-
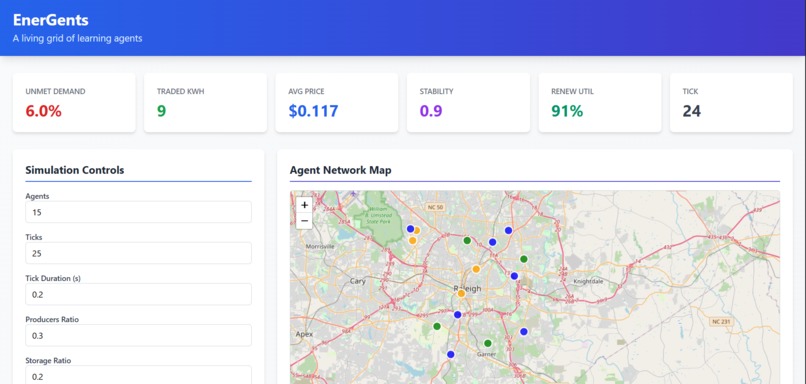
Dashboard
-
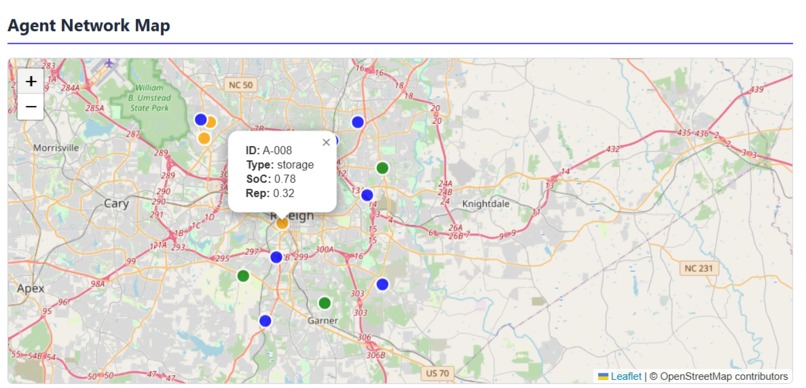
Agent Network Map
