-
-
LLMai
Inspiration
Cloud-based AI coding tools send your proprietary source code, prompts, and terminal history to external servers you don't control — and once an agent is loose in your infrastructure, two questions go unanswered: what is it leaking, and what is it costing? For privacy-conscious developers and enterprises, that's an unacceptable risk on both ends. We built LLMai to deliver the full agentic power of modern AI assistants while guaranteeing every byte stays on your machine — and then we closed the operational loop: the agent streams its own telemetry into Splunk, and Splunk reaches back to keep it safe and on-budget, automatically. No leaks. No overspend. No cloud.
What it does
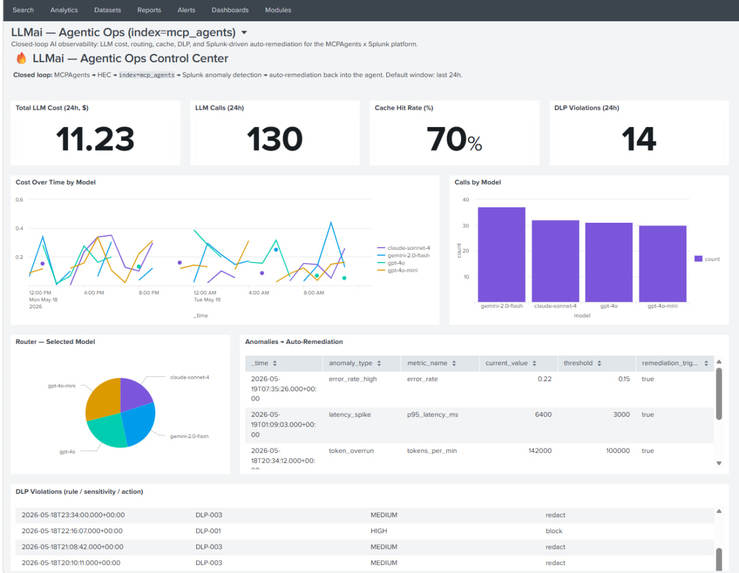
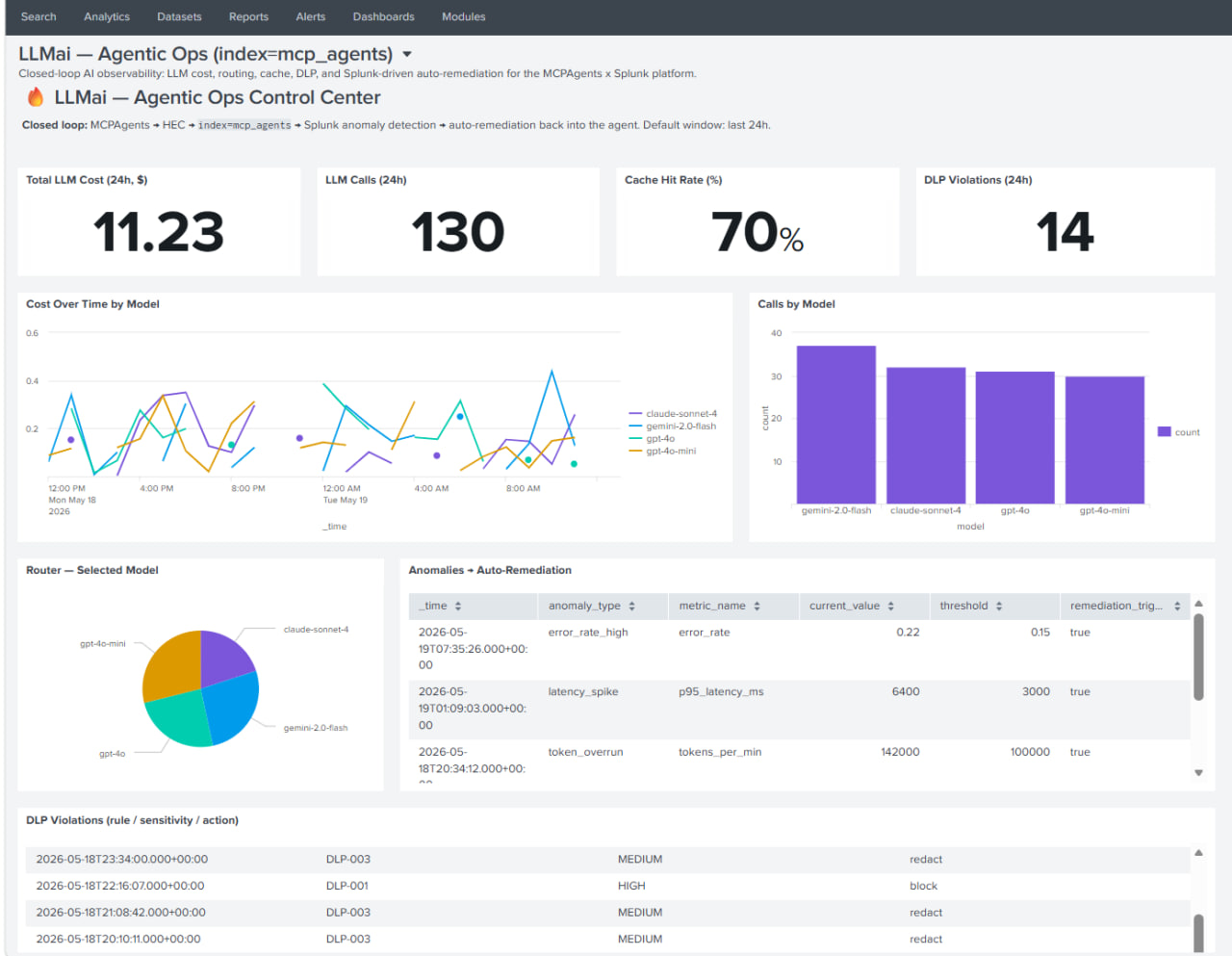
LLMai is a 100% local, open-source AI agent that doesn't just chat — it does the work, and is fully observable while doing it. Real Agentic Loop: plans the next step, calls a tool, observes the result, and iterates up to 20 times until the task is complete. Explicit-Permission Writes: read-only tools run instantly; anything that mutates state (writing files, running commands) pauses for your approval. GitLab Integration: triages issues, fetches merge requests, reads failing pipeline logs, and opens fix MRs. Closed-Loop Splunk Observability (new): every LLM call, router decision, cache hit, DLP violation, and anomaly is streamed to Splunk HEC (index=mcp_agents, 8 event types). Splunk itself is exposed to the agent as an MCP tool — natural language → SPL — alongside a Supabase data tool. Self-Healing (new): a Splunk CDTS anomaly (cost spike, latency, error rate, DLP burst, token overrun) hits a webhook and the agent re-weights its own model router at runtime, auto-restoring after a cooldown — a true bidirectional loop. Security in depth (new): DLP violations are risk-scored (Foundation-sec) and routed to 6 Splunk SOAR playbooks; every sensitive endpoint is guarded by a constant-time X-MCP-Token; credentials live in env, never in source. Control Center (new): a premium dark Streamlit dashboard (Mission Control · AI Agent Lab · Live Threat Feed · ROI Impact · SPL Query Lab) plus a 12-panel Splunk Dashboard Studio view — and a one-click public Demo Mode, still 100% on your infrastructure.
How we built it
Backend: a lightweight, highly readable Python loop — no heavy abstraction frameworks. AI Orchestration: native function-calling for Qwen 2.5 Coder and Llama 3.1/3.2, with an intelligent XML-based fallback for Gemma, Phi, and Mistral. LLM Engine: entirely local Ollama instances, with a provider-agnostic architecture (optional Gemini fallback via key). Frontend: a full-screen dark glassmorphism web UI (HTML/Vanilla JS/CSS over WebSockets) and a rich terminal REPL for CLI lovers. Splunk layer (new): an async, batched HEC telemetry emitter; a Splunk MCP tool with REST fallback; a DLP→SOAR bridge; and a CDTS anomaly → auto-remediation webhook with a runtime router re-weighter and a cooldown-restore daemon — all added with graceful degradation (env-gated, monkey-patched, try/except), so the base agent has zero regressions when Splunk is absent. Shipped under Apache-2.0 with a full PDCA engineering cycle (96–100% design-match).
