-
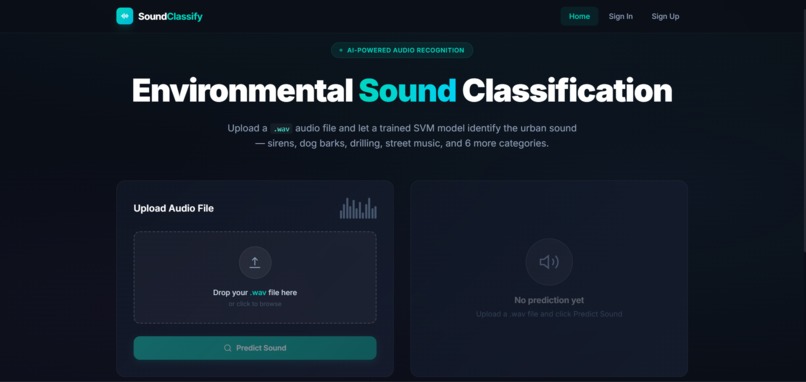
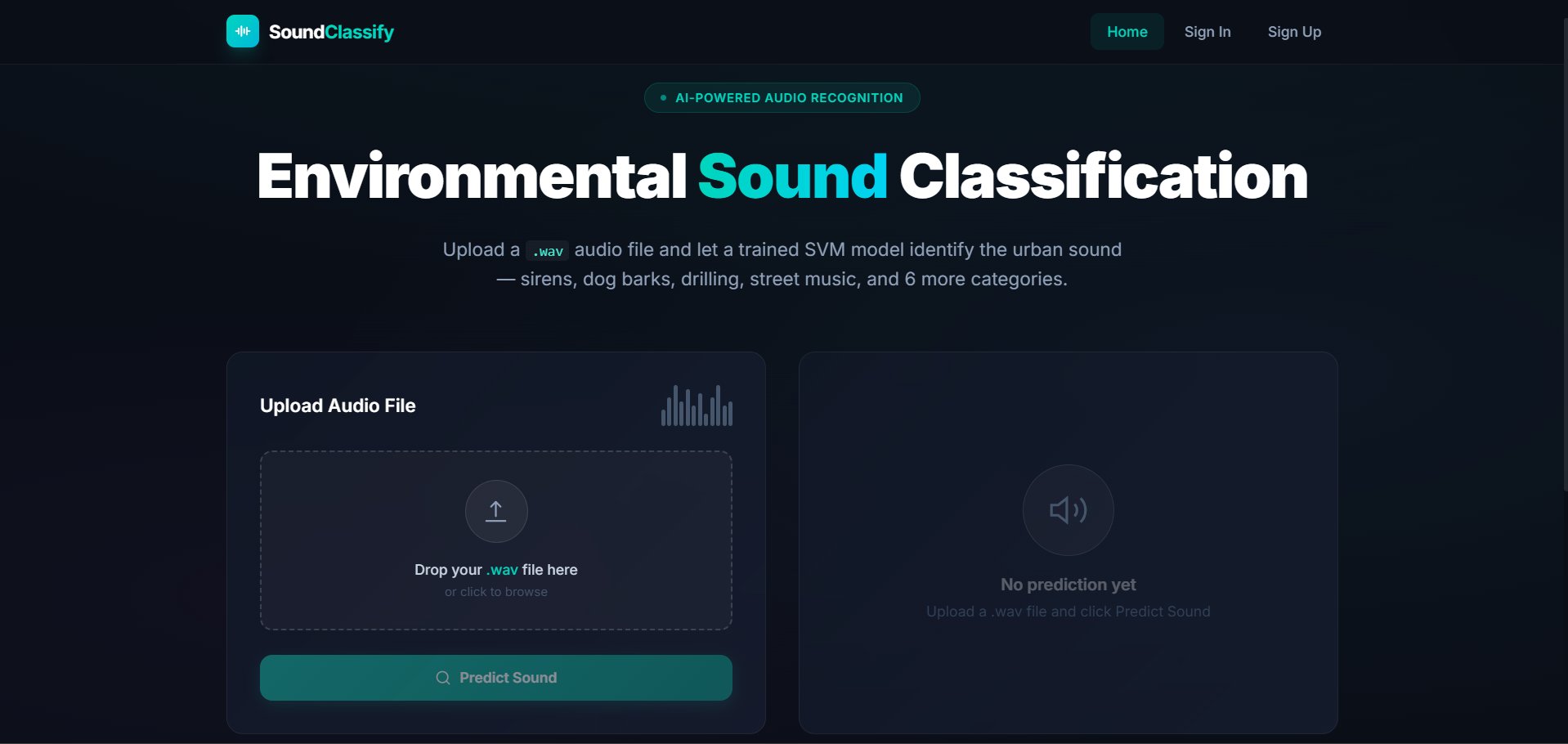
Frontend
-
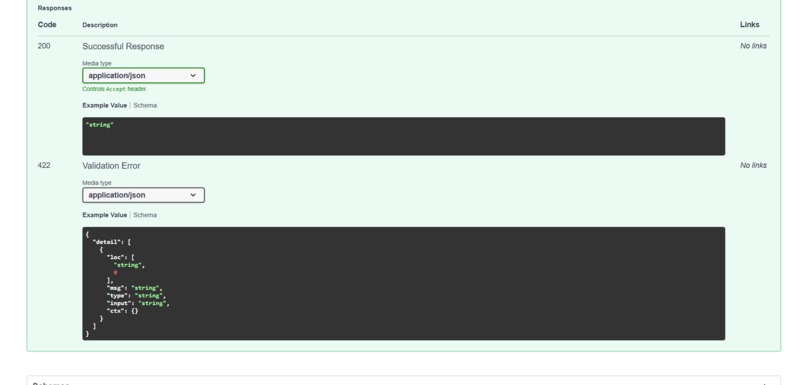
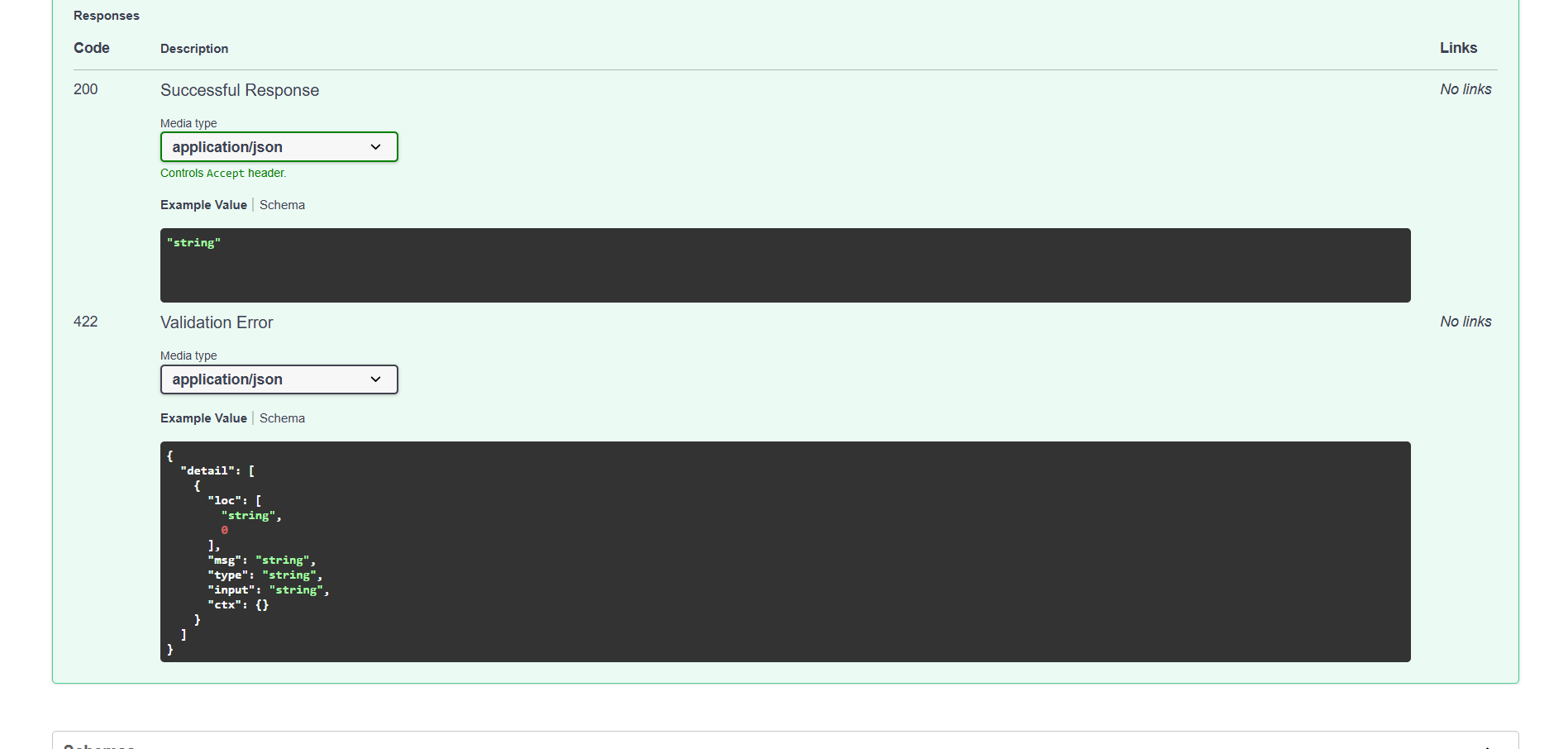
Backend API
Overview
This project focuses on classifying environmental sounds such as sirens, drilling, dog barks, engine noise, and other real-world sounds using classical Machine Learning techniques.
The system extracts Mel-Frequency Cepstral Coefficients (MFCC) features from audio signals and uses a Support Vector Machine (SVM) classifier to categorize sounds into predefined classes.
The model is evaluated using standard performance metrics including Accuracy, Precision, Recall, F1-score, and Confusion Matrix.
Key Features
Audio preprocessing and feature extraction using MFCC Multi-class sound classification Support Vector Machine (Linear & RBF kernels) Model performance evaluation REST API using FastAPI for prediction Clean and modular project structure
Datasets Used
