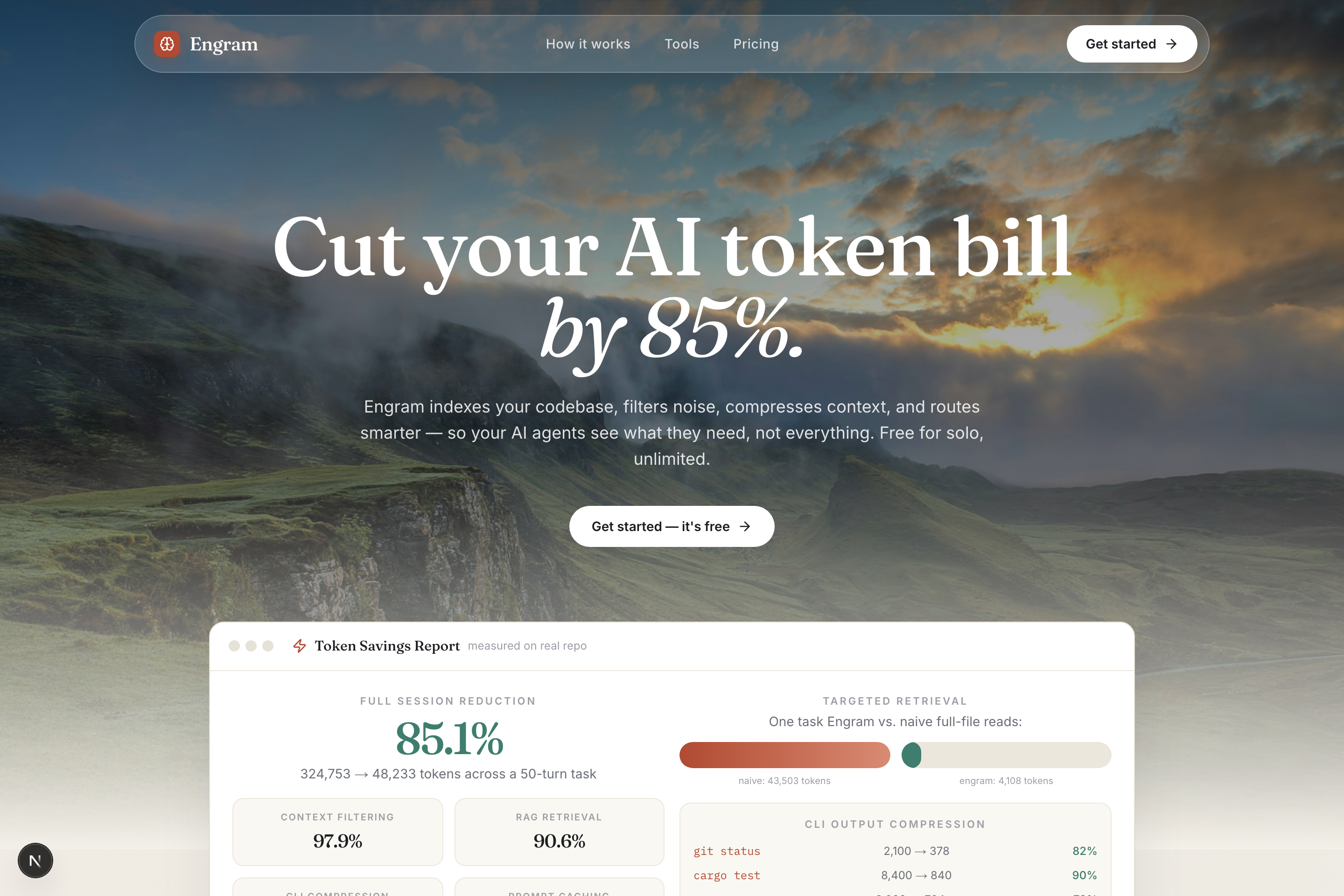
Inspiration I was burning through my session usage limit on AI coding agent tokens, and watching 80%+ of them go to waste for nothing. Every session, Claude Code re-reads the entire repo, re-learns the architecture, forgets what it solved yesterday, and dumps massive file contents into the context window. It's like hiring a developer who burns their notes after every standup. I later discovered this wasn't unique to us. The entire AI coding ecosystem has the same problem, being context window waste. Agents pay to re-process the same boilerplate, the same node_modules, the same test output, every single turn. on the Engram source repo, a naive 50-turn agentic coding task consumed 324,753 tokens. With Engram's optimization stack, the same task used 48,233, an 85.1% reduction. The aha moment came when we realized this isn't one problem. It's four stacked problems: what enters context, what's already in context, what the model outputs, and how requests route. Each layer adds on to the other. Fixing one gives you 20%, but stacking all four gives you 85%. What it does Engram is a full-stack LLM token reducer. It sits between your AI agents and your codebase as a local knowledge graph + persistent memory layer exposed via 25 MCP (Model Context Protocol) tools. Layer 1: Control what enters context:
- .claudeignore and context filters strip node_modules, build artifacts, logs, achieving up to 97.9% noise removal
- RAG / codebase indexing: agents query a semantic index instead of reading raw files, using 90.6% fewer tokens vs. naive file reads
- Prompt caching: system prompts, tool defs, and CLAUDE.md cache across turns for ~81% input cost reduction
- CLI output compression (RTK): git status, cargo test, and grep output compressed 60–91% before entering context Layer 2: Compress what's already in context:
- /compact and context summaries: prune accumulated history at ~95% context fill
- Tool output aggregation: expose get_summary_by_region instead of get_all_records
- Compact data formats: MessagePack, TOON, or CSV instead of verbose JSON Layer 3: Tighten model outputs:
- Caveman-style verbosity control: strip filler, pleasantries, and over-explanation for 50–75% output reduction