Challenges we ran into
Model Compatibility: local models handle tool-calling differently; we built dynamic detection that switches between native JSON function calling and an XML fallback. Context Window Management: long agentic sessions overflow local context; we auto-summarize older turns past ~50k tokens. Security & Sandboxing: powerful enough to run shell commands without being dangerous — path-traversal blocks, a destructive-command blocklist, and visual human-in-the-loop approval. Zero-regression integration (new): bolting deep Splunk observability onto a working agent without breaking it — solved with monkey-patching + try/except + env-gating so original behavior is 100% preserved. Making Splunk act back safely (new): an autonomous control loop needs guardrails — constant-time auth on the webhook, runtime router re-weighting, and automatic restore after a cooldown so a transient spike can't permanently degrade the agent. Demo without the cloud (new): the public demo can't reach a local backend, so we built a first-class Demo Mode that runs the entire experience on simulated data.
Accomplishments that we're proud of
A fully functional local AI agent chaining 8+ tools from a single sentence (e.g., find a failing GitLab pipeline, edit the source, test, open a fix MR). A genuinely bidirectional loop: most entries ship logs one way — LLMai lets Splunk reconfigure the agent autonomously, and we can prove it (remediation_triggered = true in a 12-panel Splunk dashboard). A stunning modern dashboard to watch the agent's reasoning and approve/reject state-mutating actions. Security-first: DLP→SOAR, constant-time secret auth, credentials removed from source — all with no API keys, no telemetry, no hidden caps.
What we learned
We learned you don't need massive, opaque frameworks to build powerful AI agents — a permission-gated Python loop with the right local model (like Qwen 2.5 Coder) reaches production-level assistance with zero privacy trade-offs. We also learned that observability is most valuable as a control loop, not a dashboard: the payoff is Splunk acting back on the agent. And that graceful degradation (env-gated, monkey-patched) lets you add deep platform integration to working code with near-zero regression risk.
What's next for Enterprise AI without leaks or overspend
Persistent localStorage chat history for the web UI. Native Git integrations beyond GitLab (GitHub, Bitbucket). Cross-session memory so the agent remembers your codebase quirks across projects. Deploy the backend so the public demo runs against real Splunk; per-user RBAC + rate limiting; CI on the headless test suite; a Splunkbase-style add-on; and broader auto-remediation actions (provider failover, hard budget caps).
Built With
- css
- docker
- gitlabapi
- html
- javascript
- llama
- ollama
- python
- restapi
- splunkenterprise
- streamlit
- supabase


Log in or sign up for Devpost to join the conversation.