-
-
Platform
-
Architecture
-

Architecture in Depth

Inspiration
India loses ₹1.5 lakh crore every year to electricity theft and aging grid inefficiencies. That's not a rounding error — that's the annual budget of several Indian states combined. DISCOMs bleed through line snatching, meter tampering, and billing fraud while field teams rely on manual audits and gut instinct. Meanwhile, smart meter rollouts are generating more data than anyone knows what to do with, and IEX price signals go unused by the utilities that need them most.
We wanted to build what a power utility's war room should look like in 2025: real-time, intelligent, and actionable. The scale of AT&C losses (some states above 40%) and the untapped potential of smart meter data inspired us to use Databricks as a unified lakehouse to finally connect all these dots.
What it does
Enerlytics GridSense AI is an end-to-end grid intelligence platform for Indian DISCOMs:
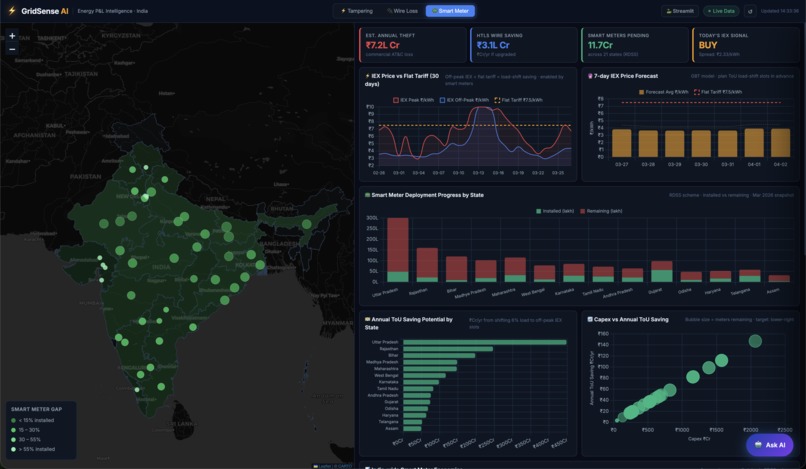
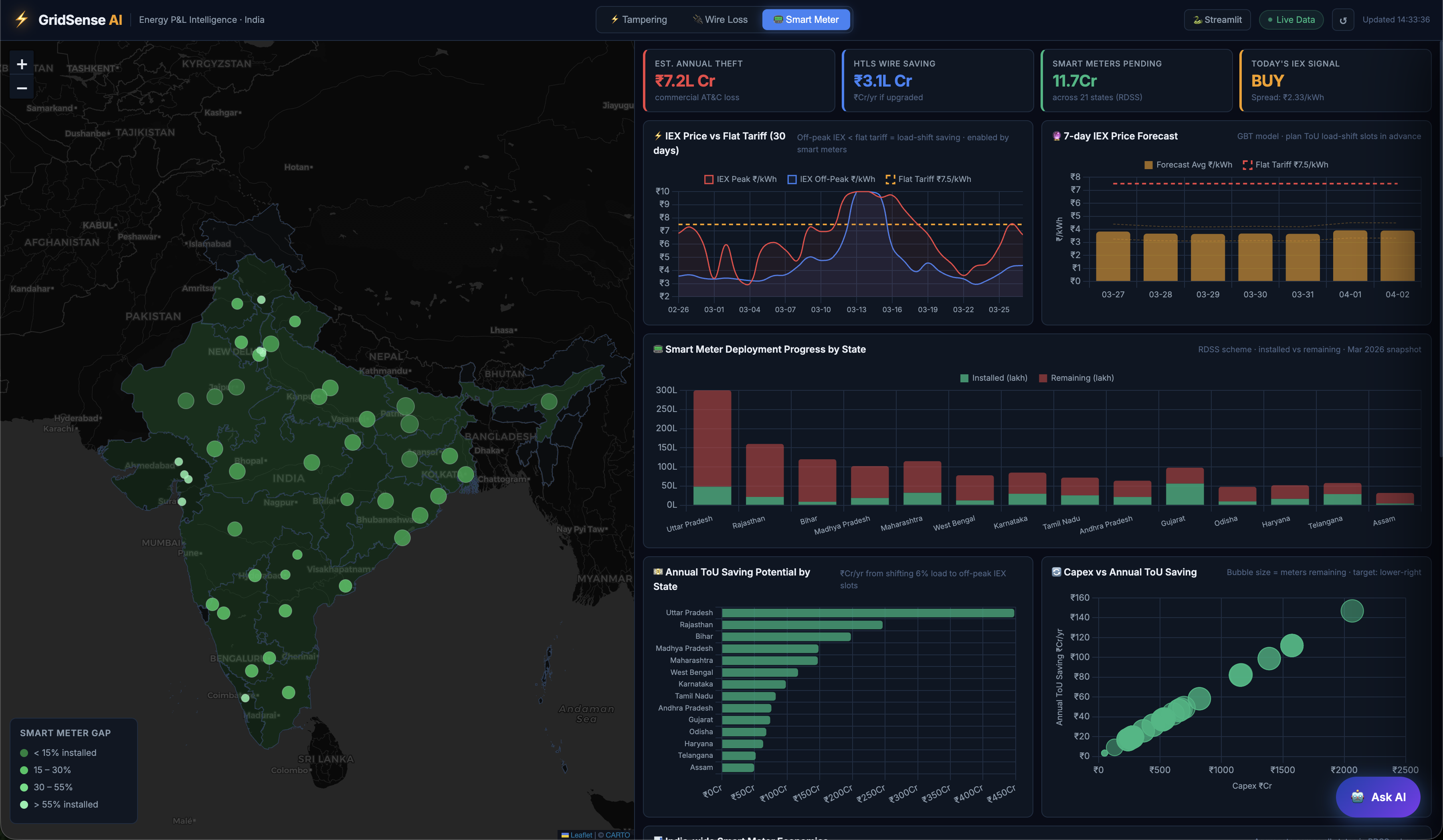
- Theft & Tampering Detection — Isolation Forest ML flags anomalous consumption patterns, quantifying revenue leakage (₹ Cr) per state with tampering severity scores
- AT&C Loss Analytics — Tracks billing gap, collection gap, and technical losses with 2021→2024 trend comparison across utilities
- IEX Price Forecasting — GBT model delivers 7-day DAM price forecasts, enabling off-peak procurement strategies
- BESS Arbitrage Optimizer — Dynamic programming engine computes optimal battery charge/discharge schedules against live IEX prices
