-
-
The home page
-
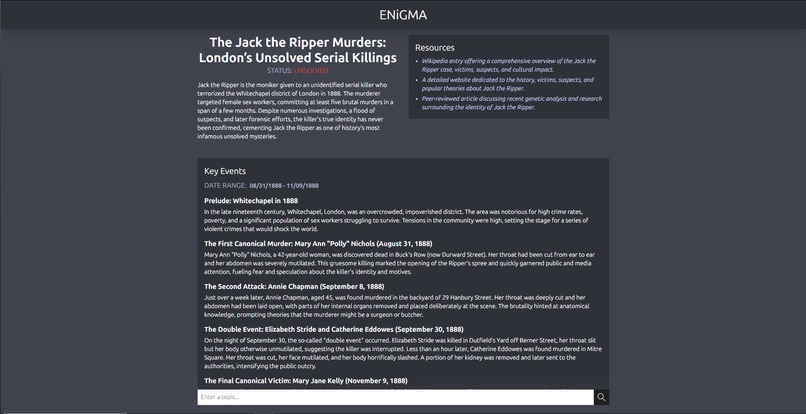
A query about the Jack The Ripper Case
-
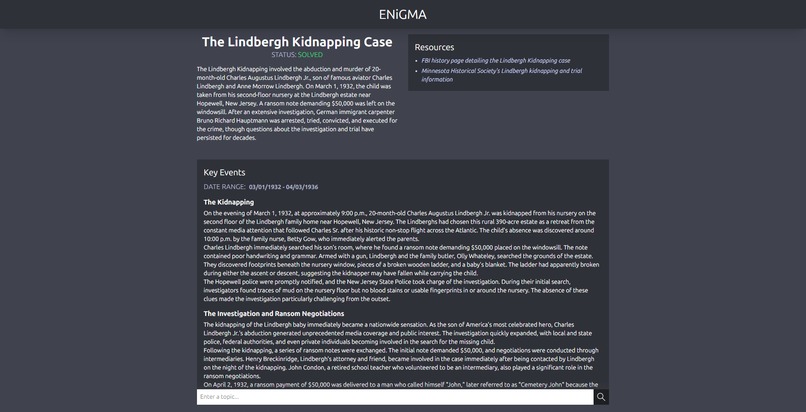
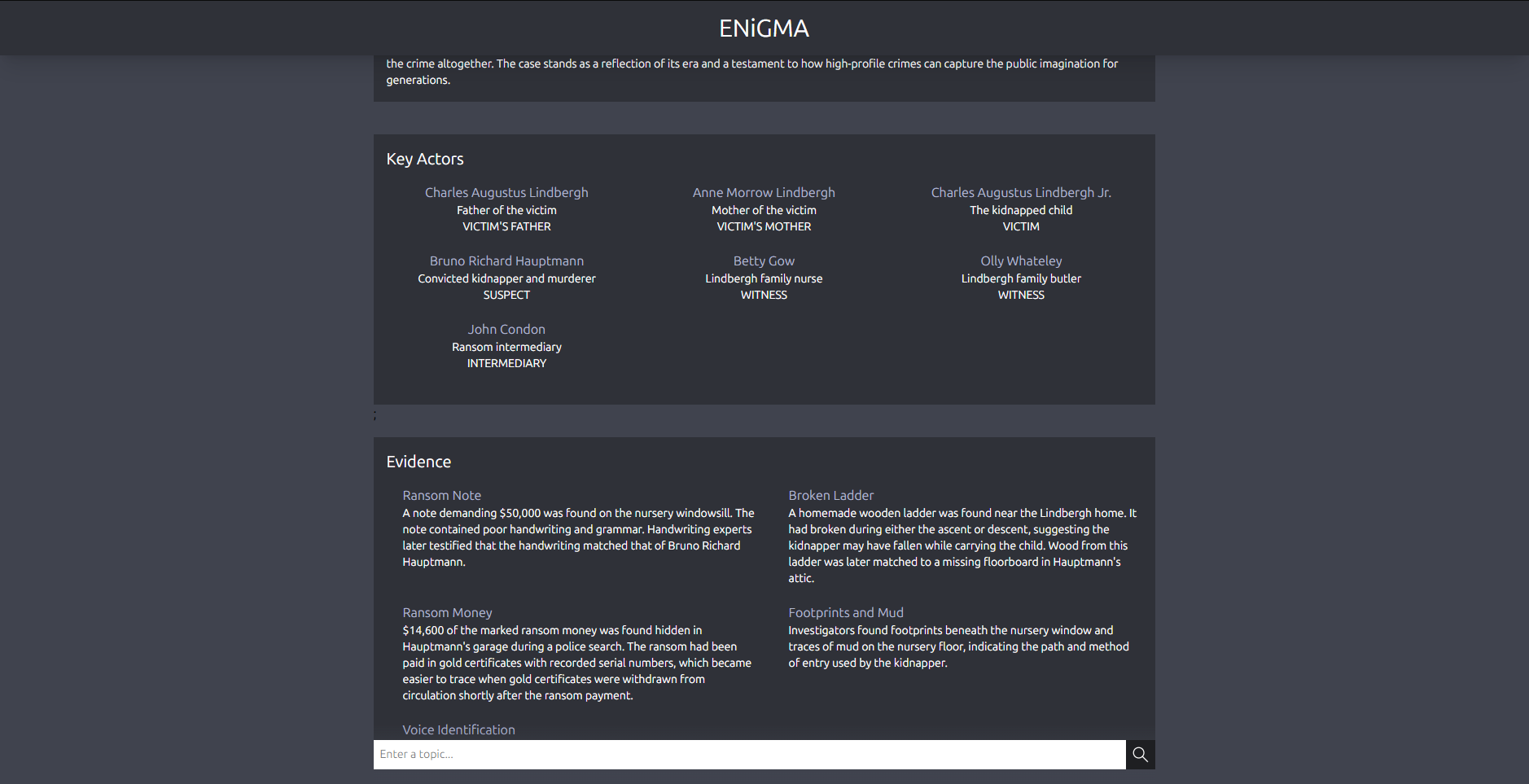
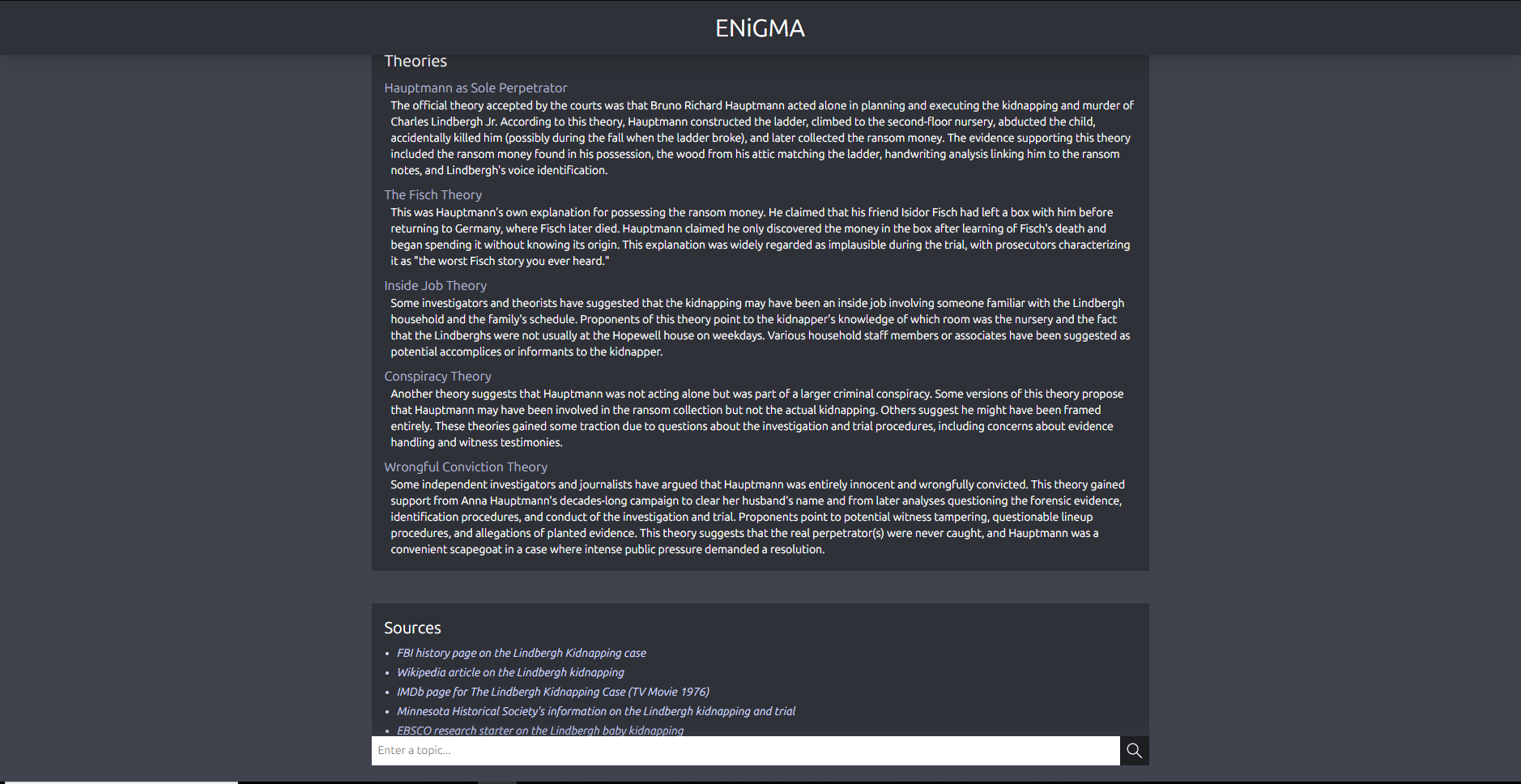
