
Epistemiq: The Voice-Driven Scientific Truth Engine
💡 Inspiration
In the modern digital landscape, misinformation travels faster than truth. We call this the "Epistemic Fog"—a state where rumors, viral tweets, and pseudoscience obscure actual knowledge.
We realized that while fact-checking tools exist, they are often static, text-heavy, and disconnected from the way people actually consume information today. We wanted to build something that feels less like a database and more like a highly intelligent research assistant—one you can talk to.
Inspired by the concept of a "Scientific Iron Man Jarvis," we asked: What if you could speak a rumor into your phone, and an AI agent would instantly cross-reference it against 200 million scientific papers and deliver a verified audio briefing?
🤖 What it does
Epistemiq is a voice-enabled cognitive agent that verifies claims against scientific literature.
- Listen: The user speaks a claim (e.g., "I heard that scientists found evidence of lightning on Mars").
- Extract: Google Gemini (Flash 2.0) acts as the reasoning engine, extracting testable assertions from the raw speech.
- Research (RAG): The system performs a parallel search across Semantic Scholar, PubMed, CORE, and CrossRef.
- Rerank: Using Google Embeddings, we semantically rerank the papers to find the most relevant evidence.
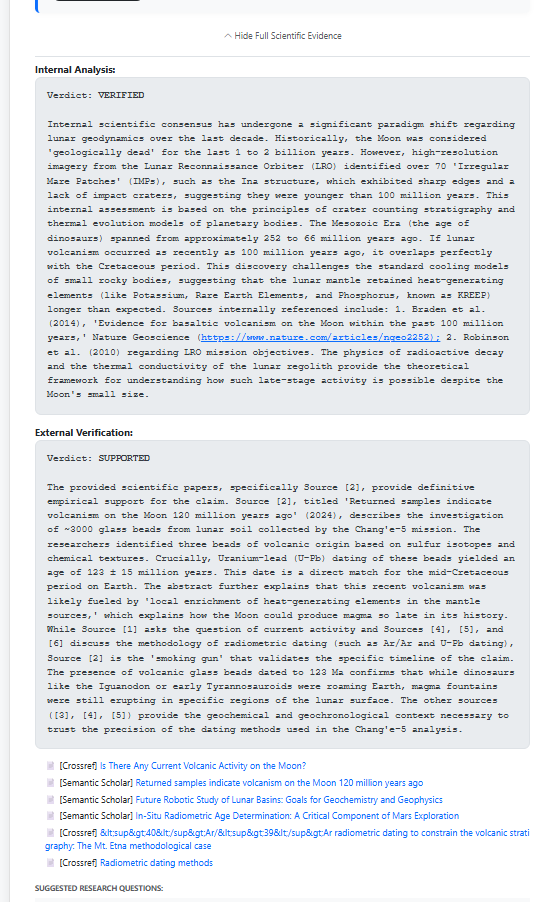
- Verify: Google Gemini Pro synthesizes the papers to issue a verdict (Verified, Debunked, Unproven).
- Speak: Finally, ElevenLabs converts the complex synthesis into a natural, podcast-style audio briefing, completing the conversational loop.
⚙️ How we built it
We built Epistemiq using a hybrid architecture that combines the speed of local browser APIs with the power of Cloud AI.
1. The Voice Interface (ElevenLabs + Web Speech)
We wanted zero friction. We used the Web Speech API for low-latency Voice-to-Text input. For the output, we integrated ElevenLabs Turbo v2.5. This was critical—scientific abstracts are dense and hard to read. ElevenLabs turns them into an engaging narrative, giving the AI a voice of authority.
2. The Brain (Google Cloud AI)
We utilized Google Gemini 2.0 Flash for high-throughput claim extraction and Gemini 2.0 Pro for the complex reasoning required to interpret academic papers.
3. The "Truth Layer" (Vector RAG)
We didn't want the AI to hallucinate, so we built a custom RAG (Retrieval-Augmented Generation) pipeline. We store claim embeddings in a PostgreSQL database using pgvector.
We used Google's text-embedding-004 model to generate 768-dimensional vectors. To ensure relevance, we implemented a Cosine Similarity ranking algorithm manually in Python:
$$ \text{similarity} = \frac{A \cdot B}{|A| |B|} = \frac{\sum_{i=1}^{n} A_i B_i}{\sqrt{\sum_{i=1}^{n} A_i^2} \sqrt{\sum_{i=1}^{n} B_i^2}} $$
This allows us to match a user's spoken slang (e.g., "Mars lightning") with dense academic phrasing (e.g., "Triboelectric discharge in Martian dust plumes").
🚧 Challenges we ran into
- The Rate Limit Wall: Google's Pro models have strict rate limits on the free tier. We architected a Hybrid Fallback Controller that attempts to use the most powerful Google model first, but seamlessly degrades to faster/smaller models (Flash or OpenRouter) if quotas are hit, ensuring the user never sees a crash.
- Vector Dimension Mismatch: We initially prototyped with local 384-dim embeddings but switched to Google's 768-dim embeddings for better accuracy. This required a complete database schema migration and hot-swapping the live production database on Neon without downtime.
- Streaming Latency: Generating a full report takes time. We implemented Server-Sent Events (SSE) to stream the text verdict word-by-word to the frontend while the ElevenLabs audio buffer was being prepared.
🧠 What we learned
- Voice changes the UX: When an app speaks back to you with the quality of ElevenLabs, it shifts from being a "tool" to being an "agent." The emotional connection to the veracity of the data increases.
- RAG is harder than it looks: Keyword search isn't enough for science. Semantic reranking was the breakthrough that allowed us to find relevant papers even when the user used imprecise language.
🔮 What's next for Epistemiq
- Conversational Follow-up: We are currently implementing a feature where the ElevenLabs agent asks, "Would you like to know more about the specific voltage mechanisms?" and listens for the user's response to generate a deep-dive report.
- Real-time Debate Mode: A mode that listens to a live YouTube video or debate and fact-checks claims in real-time.
Built With
- bootstrap
- docker
- elevenlabs
- flask
- google-cloud
- google-gemini
- javascript
- neon
- pgvector
- postgresql
- pubmed
- python
- pythonanywhere
- semantic-scholar-api
- web-speech-api

Log in or sign up for Devpost to join the conversation.