1️⃣ UrbanSound8K 8,732 labeled urban sound clips 10 environmental sound classes Officially divided into 10 folds
2️⃣ ESC-50 2,000 environmental audio recordings 50 sound classes Organized into 5 cross-validation folds Note: Due to dataset size, audio files are not included in this repository.
Methodology
1️⃣ Audio Preprocessing Load audio files Resample to standard sampling rate (22,050 Hz) 2️⃣ Feature Extraction Extract MFCC features Compute mean values across time frames Store features as NumPy arrays 3️⃣ Model Training Train/Test split Feature scaling using StandardScaler Train SVM classifier (RBF or Linear kernel) 4️⃣ Evaluation Metrics Accuracy Precision Recall F1-Score Confusion Matrix
Installation & Setup
1️⃣ Clone Repository git clone https://github.com/VaishnaviNayak2023/Environmental-Sound-Classification-MFCC-SVM.git cd Environmental-Sound-Classification-MFCC-SVM
2️⃣ Create Virtual Environment (Recommended) python -m venv venv source venv/bin/activate # Mac/Linux venv\Scripts\activate # Windows
3️⃣ Install Dependencies pip install -r requirements.txt
How to Run
Step 1: Extract Features python extract_features.py
Step 2: Train Model python train_model.py
Step 3: Run FastAPI Server python -m uvicorn app.api:app --reload
Open in browser:
Expected Performance
Dataset Expected Accuracy UrbanSound8K 80–88% ESC-50 70–80%
Performance may vary depending on hyperparameters.
Technologies Used
- Python
- NumPy
- Pandas
- Librosa
- Scikit-learn
- FastAPI
- Uvicorn
Future Improvements
Hyperparameter tuning using GridSearchCV Deep Learning (CNN-based audio classification) Data augmentation techniques Deployment on cloud platform Frontend UI for audio upload
Author
Vaishnavi Nayak Machine Learning & AI Enthusiast
License
This project is for academic and learning purposes.
Built With
- librosa
- numpy
- python
- scikit-learn
- sklearn

Log in or sign up for Devpost to join the conversation.