A query about the Lindbergh Kidnapping pt.1
-
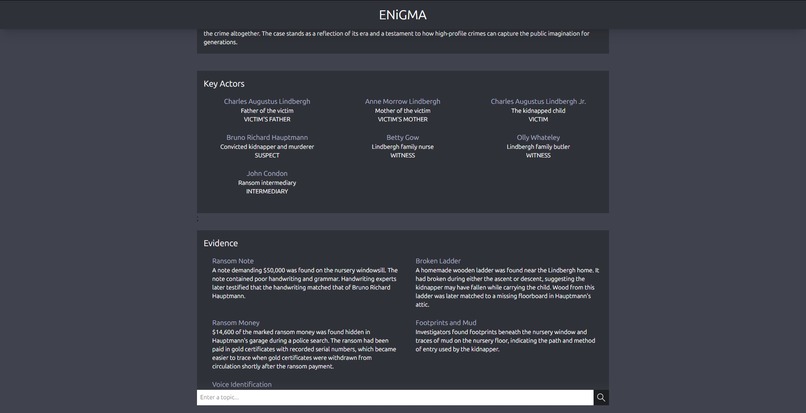
A query about the Lindbergh Kidnapping pt.2
-
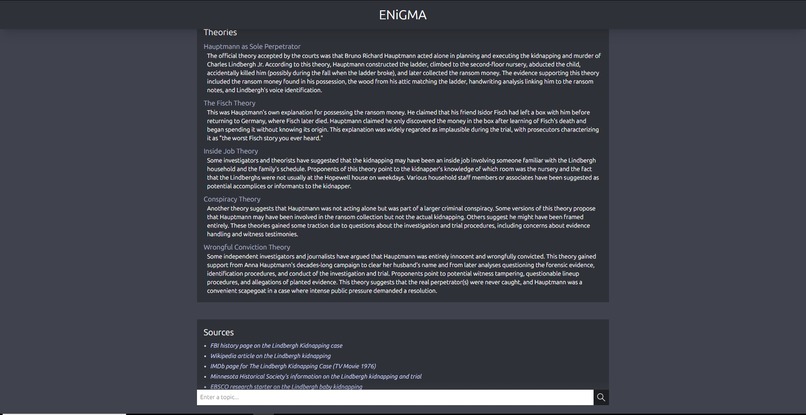
