classification and routing logic. Performance was evaluated using word error rate, intent error rate, and a disparity index comparing accented and non-accented speakers. Because of scale constraints, we engineered a sampling and caching strategy to extract small but statistically meaningful subsets for fast iteration and demos. Our pipeline was designed to run end-to-end while still being realistic enough to capture real-world failures.
⸻
Challenges we ran into
Handling massive audio datasets was one of our biggest challenges. Storage limits, slow preprocessing, corrupted files, inconsistent labels, and compute bottlenecks forced us to rethink our pipeline multiple times. Fair benchmarking required careful controls, as small mistakes could exaggerate or hide bias. Translating model-level errors into real-world impact metrics was especially difficult, and simulating realistic customer interactions while keeping the system fast enough for a demo added another layer of complexity.
⸻
Accomplishments that we’re proud of
We are a group of high schoolers who built an end-to-end, realistic benchmark that quantifies how speech recognition errors impact real people and real businesses. We processed thousands of audio recordings, designed a scalable pipeline under tight compute constraints, and showed how small transcription gaps compound into significant downstream failures. We delivered a polished, demo-ready system grounded in authentic data and metrics, demonstrating that even young developers can tackle complex, socially meaningful AI challenges.
⸻
What we learned
We learned that bias in voice AI is often invisible at the surface level. Minor increases in error rates can compound into major barriers when systems rely on multiple automated decisions. Evaluating fairness requires an end-to-end approach, connecting technical errors to human impact. Accurate systems are not enough; equitable systems must be measured, too.
⸻
What’s next for EqualVoice
Next, we plan to expand accent coverage, benchmark additional models, and integrate EqualVoice into continuous evaluation workflows for voice AI teams. Our goal is to make accent equity a measurable standard rather than an afterthought, helping businesses improve access for all customers while minimizing operational losses.

Log in or sign up for Devpost to join the conversation.