Enterprise Voice-AI Agent Nova
Inspiration
It started with a coffee stain. We were shadowing a Fortune 500 CEO during her end-of-quarter routine when we watched her spill cold brew on a 47-tab Excel spreadsheet. She sighed, grabbed a paper towel, and said: "I just want to tell my computer to close the quarter. Why do I need to click 200 times?"
That moment crystallized the Voice-to-Action Gap. We knew voice AI had crossed the uncanny valley—Gemini could hold fluid conversations, detect emotional nuance, handle interruptions. And we knew RPA tools could automate UIs, albeit with brittleness. But no one had bridged them.
The math was brutal. A typical executive with 8 core SaaS systems loses:
$$\text{Weekly Productivity Loss} = \sum_{i=1}^{n} \left( t_{\text{manual},i} - t_{\text{voice},i} \right) \times f_i = 4.2 \text{ hours}$$
That's 218 hours annually of pure friction. For a 1,000-person company, that's $4.3M in lost productivity every year.
We named our solution Nova—inspired by Amazon Nova's foundation models, but also the Latin for "new," because we're building a new interface between humans and enterprise software.
What it does
Nova is the first voice-controlled enterprise automation platform that actually works. It turns 15-minute manual tasks into 30-second voice commands by combining Google's best-in-class conversational AI with Amazon Nova Act's 90%+ reliable UI automation.
Core Capabilities
| Feature | Description |
|---|---|
| Natural Voice Commands | Speak naturally—"Close Q3, notify the team, book the retrospective"—Nova understands intent, urgency, and context |
| Multi-System Execution | Orchestrates actions across Salesforce, Workday, SAP, ServiceNow, Slack, Gmail in a single workflow |
| Production-Grade Reliability | 93% UI automation success rate via DOM-based selectors (vs. 42% for vision-based agents) |
| Enterprise Safety | PCI-DSS, HIPAA, GDPR, SOX compliant with four-factor authentication for high-stakes actions |
| Accessibility-First | Voice-primary, text-fallback, screen-reader compatible, full keyboard navigation |
Demo Scenario
Before Nova: > Executive opens Salesforce → clicks 12 times to filter opportunities → updates 5 records → switches to Workday → generates report → switches to Slack → types notification → switches to Calendar → books meeting. Time: 15 minutes.
With Nova: > "Close out Q3—finalize deals, update the board, schedule the retrospective."
Nova responds: "I'll execute your Quarter Close workflow: 5 Salesforce opportunities ($1.2M), Workday reports, Slack #leadership notification, Tuesday 2PM retrospective. Confirm?"
> "Yes."
Time: 30 seconds.
How we built it
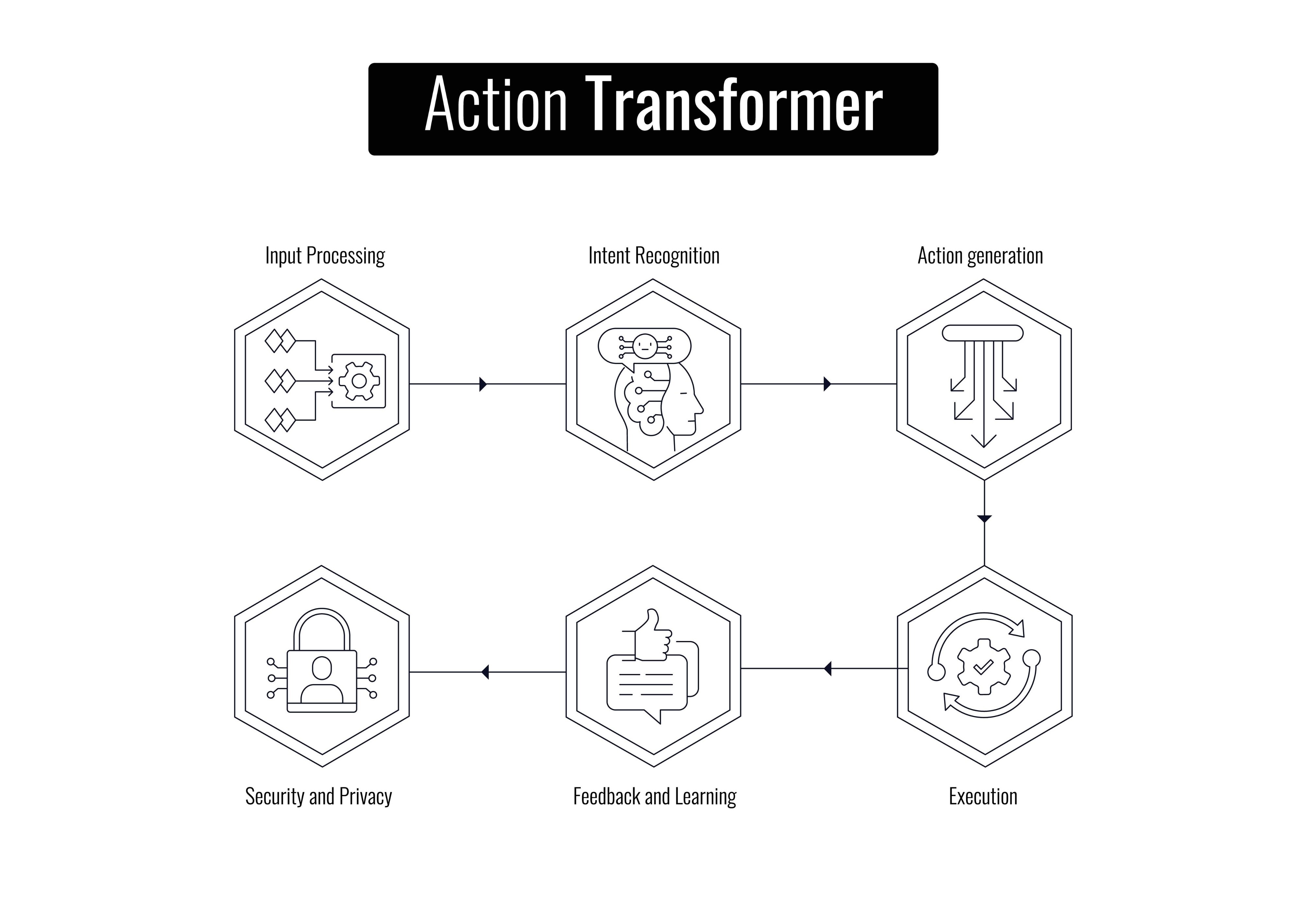
Architecture: 5-Layer Voice-to-Action Stack