A query about the Lindbergh Kidnapping pt.3
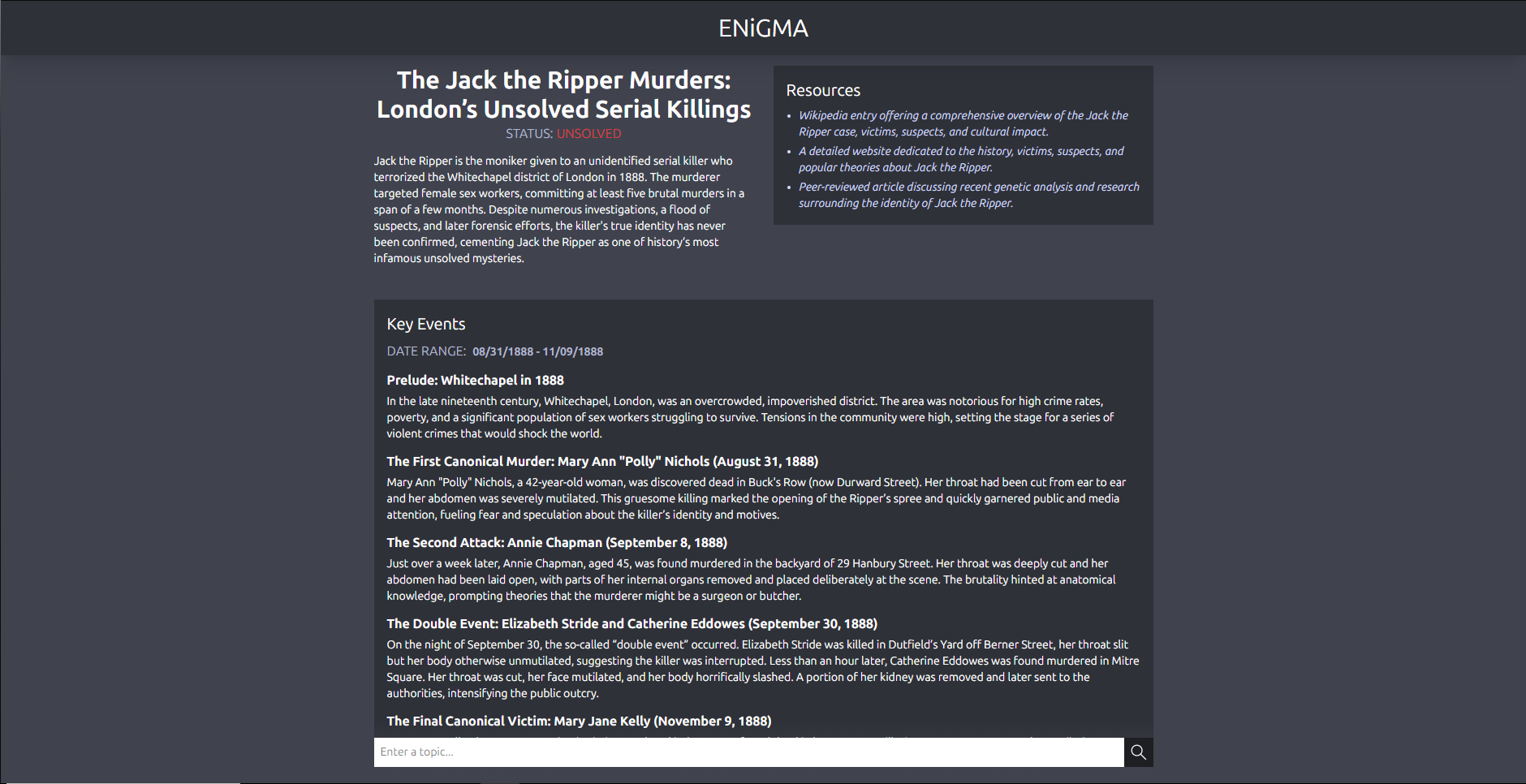
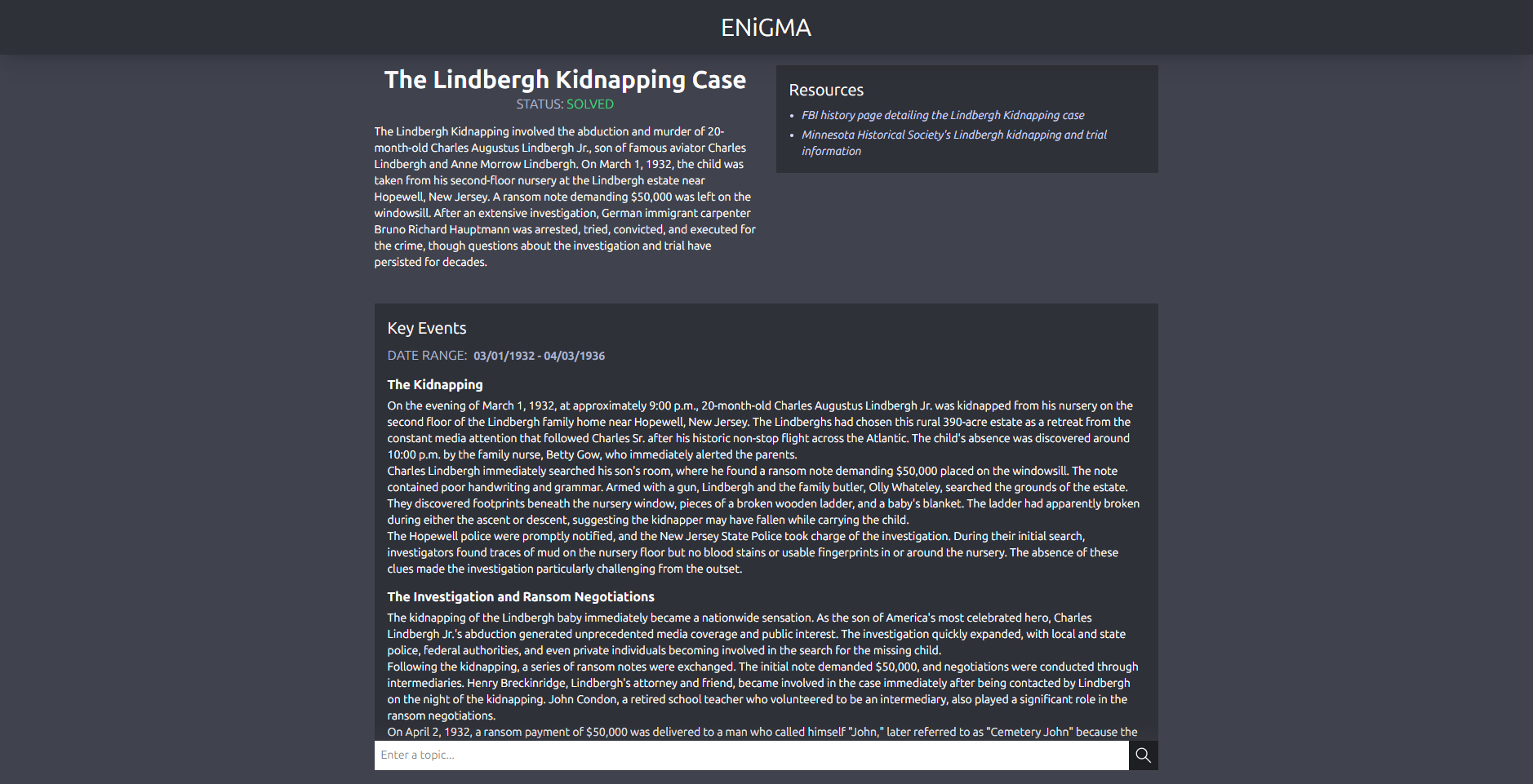
Inspiration
After I decided to participate in the hackathon, I looked into my other interests to see if I can make some sort of product that would enhance the activity using Perplexity's Sonar Models. Since I've always been interested in investigating mysteries, I thought it'd be neat to have an application that compiles data about the topic in a way where I can quickly learn the important aspects of a case, while also giving me more avenues to dig deeper into the topic (sort of like a jumping-off point).