- Smart Meter Intelligence — Time-of-use pricing analysis showing consumer savings potential vs. flat tariff
- Bilingual Insights — Sarvam AI generates Hindi-language summaries for field officers and regional teams
- Live Grid Map — DISCOM-level choropleth with drill-down anomaly, HTLS, and smart meter deployment overlays
How we built it
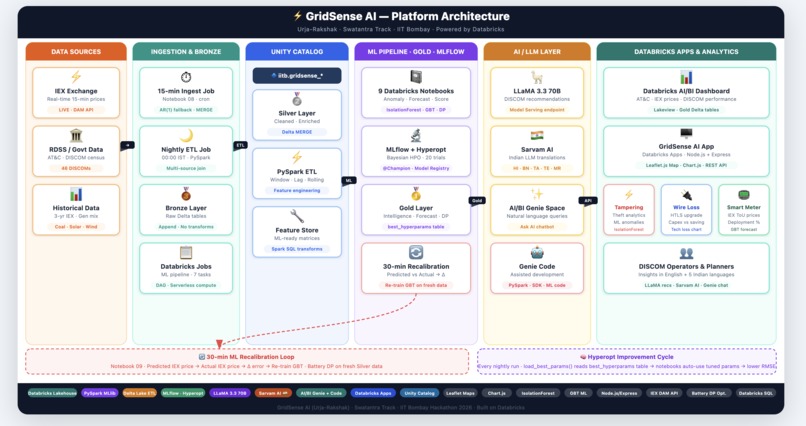
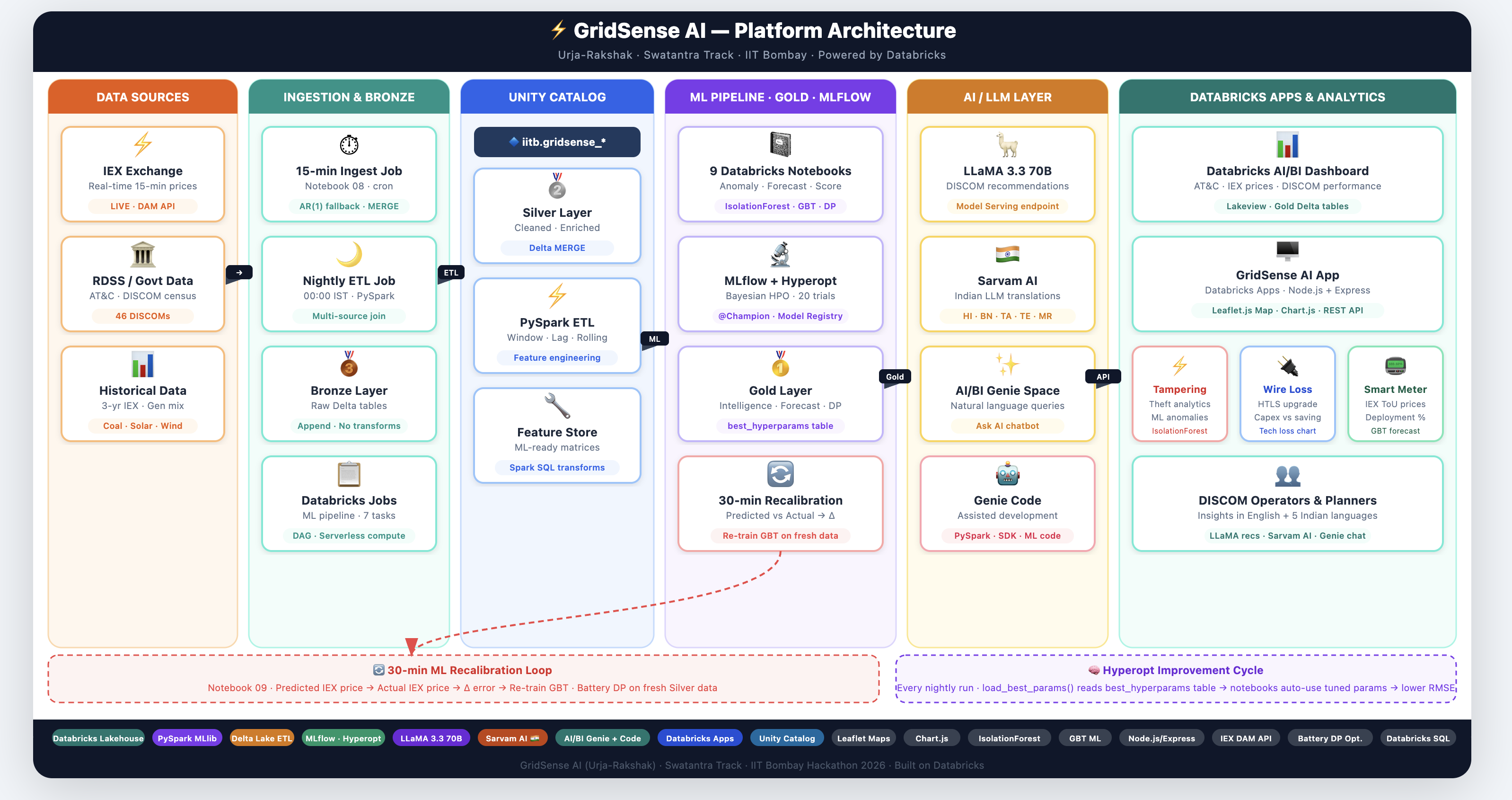
Built entirely on the Databricks Lakehouse Platform:
Ingestion: Databricks DLT streaming pipeline (IEX DAM data), batch ETL from Govt/POSOCO sources Storage: Delta Lake (Bronze → Silver → Gold), Unity Catalog for governance ML: Notebooks + Jobs: IsolationForest (anomaly), GBT (price forecast), Hyperopt Bayesian tuning Model Ops: MLflow Model Registry, champion/challenger promotion, 30-min recalibration job AI: LLaMA 3 (ML interpretation), Sarvam AI (Hindi translation) Analytics: Databricks SQL Warehouse, AI/BI Dashboard, Genie (natural language queries) App: Databricks Apps hosting a Node.js server with Chart.js + Leaflet frontend
Challenges we ran into
- Data fragmentation — CEA, POSOCO, and state DISCOM data comes in inconsistent formats across different reporting periods; building a unified Silver schema required careful DLT pipeline design
- IEX streaming reliability — Handling late-arriving and missing price blocks in the real-time ingest pipeline without poisoning the forecast features
