-
-
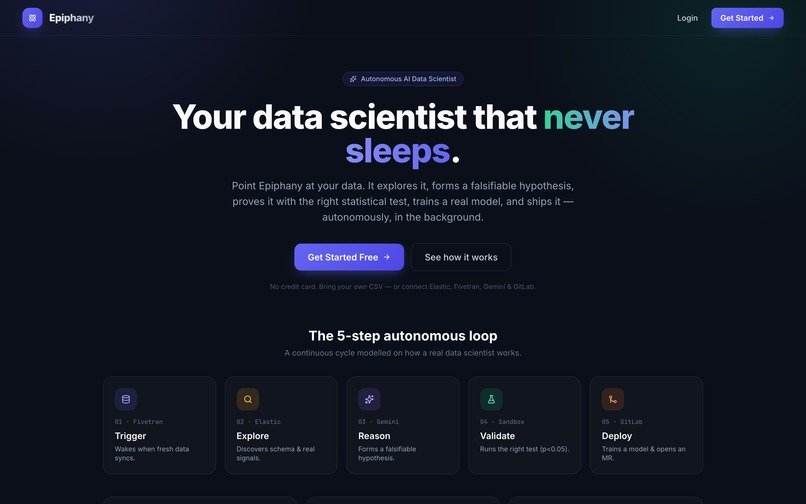
landing page
-
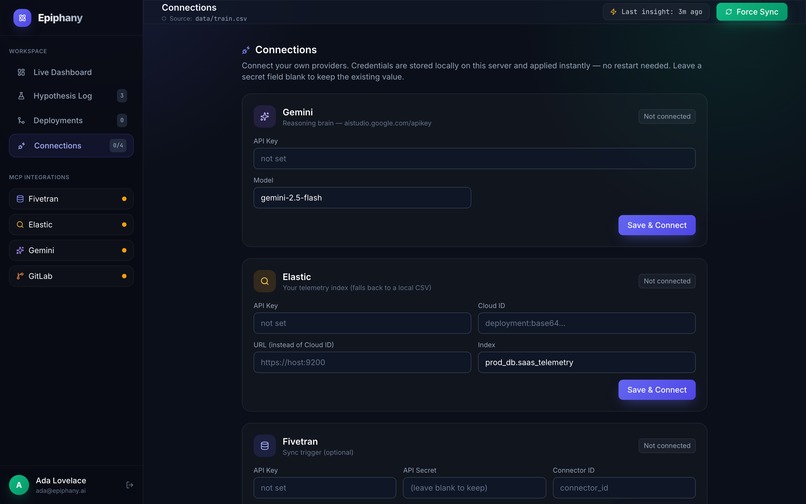
setting up your connection
-
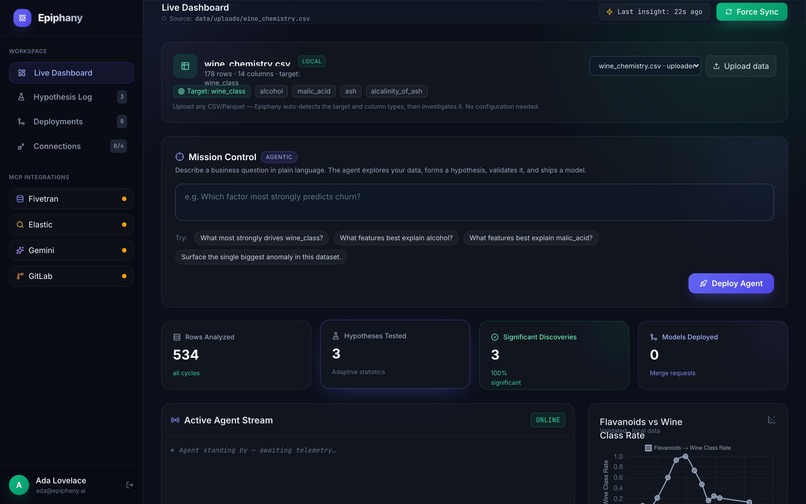
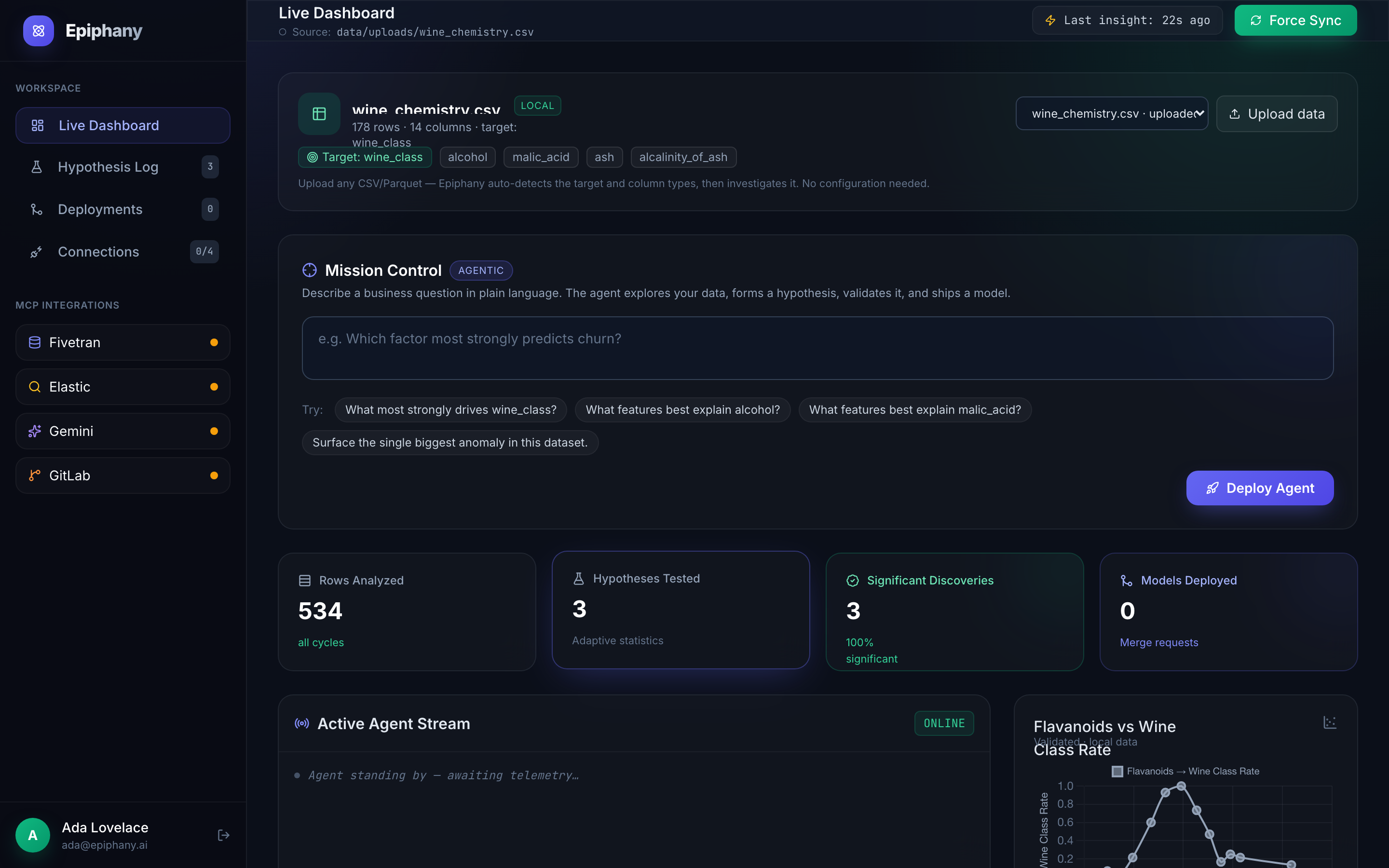
dashboard
Epiphany — Project Story
💡 Inspiration
Every company we talked to had the same quiet problem: mountains of data, and no one with the time to actually analyze it. Hiring a data scientist is slow and expensive, and the analytics backlog only grows. Meanwhile, the wave of "AI for data" tools mostly describe a spreadsheet or generate SQL you still have to run, verify, and trust.
We kept asking ourselves one question:
What if you didn't need to ask the right question — what if an agent could find the answer on its own, prove it's real, and hand you a working model?
Not a chatbot that talks about data. An agent that actually does the data science — the exploring, the hypothesizing, the statistical testing, the modeling — autonomously, in the background, while you sleep. That became Epiphany.
🔍 What it does
Epiphany is an autonomous AI data scientist. You upload any dataset (or connect a live source), and it runs a continuous loop with no human in the loop:
- Trigger (Fivetran) — wakes when new data lands
- Explore (Elastic) — discovers the schema and ranks the strongest real signals
- Reason (Gemini + Google ADK) — forms one falsifiable, business-relevant hypothesis
- Validate (SciPy sandbox) — runs the correct statistical test on real rows
- Deploy (GitLab) — trains a real ML model and opens it as a Merge Request
Crucially, every step is real. The statistics are computed on your actual data, so a weak relationship comes back not significant — the system can say "no." The model is genuinely trained and scored, then saved as a loadable artifact.