-
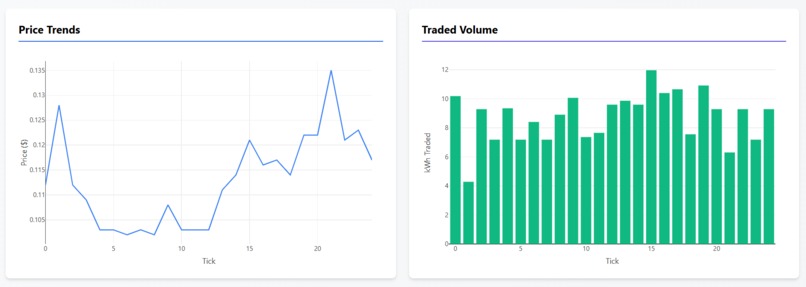
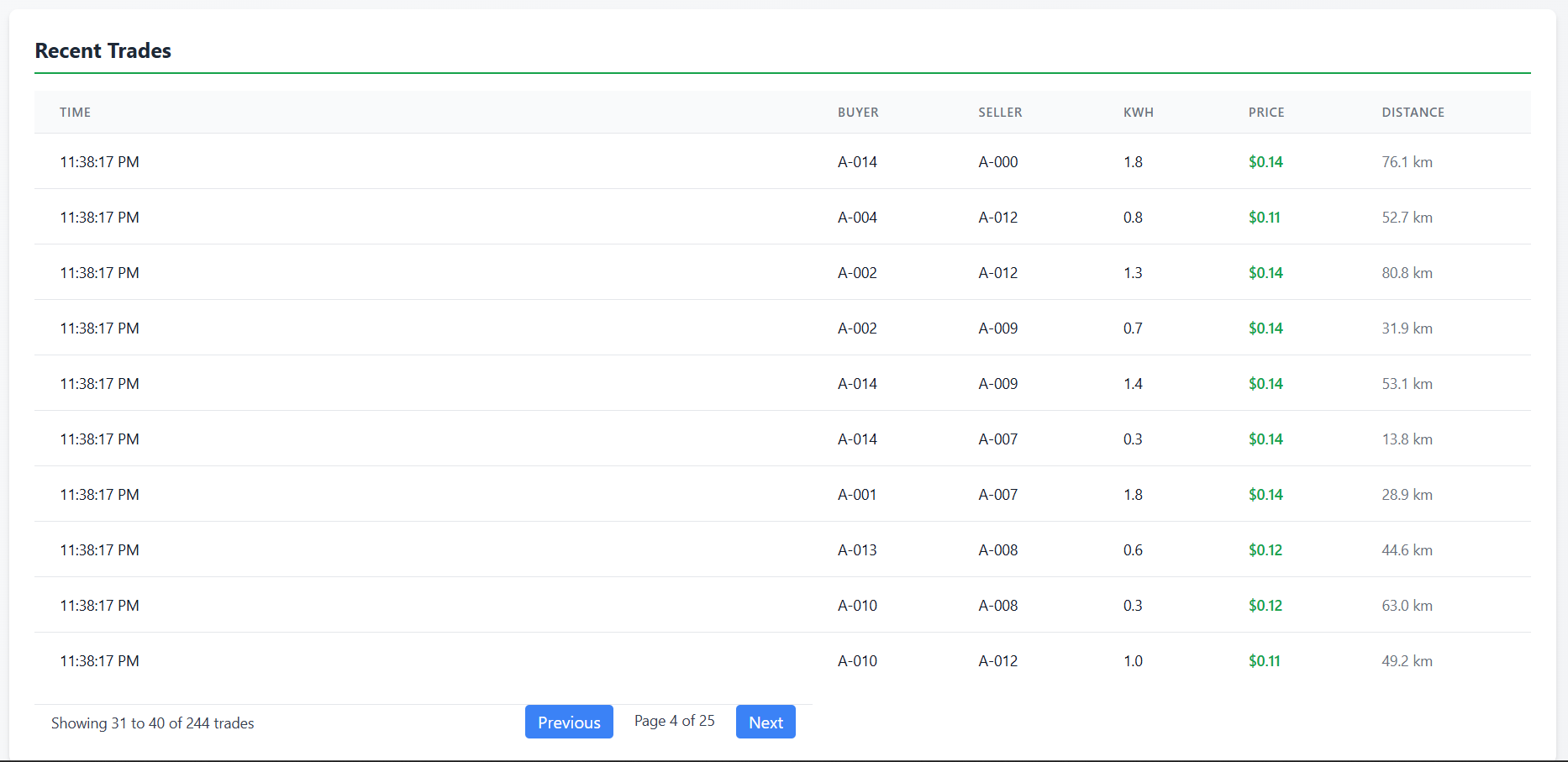
Trade Info
-