- ML on imbalanced anomaly data — Tuning IsolationForest contamination thresholds so flagged anomalies were meaningful, not noise; resolved via Hyperopt Bayesian search logged to MLflow
- Workspace path routing — Databricks Apps proxying SQL Warehouse calls through a Node.js backend required careful CORS and token management
- Multilingual output — Getting Sarvam AI to produce coherent Hindi summaries from structured numeric data took several prompt engineering iterations
Accomplishments that we're proud of
- Full lakehouse → app pipeline in one workspace — DLT ingest, ML training, model registry, and live web app all running on Databricks with zero external infra
- Hyperopt tuning pipeline — Automated Bayesian search logs 20 child runs per model to MLflow, promotes the champion, and future job runs automatically pick up better hyperparameters
- Quantified revenue impact — The platform surfaces ₹ crore estimates of theft losses per state, giving utility executives an actual business case for intervention
- Bilingual accessibility — Hindi insights via Sarvam AI make the platform usable for field engineers, not just data teams
- Real IEX data — Live price ingestion and 7-day forecasts are grounded in actual Indian electricity market data, not synthetic placeholders
What we learned
- Databricks Unity Catalog + DLT together dramatically reduce the "data plumbing" burden — schema enforcement and lineage come for free
- MLflow's nested run structure (parent tuning run → child trials) is genuinely powerful for Hyperopt workflows — reproducibility without extra tooling