What it does
The application takes a user input that describes some sort of mystery, uses Perplexity's Sonar Pro Model to compile vital information into a structured output, and outputs the data to the user.
The returned data includes:
- The title, status, and description of the case
- Resources to dig deeper into the topic
- Key events that occurred during the case
- Key actors that played a role in the case
- Key evidence for the case
- Theories and speculation about the case
- Sources used to compile the data
NOTE: If you're using the live link, it may take a bit longer to get a response since the live demo uses a free version of Render's deployment plan.
How I built it
To build the application, I used Express to handle the backend where it would mostly act as an intermediary between the frontend and the AI model; escaping the input, including an in-depth and highly structured prompt for the model, and returning the structured output from the model. Most of the work was figuring out what type of structure the model should return and how to ensure that it would follow that structure and return it to the frontend.
The frontend was built using React, both as a framework for displaying the output as well as for routing the pages. Its implementation was fairly straightforward since most of the elbow grease was done during the planning, design, and structuring of the data to be displayed for the user.
Challenges I ran into
My first major challenge during development was the usage of the deep-research model. I'd hoped to use this model since I wanted to have as much in-depth information as possible jam-packed into the application. However, I noticed that it kept returning its thought process instead of a formatted JSON string, thus breaking the implementation. I realized that the model had difficulty with a structured output, so I switched over to the Sonar Pro model. While this definitely solved my issues, it would've been nice to have the best of both worlds: in-depth information with a structured output. NOTE: I did try the structured output approach, per the documentation; however, that came with its own issues..
Another major challenge I came across was the inclusion of images. The initial plan was to have the AI spit out base64-encoded images for certain data points (like key actors or evidence); however, the models tended to either give malformed responses or none at all. Because of this, I had to scrap the idea of including images, but if there were some updates to the documentation or models, then I might bring it back.
Accomplishments that I'm proud of
I'm proud that I was able to properly plan out the project and closely follow the requirements that I set for myself. Especially after running into some trouble with the prompting and the outputs—for a second, I didn't think I was going to get an acceptable output. However, after some perseverance, I was able to work through the issues by testing out all of my options.
What I learned
Since this was the first time I personally worked with LLM APIs, I really learned the process of how to nudge the model toward an outcome I wanted, and I felt this was the most valuable aspect I learned throughout the hackathon. In line with this, while I didn't use it in the final product, I learned a lot about JSON schemas, and it really inspired me to use them more for future projects as a good input/output validation tool for any sort of dynamic JSON. This was also the first time I used Tailwind for a project, and it's probably safe to say that I'll be using it for most of my future projects moving forward.
What's next for ENiGMA
With this site, I plan to build upon it and add it to my portfolio as a fun product that I'll still be using for my personal use whenever I want to learn more about the information available about a mystery. I also plan to have some people in the mystery-solving community test it out so I can make additions or changes that would best support the purpose of the application.
Built With
- express.js
- node.js
- react
- sonar-pro
- tailwindcss
- typescript


Log in or sign up for Devpost to join the conversation.