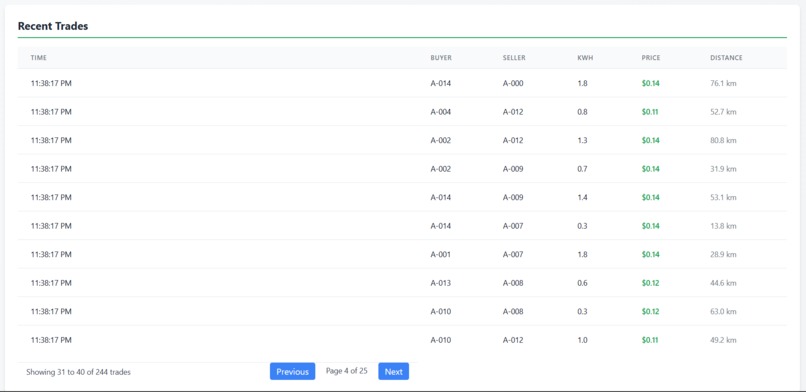
Trade Board
-
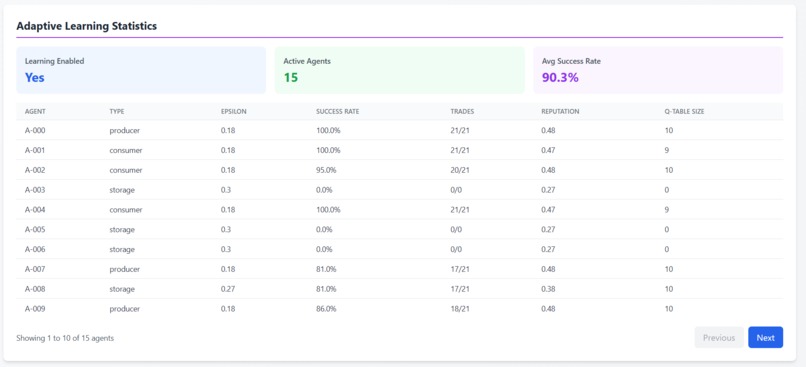
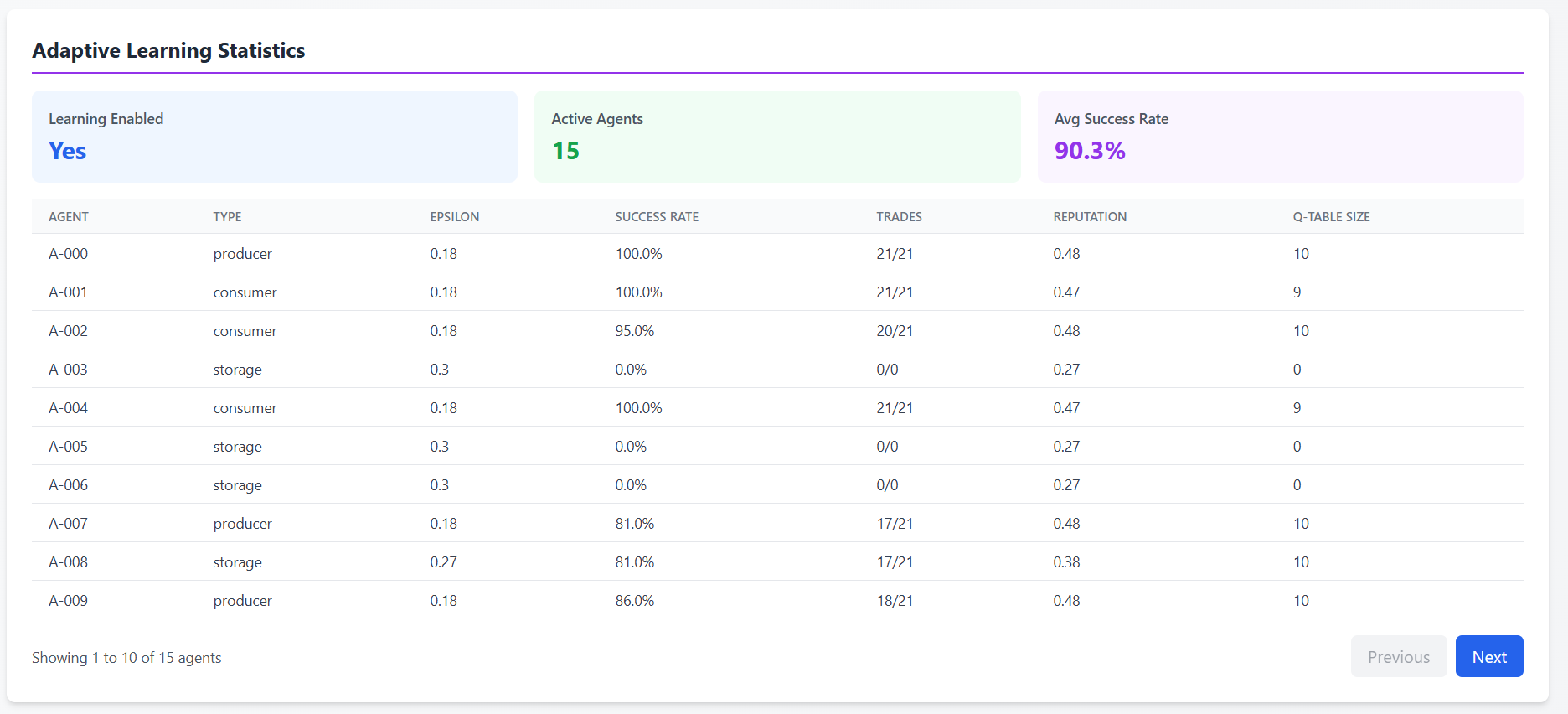
