-
-
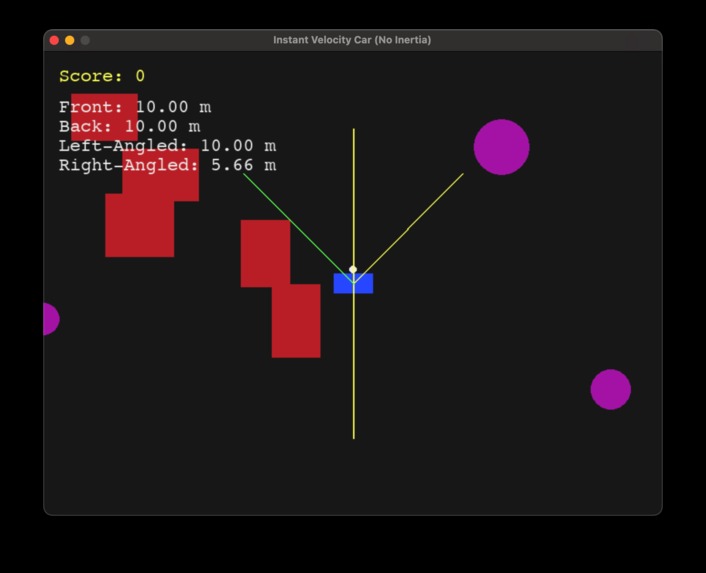
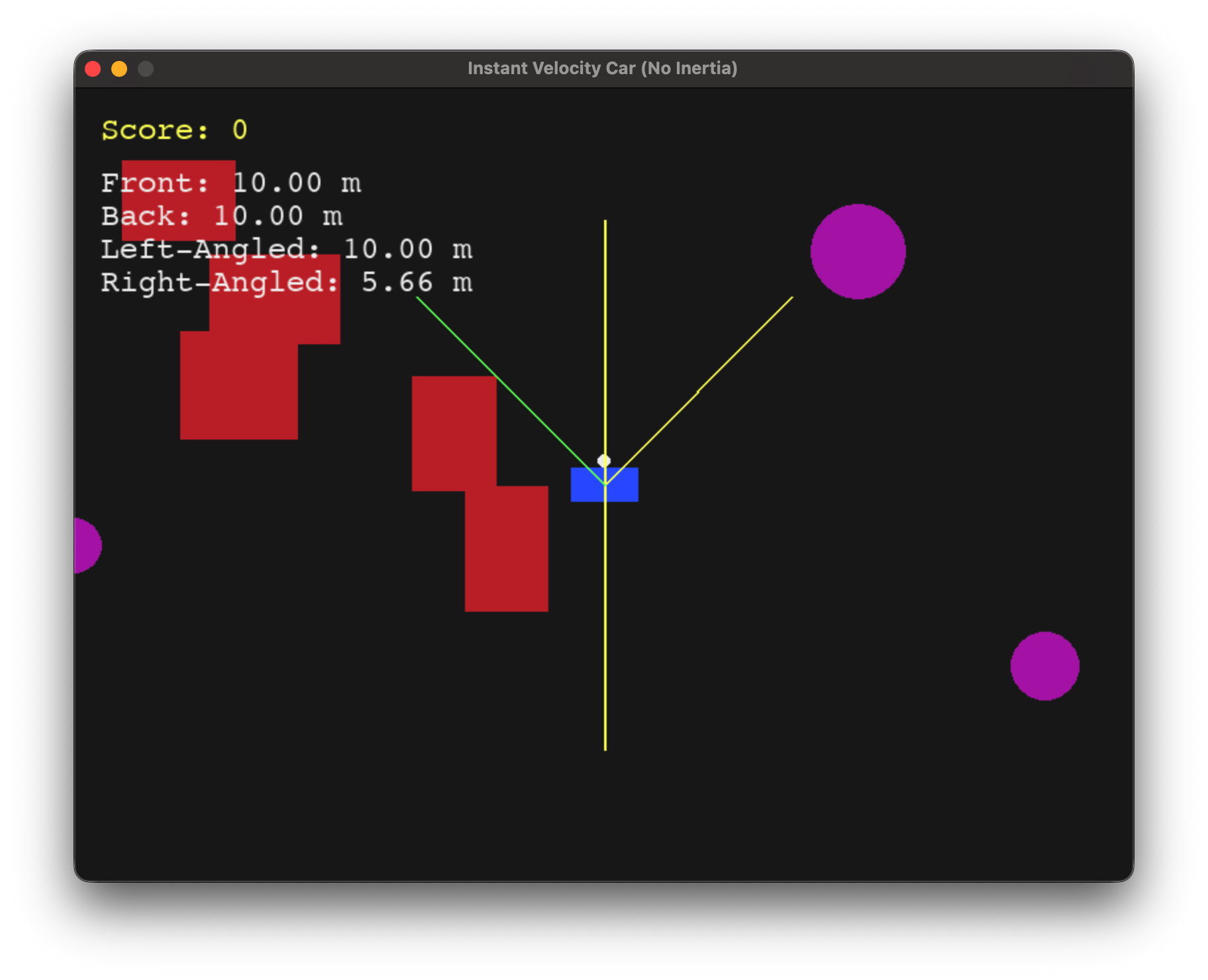
the agent(blue) with 4 sensors and obstacles(red+pink)
Inspiration
This project is inspired from the papers -"Learning Latent dynamics for planning for pixels", "World models", "Thousand brains Theory" and "The free energy principle: an unified brain theory"
What it does
The project teaches an AI model to navigate a car around its obstacles in a 2D simulation using a neural state space model for state prediction and a controller for action policy mapping - both work by minimising an elementary custom version of Friston's free energy to reduce uncertainty.