🛠️ How we built it
The brain — an agentic loop. The core is built on the Google Agent Development Kit (ADK) driving Gemini 2.5 Flash. The agent is given tools — discover schema, run aggregation, validate hypothesis, deploy model — and dynamically decides which to call to answer the mission. The whole thing is a FastAPI app that streams the agent's reasoning to a live dashboard over WebSockets, so you can literally watch it think.
Adaptive statistics — the part we're proudest of. Instead of hardcoding one test, Epiphany inspects the actual column types it discovers and picks the right method:
- categorical × categorical → Chi-Square: χ² = Σ (Oᵢ − Eᵢ)² ⁄ Eᵢ
- numeric × 2-class → Welch's t-test, with effect size Cohen's d = (x̄₁ − x̄₂) ⁄ sₚ
- numeric × 3+-class → one-way ANOVA, reporting η² = SS(between) ⁄ SS(total)
- numeric × numeric → Pearson / Spearman: r = Σ(xᵢ − x̄)(yᵢ − ȳ) ⁄ √[ Σ(xᵢ − x̄)² · Σ(yᵢ − ȳ)² ]
A finding is only "significant" when p < α (default α = 0.05), and we surface the effect size so a result can be practically significant, not just statistically so.
Real models. On a significant finding, a scikit-learn pipeline (impute →
encode → gradient boosting) is trained with a held-out split and
cross-validation, scored with real metrics (ROC-AUC / R²), and saved as a
.pkl artifact with feature importances.
Safety. Because the agent generates code, we don't trust it blindly: every
snippet is screened by an AST-based security scanner (denylisting os,
subprocess, eval, …) and executed in a network-isolated, resource-limited
subprocess, so a hostile or runaway payload yields a safe error instead of
taking down the app.
Product polish. Real auth with Clerk, a "bring-your-own-data" upload flow, in-app provider connections, per-user isolated workspaces, and a one-click deploy to the cloud (Dockerized, running live on Fly.io).
🧠 What we learned
- "Real" is a feature. The moment our test returned not significant on a genuinely weak relationship, the project clicked — most demos can only ever say "yes." Being able to say "no" is what makes it trustworthy.
- Let the data choose the method. Hardcoding a single test made it feel like a one-trick demo. Selecting the test from the data's shape is what turned it into a tool that works for anyone, on any domain.
- LLMs should reason, not compute. We learned to keep Gemini doing what it's great at — phrasing a falsifiable hypothesis — while the math stays in deterministic, verifiable SciPy. The LLM proposes; statistics disposes.
- Treat generated code as hostile by default. Agentic systems that write-and-run code need a real security boundary, not good intentions.
🧗 Challenges we faced
- Making it genuinely autonomous and general. Our first version quietly assumed one schema and one test. Rebuilding it to auto-profile arbitrary columns and pick a target via a heuristic (name hints + the "last column is the target" convention + type) was the hardest — and most important — refactor.
- A deploy-only bug that didn't exist locally. It ran perfectly on our machine but threw
TypeError: unhashable type: 'dict'in production. The hosted box pulled a newer Starlette that had dropped the legacyTemplateResponse(name, context)signature — so the context dict was being read as the template name. A reminder that "works on my machine" and "works in the cloud" are different claims. - LLM rate limits vs. a perpetual loop. A background agent calling Gemini every cycle instantly exhausted the free-tier quota of $20$ requests/day. We redesigned the loop to make zero LLM calls (data-driven hypotheses) and reserve the full multi-tool ADK agent for user-triggered missions — keeping it real where it counts without burning quota.
- Real infrastructure edge cases. Elastic's default result window caps at $10{,}000$ rows, so naïvely requesting more threw a
400and silently fell back to local data — we fixed it withsearch_afterpaging.
✦ The result
Epiphany turns a raw dataset into a statistically-validated insight and a trained model — with no human in the loop. It's live, it works on data it has never seen, and every number it reports is one it can defend.
Data science that runs itself. → epiphany-ds.fly.dev
Built With
- api
- apis
- chart.js
- clerk
- cloud
- css
- database
- devops
- docker
- elastic
- elasticsearch
- fastapi
- fivetran
- fly.io
- frontend
- gemini
- git
- gitlab
- google-genai
- html/css
- javascript
- jinja
- joblib
- ml
- numpy
- pandas
- pydantic
- python
- python-gitlab
- scikit-learn
- scipy
- sdk
- services
- sqlite
- starlette
- tailwind
- uvicorn
- vertex
- via
- websockets

Log in or sign up for Devpost to join the conversation.