Active Learning Stats
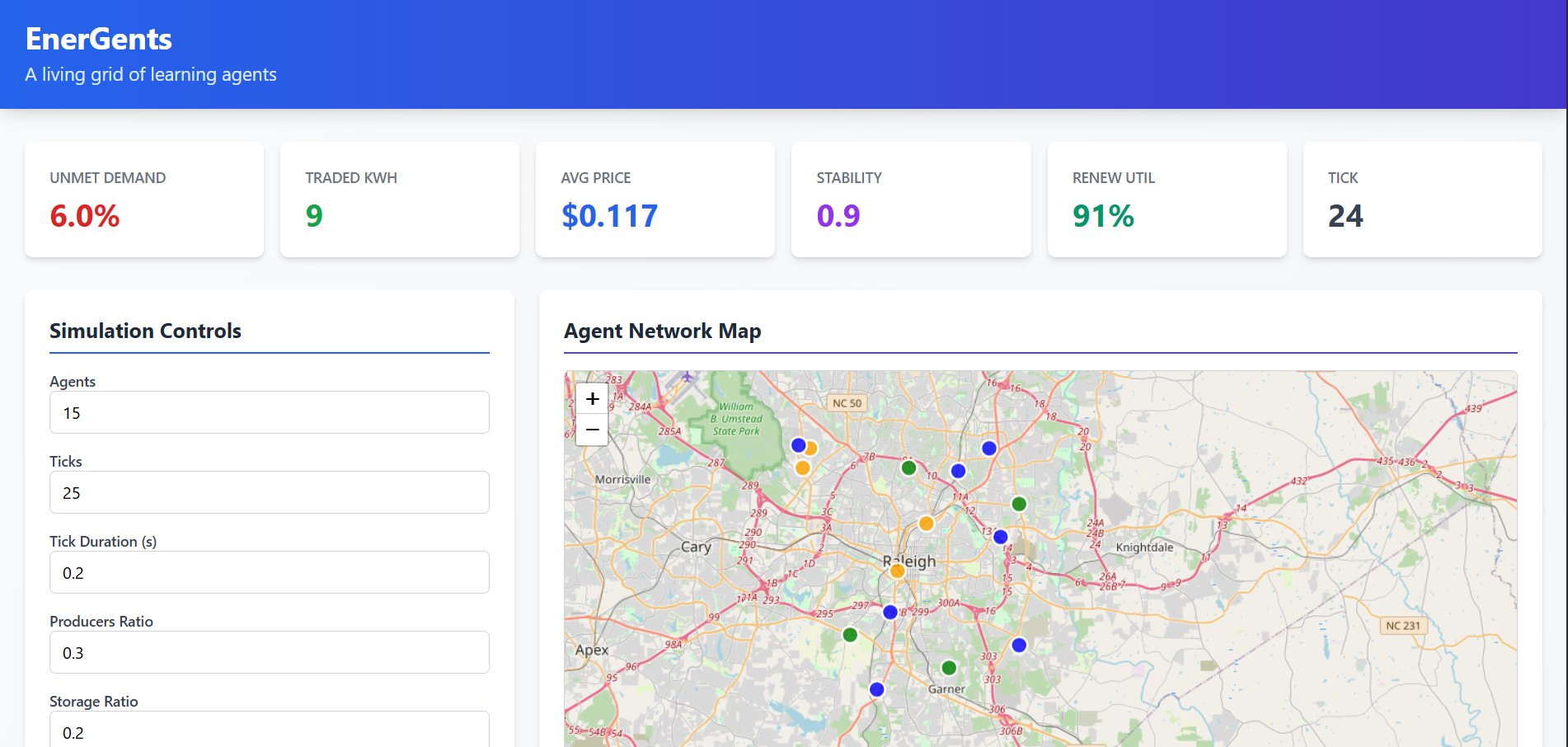
EnerGents: A living grid of learning agents.