How we built it
We built an infinite world with pygame where there is a car (represented by a blue rectangle) and red+pink obstacles. We used Box2D as the physics engine to drive the dynamics of the system and as the system's input we added 4 ray casts that can measure up to 10m (one on the front, one rear and 2 angled at 45 degrees to the front) and 5 possible actions were defined as one-hot vectors, where each can be attempted one at a time - [fwd, rev, rotate_left, rotate_right, stop]. Once developed, we wrapped this in gymnasium to custom-fit an output for model training. We chose NSSM as our dynamic model architecture whose input would be the 4 raycast signal + action embedding. No encoder was chosen since the input dimension is low - we chose a GRU with 256 vector hidden state as the transition model along with a simple decoder to get the observations, or here the next predicted 4D signal array. For the controller model, we kept a policy-based network for simplicity: where for each predicted state, all possible next 3 actions are rolled out and the best action is sampled from these. For sampling and training we use a custom Friston formula and aim to reduce it. The free energy at time t is defined as the sensory prediction error (the squared difference between actual and predicted observations) minus a reward term. The reward term includes four weighted components:
A bonus for forward direction distance to encourage forward movement A term based on the exponential of the negative average distance across all sensors A penalty term based on the exponential of the negative minimum distance to avoid getting too close to obstacles A balance term measuring the absolute difference between left and right distances to maintain centered navigation
The bias term for the forward direction is added to increase the action entropy and promote exploration rather than running into a local minimum. The dynamics model is trained through backpropagation of the Friston function. The free energy combines the sensory prediction error with a reward function based on the action and predicted next observation. We define an objective function as the expected value of this free energy over time. The training involves computing three sets of gradients:
The gradient with respect to the controller parameters (theta) measures how the free energy changes when we adjust the action selection The gradient with respect to the dynamics model parameters (phi) captures how prediction errors propagate through both current and next observations The gradient with respect to the hidden state captures how future predictions depend on the current internal state
We then update all three components - the controller parameters, dynamics model parameters, and hidden state - by taking steps in the direction that reduces the free energy, with each having its own learning rate. This trains the model to minimize prediction errors, while the action policy runs each action through the rest of the terms and compares the total energy generated over the 5 possible actions and chooses the best action which is followed through for the next frames. This is simple yet works good enough to reduce the uncertainty without increasing load on systems - a better planner would be the Cross Entropy Method (CEM). Now we train the model to learn to minimise this Friston energy as much as possible to finally reach autonomous navigation. We used active inference for training: although not perfect and the model sometimes faces a dilemma between 2 actions whose energy score is similar, and execution depends on the initial training, this is a valid proof of concept.
Challenges we ran into
The model mostly decided to stick to one action repeatedly after hitting a local minimum until the bias term fixed it. The original GRU was very simple and had no action vector embedding leading to unforeseen maneuvers and moves undesired. The action policy was way more complicated than this and it made performance slow and redundant.
Accomplishments that we're proud of
The model seems to train much faster through using much less data: the working file uses 512 replays to be enough to train this model to learn the navigation. The model follows no reinforcement learning policy and learns to reduce uncertainty much like our brains.
What we learned
Learned about the current best framework about neocortex-intelligence part of the brain, what Friston free energy is, what world models are, what is an RSSM and NSSM and SSM, determinism vs probabilistic nature of the world we live in.
What's next for Epsilon
To improve upon this by replacing action policy with policy network, generalise this to all domains of robotic motion, include real world uncertainty through Gaussian probability distributions rather than deterministics, use the more known probabilistic version of the energy, replace NSSM with RSSM and finally, incorporate path finding and goal directed movements inside this.

Log in or sign up for Devpost to join the conversation.