-
-

Landing page
-
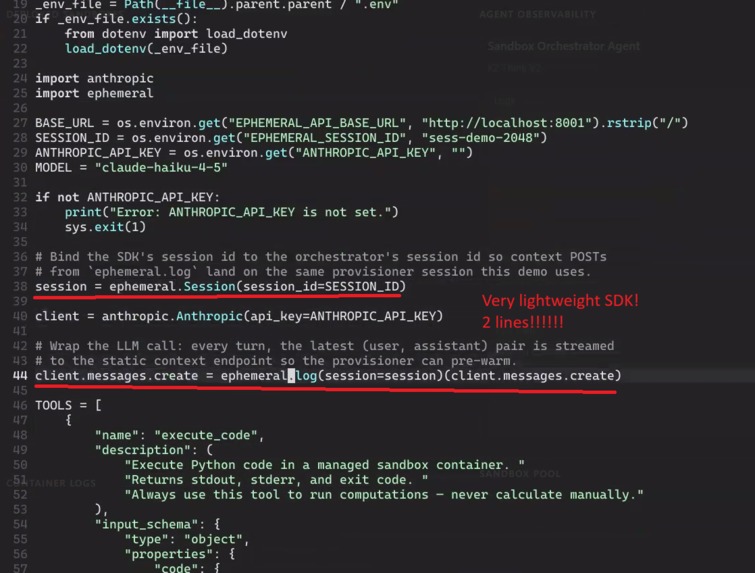
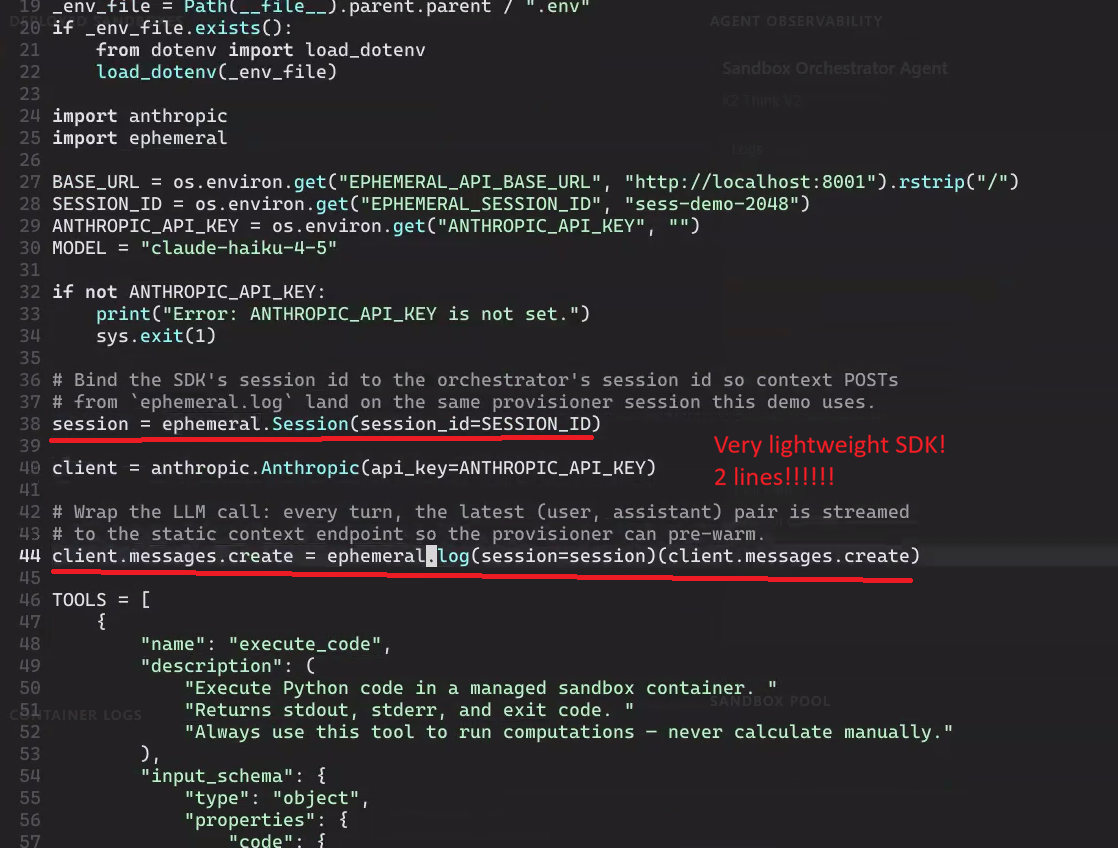
Lightweight SDK
-
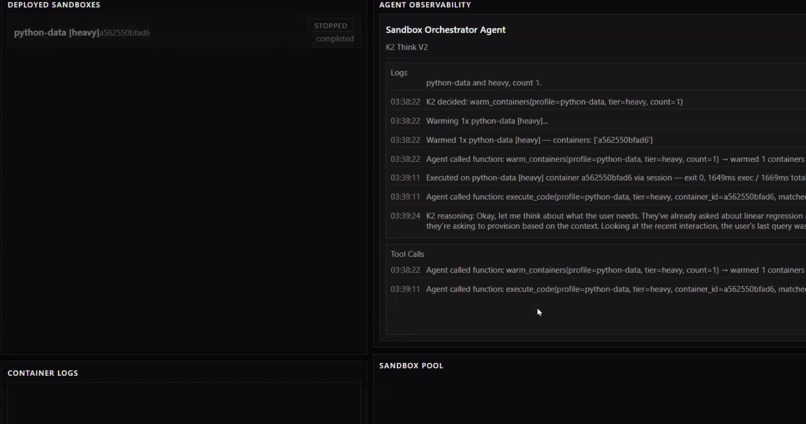
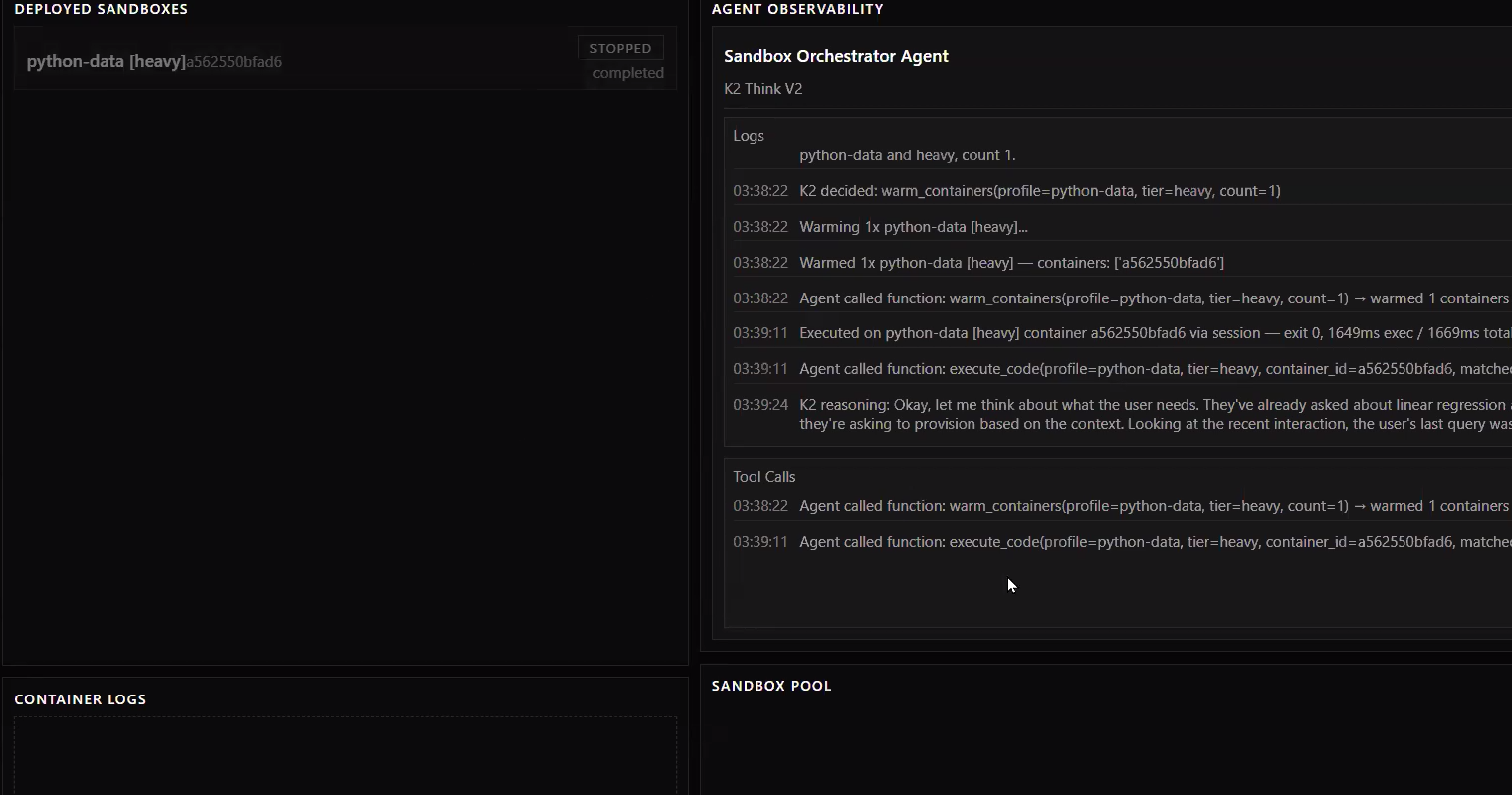
Observability dashboard for agents and sandboxes

Inspiration
Many AI products, including the big ones like Claude and ChatGPT's default web chat interfaces, on the market today provide access to sandboxes where an LLM can choose to execute custom scripts that it generates. This is incredibly useful for utility scripts and ensuring an LLM calculates certain things deterministically rather than using its own reasoning, but it creates two major engineering challenges:
- The sandbox should be isolated and ephemeral, meaning the environment should disappear directly after use for cost and security reasons
- The sandbox has to be injected with dependencies that are arbitrarily big, dependent on what kind of workload or script is called for at runtime (ex. a user asks Claude to go try out a PyTorch script, the sandbox has to have PyTorch installed, which takes a while)
What it does