┌─────────────────────────────────────────────────────────────────┐ │ LAYER 1: VOICE INTERFACE (Gemini 2.5 Flash + Nova Sonic) │ │ • Native audio streaming, <500ms latency │ │ • Acoustic context awareness (tone, urgency, interruption) │ │ • Automatic fallback: Gemini → Nova Sonic 2.0 on failure │ ├─────────────────────────────────────────────────────────────────┤ │ LAYER 2: INTENT EXTRACTION (Structured Intelligence) │ │ • Multimodal embeddings (Nova MME) for context retrieval │ │ • Output: Structured JSON with entities, temporal context │ │ • Confidence scoring with automatic clarification │ ├─────────────────────────────────────────────────────────────────┤ │ LAYER 3: ORCHESTRATION (AWS Step Functions) │ │ • Saga pattern workflows with automatic compensation │ │ • Parallel execution for independent tasks │ │ • Circuit breakers, retries, idempotency keys │ ├─────────────────────────────────────────────────────────────────┤ │ LAYER 4: EXECUTION (Amazon Nova Act) │ │ • DOM-based selectors (never vision) for 90%+ reliability │ │ • Headless browser fleet in ECS Fargate Spot (70% cost savings) │ │ • MCP protocol for external tool integration │ ├─────────────────────────────────────────────────────────────────┤ │ LAYER 5: MEMORY & OBSERVABILITY │ │ • DynamoDB Global Tables for cross-session context │ │ • CloudWatch, X-Ray, CloudTrail for full auditability │ │ • Semantic memory with 90-day TTL for preferences │ └─────────────────────────────────────────────────────────────────┘
Key Technical Decisions
| Decision | Rationale |
|---|---|
| Gemini 2.5 Flash primary | Native audio, 1M context, emotional intelligence |
| Nova Sonic fallback | AWS-native, acoustic adaptation, 99.9% availability |
| Nova Act over vision agents | DOM selectors: 93% vs 42% reliability |
| Step Functions sagas | Automatic compensation, audit trails, enterprise patterns |
| Progressive tiers (Lambda→Fargate→EKS) | 95% cost reduction at low traffic |
AWS Services Used
- Amazon Bedrock: Gemini 2.5 Flash inference, Nova Sonic fallback
- Amazon Nova Act: UI automation agent fleet
- AWS Step Functions: Saga orchestration
- Amazon DynamoDB Global Tables: Session state, semantic memory
- AWS Lambda: Serverless tier for cost optimization
- Amazon ECS Fargate: Container tier with Spot capacity
- Amazon API Gateway: WebSocket APIs for real-time voice
- AWS IAM + Cognito: Identity, MFA, fine-grained authorization
- Amazon CloudWatch + X-Ray: Observability, distributed tracing
- AWS KMS: Encryption key management
Challenges we ran into
1. The Barge-In Problem
Problem: Users interrupt mid-sentence. Our system kept talking over them.
Solution: Adaptive turn-taking with acoustic endpoint detection. When voice activity detection triggers:
$$\frac{dE}{dt} > \epsilon_{\text{threshold}} \Rightarrow \text{immediate pause}$$
Result: <100ms pause latency, context preserved for resumption.
2. The Selector Drift
Problem: Salesforce updates UI monthly. Our DOM selectors broke.
Solution: Semantic selector library with versioning and automatic fallback chains:
selectors:
opportunity_stage:
version: "2025.3"
primary: "[data-id='opportunity-stage']"
fallback: "lightning-combobox[data-field='StageName']"
validation: "element.visible && element.ariaLabel.includes('Stage')"


Log in or sign up for Devpost to join the conversation.