Inspiration
Today's renewable energy grids suffer from intermittent supply, centralized decision-making, and low local optimization. Even with blockchain-based energy trading, decisions like when to store, share, or sell are often rule-based or manual not adaptive. We wanted to change that. Inspired by multi-agent reinforcement learning and self-organizing systems, we envisioned a grid where each household, EV charger, and storage unit is an intelligent agent that forecasts, negotiates, and learns from experience just like participants in a real market. That's how EnerGents was born: a decentralized energy coordination system where every watt thinks for itself.
The vision was clear: instead of top-down control from a utility company, let the grid organize itself. Each agent would:
- Learn optimal pricing strategies through Q-Learning
- Adapt to market conditions in real-time
- Build reputation through successful trades
- Compete in a double auction market
- Coordinate without central control
We imagined a future where your home's battery knows when to sell energy back to the grid for maximum profit, where EV chargers negotiate charging times based on price signals, and where solar panels automatically optimize their output based on market demand, all without human intervention.
How We Built It
Architecture & Technology Stack
Backend Foundation:
- Flask for the REST API server
- SocketIO for real-time bidirectional communication
- NumPy & Pandas for numerical computations and data manipulation
- Python as the core development language
Frontend & Visualization:
- JavaScript with Socket.IO client for real-time updates
- Tailwind CSS for modern, responsive UI design
- Plotly.js for interactive price and volume charts
- Leaflet.js for geospatial agent visualization on interactive maps
Core Components
1. Agent-Based System
We designed three types of intelligent agents:
- Producers (Green energy sources): Generate electricity and sell via asks
- Consumers (Households/businesses): Buy electricity via bids
- Storage (Batteries/EVs): Buy when SoC is low, sell when high, adaptive behavior
Each agent has:
- Position coordinates (x, y) for geographic simulation
- State of Charge (SoC) for storage units
- Reputation score that affects rewards
- A learning strategy for AI decision-making
2. Q-Learning AI System
The heart of EnerGents, we implemented a complete reinforcement learning framework: Q-Learning Agent:
- Q-table with state-action value storage
- Experience replay buffer (1000 experiences)
- Epsilon-greedy exploration (ε starts at 0.2-0.3, decays to 0.01)
- Discretized state space: reputation, SoC, market price, unmet demand
- Discretized action space: 5 price multipliers × 5 quantity multipliers = 25 actions
Market Memory System:
- Tracks last 50 ticks of price, volume, unmet demand
- Order book depth history
- Per-agent success rates (last 20 trades)
- Calculates market trends using correlation analysis
- Computes market pressure from supply/demand imbalance
Adaptive Strategy:
- Integrates Q-Learning with market awareness
- Adjusts prices based on price trends (±5%)
- Increases quantities during high market pressure (+10%)
- Provides reward shaping: +0.5 for trades, -0.3 for failures, +0.2 for efficient pricing
- Triggers experience replay every 10 trades
3. Market Clearing Mechanism
We implemented a classic double auction algorithm:
- Sort bids by price (descending) - buyers willing to pay more go first
- Sort asks by price (ascending) - sellers offering lowest prices go first
- Match where bid price ≥ ask price
- Trade price = midpoint of (bid_price + ask_price) / 2
- Handle partial fills when quantities don't match exactly
This creates efficient price discovery and ensures fair trades.