- Structured output formats with strict schemas Layer 4: Route smarter:
- Model routing (RouteLLM): simple tasks to cheap models, complex to frontier for 40–85% cost reduction
- Scoped sessions with /clear between unrelated tasks The dashboard provides real-time visibility: token savings per session, hot files, sync status, and a time-travel replay to inspect exactly what context the AI used. How we built it Architecture:
- Core engine (@kabirlikestocode/engram-core): TypeScript package with a SQLite-backed code knowledge graph (via better-sqlite3 v12), tree-sitter AST parser supporting TypeScript, Python, Go, Rust, and Java, a semantic search index, file watcher for live updates, and episode memory for cross-session persistence.
- MCP Server (@kabirlikestocode/engram-mcp-server): 25 tools exposed via the Model Context Protocol, including get_context_for_task, get_impact_of_change, get_pr_context, remember/recall_episodes, deep_research, transform_prompt, and explain_architecture. Runs on stdio, compatible with Claude Code, Cursor, Windsurf, Cline, and any MCP-compatible agent.
- CLI (engram): engram init, engram serve, engram index, engram status, engram team create/invite, engram sync push/pull. One command to set up and start.
- Dashboard (Next.js 16 + Supabase): Real-time token savings, graph health metrics, team management, billing (Stripe), token management, and time-travel query replay. Light editorial design with Fraunces serif + Inter + IBM Plex Mono. Benchmark: We ran a real benchmark over the Engram codebase itself (12.4M tokens across 1,099 files):
- Without filtering: 324,753 tokens/session, With Engram: 48,233 tokens, an 85.1% reduction (6.7×)
- RAG retrieval vs. naive reads: 43,503 to 4,108 tokens, a 90.6% reduction (10.6×)
- CLI compression: git status 82%, cargo test 90%, grep 78% Challenges we ran into
- Node 26 + better-sqlite3 incompatibility: better-sqlite3@11.x uses deprecated V8 APIs (GetPrototype, This on PropertyCallbackInfo) removed in Node 26. We upgraded to v12 (prebuilt binaries) and discovered macOS Command Line Tools receipts were missing, so node-gyp couldn't detect the compiler toolchain. We patched node-gyp's xcode_emulation.py to fall back to xcode-select -p when pkgutil receipts are absent.