- Ephemeral provides an SDK (a Python library) where a developer can wrap their LLM API calls with just a few lines of code, making it extremely simple for both consumers and businesses. Doing this automatically sends our servers the context logs of your LLM as they come.
- On our side, we process those logs using our own AI agent that has the ability to intelligently predict what kind of dependencies and of what compute size sandbox this particular session will need.
- We then provision that container before code is ever generated.
- We provide an MCP (a tool) to the developer to configure their agent with. When the agent uses the MCP to submit code it just generated, the code will be routed to an already provisioned container with the correct dependencies installed
This prediction can in some cases cut down sandbox cold start from 30 seconds all the way to sub-1 second.
How we built it
- Provisioned a Vultr dedicated CPU server that allows access to Docker daemon (containers can be summoned inside of it)
- Built K2 Think v2 powered AI agent that ingests and reasons over context logs, and makes decisions on how much compute and what dependencies to put on a container. It then makes the executive decision to provision or delete them.
- Docker SDK used to orchestrate containers with gVisor runtime (an open source software by Google that gives Docker containers more isolation from the host machine in case of dangerous code).
- Wrote a custom SDK (software development kit / python library) that allows developers to hook their existing LLM-based systems up to stream context to our server, which preps containers for the developer's LLM
- Built an MCP server that take final code execution orders from tool calling LLMs that are hooked up to the Ephemeral SDK
- React and TypeScript used to build observability dashboard
What's next for Ephemeral
- Scaling: Scaling to store many more "base images" (docker images) and running more sandboxes at once for thousands of sessions at once
- Security improvements: Transitioning from Docker + gVisor (fake kernel isolation) to MicroVMs (actual kernel isolation)
- Bet on extremely fast inference: If at some point we are able to have reliable AI inference that generates entire scripts in under 1 second, the biggest time bottleneck would probably be the sandbox problem, which we solve.
Built With
- docker
- k2thinkv2
- python
- react
- typescript
- vultr

Log in or sign up for Devpost to join the conversation.