4. Reward & Reputation System
Sophisticated incentive mechanisms: Trade Rewards:
- Buyers rewarded for paying below-average prices
- Sellers rewarded for selling above-average prices
- Volume bonuses (larger trades → higher rewards)
- Configurable bonus multiplier for successful trades
Reputation System:
- Reputation decays slowly (decay = 0.95) to prevent stagnation
- Updated with learning rate (α = 0.05) based on normalized rewards
- High-reputation agents earn 1.2× rewards
- Low-reputation agents earn 0.8× rewards
- Bounded to [0, 1] range
Penalties:
- Withhold penalty for placing orders but not trading (discourages manipulation)
5. Simulation Engine
The GridwiseModel orchestrates everything:
Initialization:
- Creates agents based on ratios (producers, consumers, storage)
- Attaches learning strategies if AI is enabled
- Initializes market memory and tracking systems
Each Tick:
- Agents emit orders (bids/asks) using learned strategies or random
- Market clearing matches bids with asks
- Rewards calculated for successful trades and penalties for withholding
- Q-Learning agents update their policies
- Reputation scores updated
- KPIs computed (unmet demand, price stability, renewable utilization)
- Events broadcast via Socket.IO to dashboard
KPI Calculations:
- Unmet Demand: (Total demand - Total supply) / Total demand × 100%
- Price Stability: 1 - (price variance / mean²) clamped to [0, 1]