- Stripe API version drift: The Stripe SDK updated from 2026-04-22.dahlia to 2026-05-27.dahlia mid-hack. TypeScript's strict string literal types caught this, as the old version was no longer assignable to the new type. Simple fix but hard to diagnose in CI.
- Next.js 16 + Turbopack NFT tracing: Our replay route uses a dynamic require('@kabirlikestocode/engram-core') for runtime loading. Turbopack's file tracing flagged the entire project. We left it as a warning since it's a runtime-only path with a graceful fallback.
- Supabase project pausing: Free-tier Supabase projects pause after inactivity. Our middleware crashed with "Failed to fetch" because supabase.auth.getUser() threw network errors instead of returning null. We wrapped all auth calls in try-catch for graceful degradation.
- Design system migration: We rebuilt the entire dashboard from a dark neon-cyan theme to a warm editorial design (Fraunces serif + terracotta accent + warm paper background). This meant replacing every hardcoded dark color across 15+ pages while maintaining consistency. Accomplishments that we're proud of
- 85.1% token reduction measured on a real 50-turn agentic coding task, not a synthetic benchmark, our actual repo
- 25 MCP tools covering context retrieval, impact analysis, PR awareness, persistent memory, prompt transformation, and deep research
- Real-time dashboard with token savings tracking, live sync status, and time-travel query replay
- End-to-end working system: sign up, create API tokens, sync a project, wire into Claude Code, watch tokens drop in the dashboard
- Full design overhaul: warm editorial system (Fraunces serif, terracotta accent, paper backgrounds) that feels premium and intentional
- 2-tier pricing that's honest: Solo free forever (unlimited), Team $30/dev/mo, with no Pro tier gatekeeping basic features What we learned
- Token waste is a 4-layer problem. Filtering (Layer 1) is the biggest single win at ~98%, but compression (Layer 2), output tightness (Layer 3), and routing (Layer 4) stack multiplicatively. You can't just do one.
- The best context is no context. Our RAG benchmark showed that targeted graph queries retrieved the same information in 4,108 tokens that naive file reads consumed 43,503 tokens to deliver. The agent performs identically; it just doesn't need to see the rest.
- CLI output is a silent token killer. A single cargo test run can be 8,400 tokens. Compressed, it's 840. Over a 50-turn session, these compound to enormous waste, and almost every coding agent produces them on every turn.
- Pricing should reflect cost structure, not feature gating. We removed the Pro tier entirely. Solo is free forever with unlimited projects, symbols, and all 25 tools. The only thing you pay for is team sharing (which actually costs us money in cloud sync). This is honest pricing. What's next for Engram
- LLMLingua integration: Prompt compression using small language models, achieving up to 20× compression with <2% quality loss. Already listed in our tools section; next step is baking it in natively.
- CodeContext-Mode sandboxing: Isolate large tool outputs and hand back only structured summaries to the agent, achieving up to 98% token savings on tool calls.
- RouteLLM integration: Automatic model routing, sending simple tasks to cheap models and complex reasoning to frontier. The API surface is already designed; we need to wire it through the dashboard.
- Tokless unified installer: One command to install the full stack (RTK + Caveman + CodeGraph + Context-Mode) for any MCP-compatible agent.
- Team graph sync improvements: Multi-repo knowledge graph with conflict resolution and branch-aware context.
Built With
- css
- mcp
- nextjs
- node.js
- pnpm
- postgresql
- react
- realtimedb
- rust
- sdk
- sql
- sqlite
- supabase
- tailwind
- typescript



Log in or sign up for Devpost to join the conversation.