- For Indian energy data, domain knowledge matters more than model sophistication — knowing that AT&C loss = billing gap + collection gap shaped the entire feature engineering
- Sarvam AI performs significantly better than generic LLMs on India-specific utility terminology and regional context
- Databricks Apps makes it possible to demo a production-quality web app without managing any servers — huge for a hackathon timeline
What's next for Enerlytics_GridSense AI
- Predictive maintenance — Extend anomaly detection to transformer health and feeder fault prediction using IoT sensor feeds
- Demand response module — Alert industrial consumers to high-price periods and automate load-shedding recommendations
- State regulator dashboard — Aggregated view for CERC/SERCs to benchmark DISCOMs against national AT&C targets
- Smart meter OTA integration — Direct API hooks into advanced metering infrastructure (AMI) for sub-15-minute consumption data
- Carbon accounting layer — Map grid losses to CO₂ equivalents to support India's NDC reporting obligations
Built With
- apache-spark
- chart.js
- databricks
- databricks-ai/bi-dashboard
- databricks-apps
- databricks-dlt
- databricks-genie
- databricks-jobs
- databricks-sql-warehouse
- delta-lake
- hyperopt
- iex-india-api
- javascript
- leaflet.js
- llama-3
- mlflow
- node.js
- pyspark
- python
- sarvam-ai
- scikit-learn
- unity-catalog



Log in or sign up for Devpost to join the conversation.