-
-
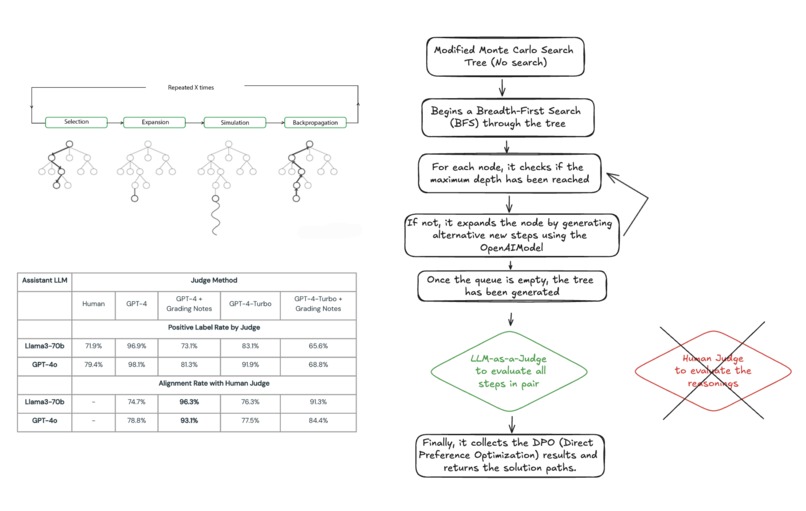
Architecture
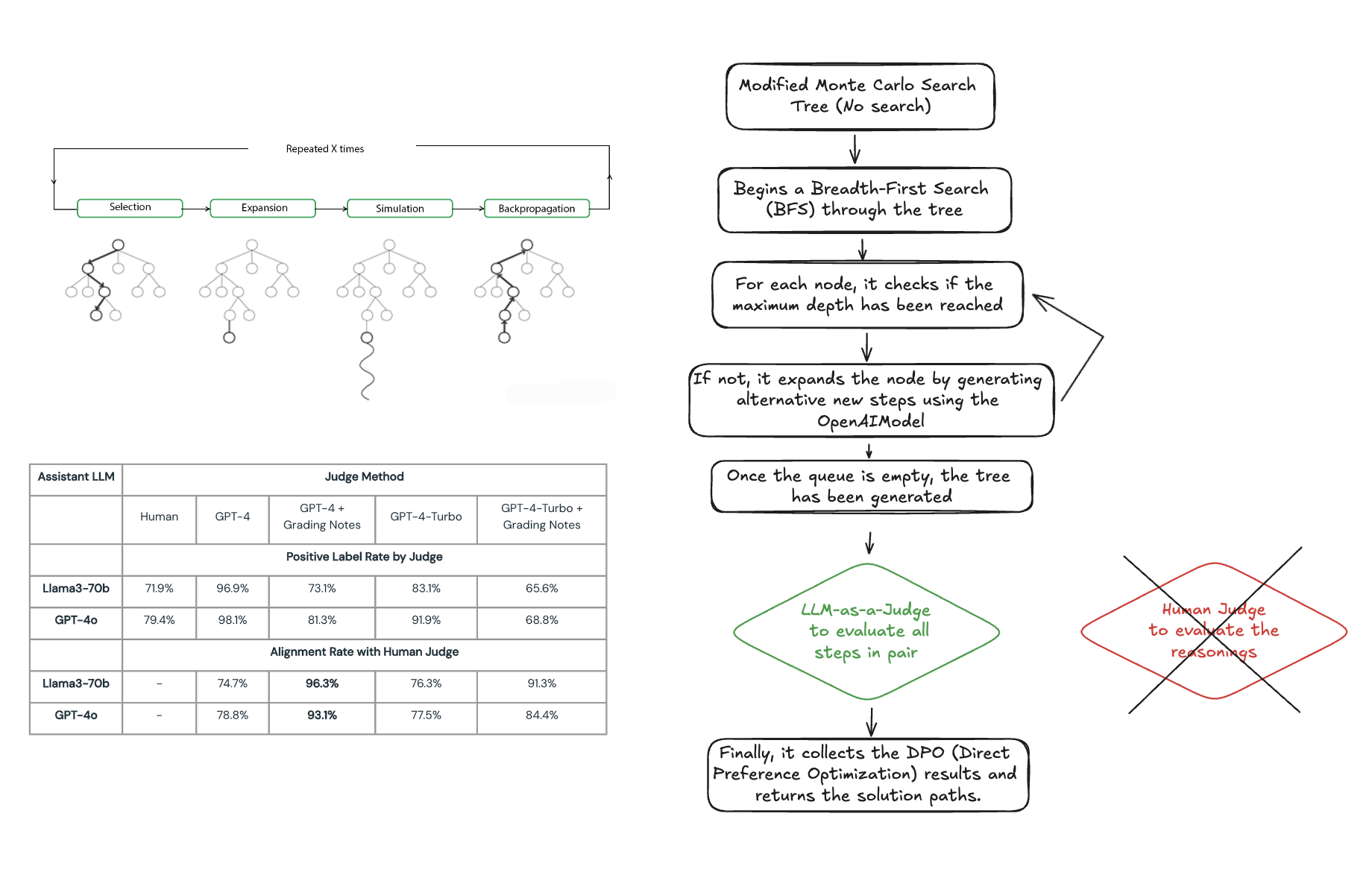
Enhancing Preference Learning for Monte Carlo Tree Search
Inspiration
The increasing complexity of AI tasks and decision-making processes, such as seen in the latest o1 model by OpenAI, demands efficient frameworks for multi-step reasoning and autonomous decision-making. Drawing inspiration from the Vstar and AgentQ papers, which highlight the benefits of using faulty rationales and multiple reasoning strategies to improve AI performance, we aimed to create a system that generates multiple trajectories for solving a task, then uses an LLM-as-a-judge to identify the most effective reasoning at each step.
What it does
Our software generates multiple task-solving trajectories, utilizing a modified Monte Carlo Tree Search (MCTS) to explore alternative reasoning paths for each step of a complex task. At each step, an LLM-as-a-judge evaluates the different reasoning strategies using Direct Preference Optimization (DPO), deciding which reasoning best contributes to solving the task. The LLM judge’s decisions, alongside its reasoning, are appended to output preferential datasets. These datasets are designed to help fine-tune smaller, less performant models, improving their ability to generate chain-of-thought reasoning and rationale.
How we built it
We developed an architecture that integrates a modified MCTS with an LLM-as-a-judge system. The modified MCTS generates multiple reasoning paths for solving each subtask. The LLM then evaluates these paths using DPO, selecting the best reasoning based on technical accuracy and effectiveness, rather than just fluency. We incorporated the LLM’s preferences and reasoning into a dataset that can be used to fine-tune smaller models.
We were inspired by the Vstar paper's approach of training models using faulty rationales to encourage robustness and the AgentQ paper's insights into improving performance in web agents by generating multiple subtasks and evaluating strategies at each step.
Challenges we ran into
We couldn't fine-tune smaller models using the preferential datasets due to time constraints and lack of computational power.
Accomplishments that we're proud of
- Successfully implemented a system that generates multiple task-solving trajectories and selects the most effective reasoning strategy using LLM-as-a-judge.
- Created a robust pipeline for generating preferential datasets that can be used to fine-tune smaller models in chain-of-thought and rationale generation.
What's next for Enhancing Preference Learning for Monte Carlo Tree Search
- Further refine the LLM-as-a-judge system by minimizing biases and expanding the range of domains in which it can operate.
- Add human-in-the-loop to the LLM-as-a-judge to improve the judge
- Explore increased number of decisions for DPO at each step.
- Extend the system's applicability to domains beyond math and logic reasoning
- Try to actually use the generated preferential datasets to fine-tune smaller models, making them better at multi-step reasoning and rationale generation.

Log in or sign up for Devpost to join the conversation.