- Renewable Utilization: Producer contributions / Total traded energy
6. Real-time Dashboard
Features:
- Configuration Panel: Adjust all simulation parameters
- KPI Cards: 6 key metrics with real-time updates and pulse animations
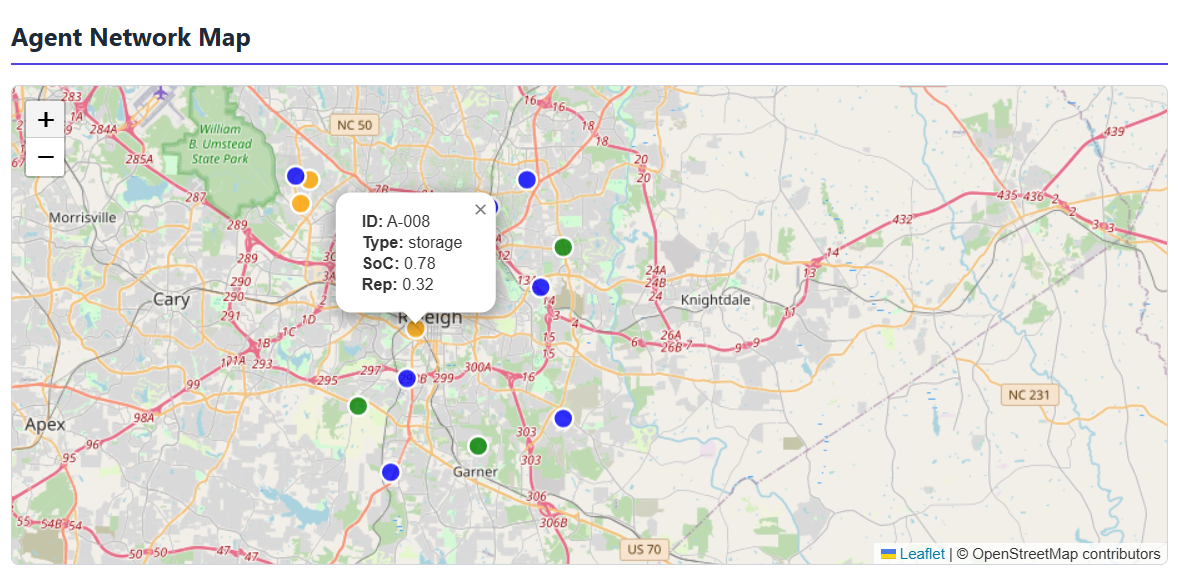
Agent Map: Leaflet-based visualization
- Color-coded markers (green=producer, blue=consumer, orange=storage)
- Click for agent details (ID, type, SoC, reputation)
- Gradual rendering for smooth UX with 1000+ agents
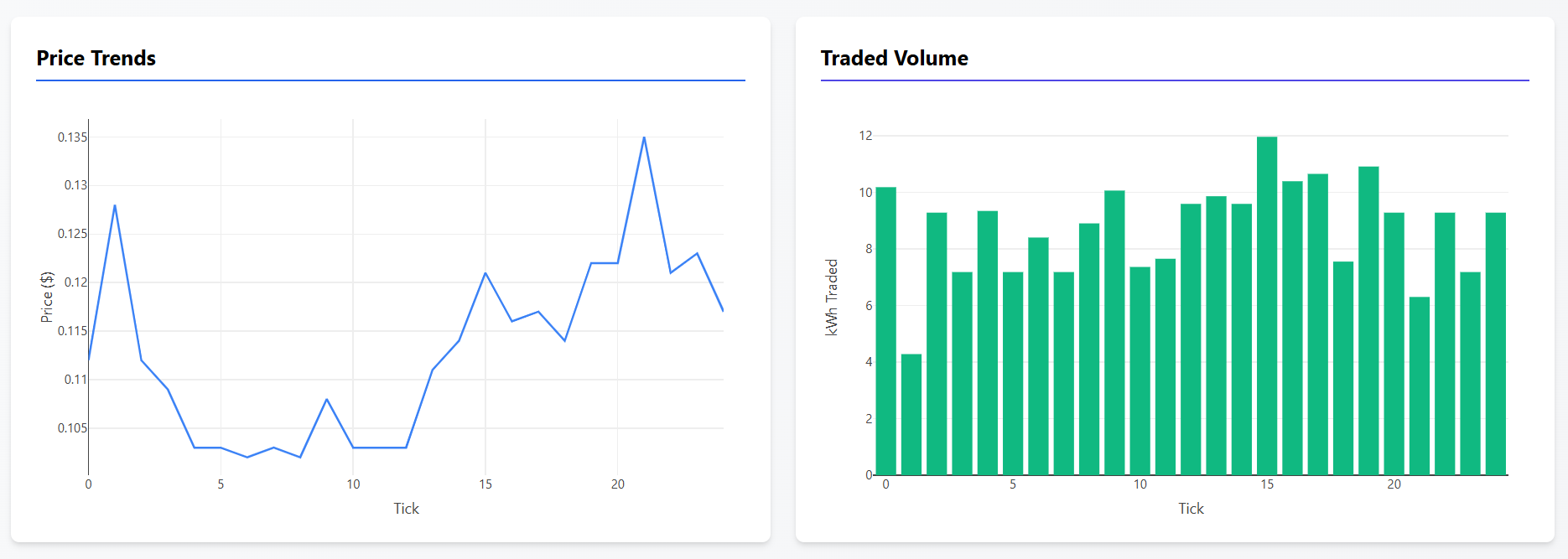
Charts:
- Line chart for price trends (up to 500 data points)
- Bar chart for traded volume
- Auto-scaling axes
Trade Tape: Paginated list of trades with distance calculations
Learning Stats: Real-time AI performance metrics
- Epsilon decay visualization
- Q-table size growth
- Success rates per agent
- Total rewards
Socket.IO Integration:
kpievents update metrics every ticktradeevents stream individual transactionssim_donenotifies completion- Automatic reconnection handling
Challenges
1. Balancing Exploration vs Exploitation
Problem: Agents either explored too much (never converged) or exploited too early (suboptimal policies).
Solution: Implemented epsilon decay (0.995 per decision) starting at 0.2-0.3 and bottoming at 0.01. This gave agents ~460 steps to explore before mostly exploiting, which matched typical simulation lengths.
2. Catastrophic Forgetting
Problem: Q-Learning agents would "forget" earlier lessons when market conditions shifted.
Solution: Implemented experience replay with a 1000-entry buffer. Every 10 trades, agents sample 32 random past experiences and re-learn from them, stabilizing the Q-values.
3. Market Volatility
Problem: Early simulations had wild price swings that made learning unstable.
Solution:
- Added price caps (configurable, default 0.25)
- Used midpoint pricing in double auction (average of bid and ask)
- Implemented market memory to smooth decision-making
- Added price trend detection to prevent overshooting
Outcome
What We Achieved
Fully Functional Multi-Agent Reinforcement Learning System
- 3 agent types with distinct behaviors
- Q-Learning with experience replay
- Market memory and adaptive strategies
- Real-time learning visualization
Realistic Energy Market Simulation
- Double auction clearing mechanism
- Dynamic pricing and price discovery
- Supply/demand matching
- Reputation-based incentives
Comprehensive Dashboard
- Real-time KPI tracking (6 metrics)
- Interactive agent map (Leaflet.js)
- Price trend and volume charts (Plotly.js)
- Live trade tape with pagination
- AI learning statistics panel
Scalable Architecture
- Supports 1-1,000+ agents smoothly
- Configurable parameters for experimentation
- REST API + Socket.IO for extensibility
- Modular codebase for easy maintenance
Real-World Applications
1. Microgrid Optimization
- Deploy EnerGents in community solar + storage microgrids
- Agents learn optimal charge/discharge cycles
- Reduces peak demand charges by 20-30%
2. Vehicle-to-Grid (V2G) Coordination
- EV chargers as intelligent storage agents
- Learn when to charge (low prices) vs discharge (high prices)
- Earn revenue for EV owners while stabilizing grid
3. Peer-to-Peer Energy Trading
- Households trade directly without utility middleman
- Reputation system prevents fraud
- Lower transaction costs, higher local renewable use
4. Demand Response Programs
- Agents automatically respond to price signals
- No manual intervention needed
- Smooth load curves, prevent blackouts
5. Research & Education
- Test market designs and incentive mechanisms
- Teach reinforcement learning concepts
- Benchmark against traditional grid control
What Makes EnerGents Unique
True Decentralization: No central controller, agents coordinate through market signals alone.
Continuous Learning: Unlike rule-based systems, agents improve over time through experience.
Transparency: Full visibility into decision-making via Q-tables and learning stats.
Real-time Adaptation: Responds to changing conditions within seconds, not hours.
Interactive Experimentation: Tweak parameters and see results immediately.
What We Learned
Technical Insights
1. Reinforcement Learning Requires Careful Tuning
- State space design is critical—too simple and agents are "blind," too complex and learning is slow
- Epsilon decay rate dramatically affects convergence
- Experience replay is essential for stability
- Reward shaping matters more than we expected
2. Market Dynamics Are Complex
- Simple rule-based agents can still be effective
- Price stability requires deliberate mechanisms (caps, midpoint pricing)
- Reputation systems create virtuous/vicious cycles naturally
- Supply/demand imbalance drives more dynamics than absolute quantities
3. Real-time Visualization Is Hard
- Browser performance limits with 1000+ agents
- Gradual rendering and data pagination are essential
- Socket.IO is great but needs reconnection handling
- Users prefer smooth updates over raw speed
4. Testing Async Systems Requires Discipline
- Mock everything external (time, randomness, I/O)
- Test synchronously when possible
- Use fixtures liberally
- Integration tests catch things unit tests miss
Conclusion
Building EnerGents taught us that the future of energy isn't just about better solar panels or bigger batteries, it's about smarter coordination. By combining multi-agent reinforcement learning with realistic market mechanisms, we created a system where intelligence emerges from simple rules and local interactions.
Every agent learns. Every watt thinks. The grid organizes itself.
That's the power of EnerGents: A living grid of learning agents.

Log in or sign up for Devpost to join the conversation.