-
load
-
main
-
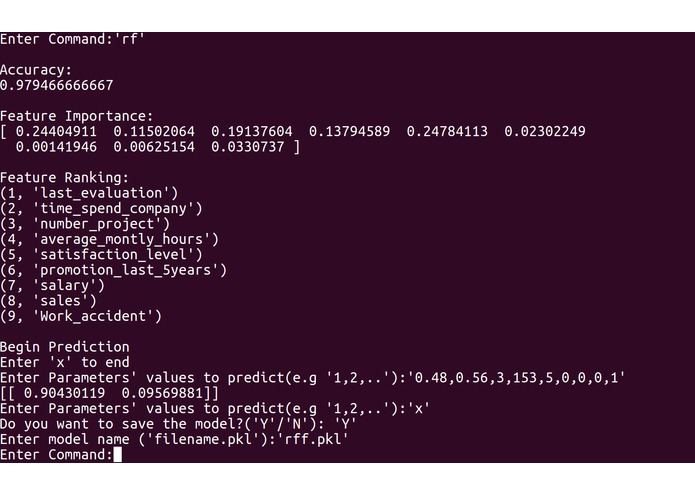
RF
-
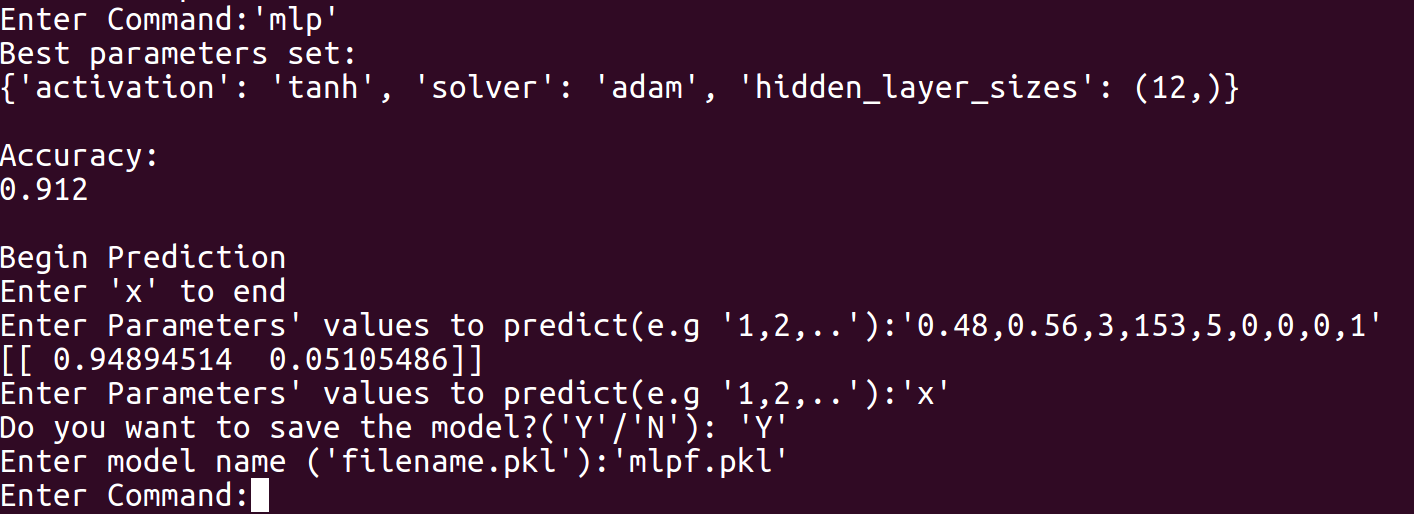
MLP
-
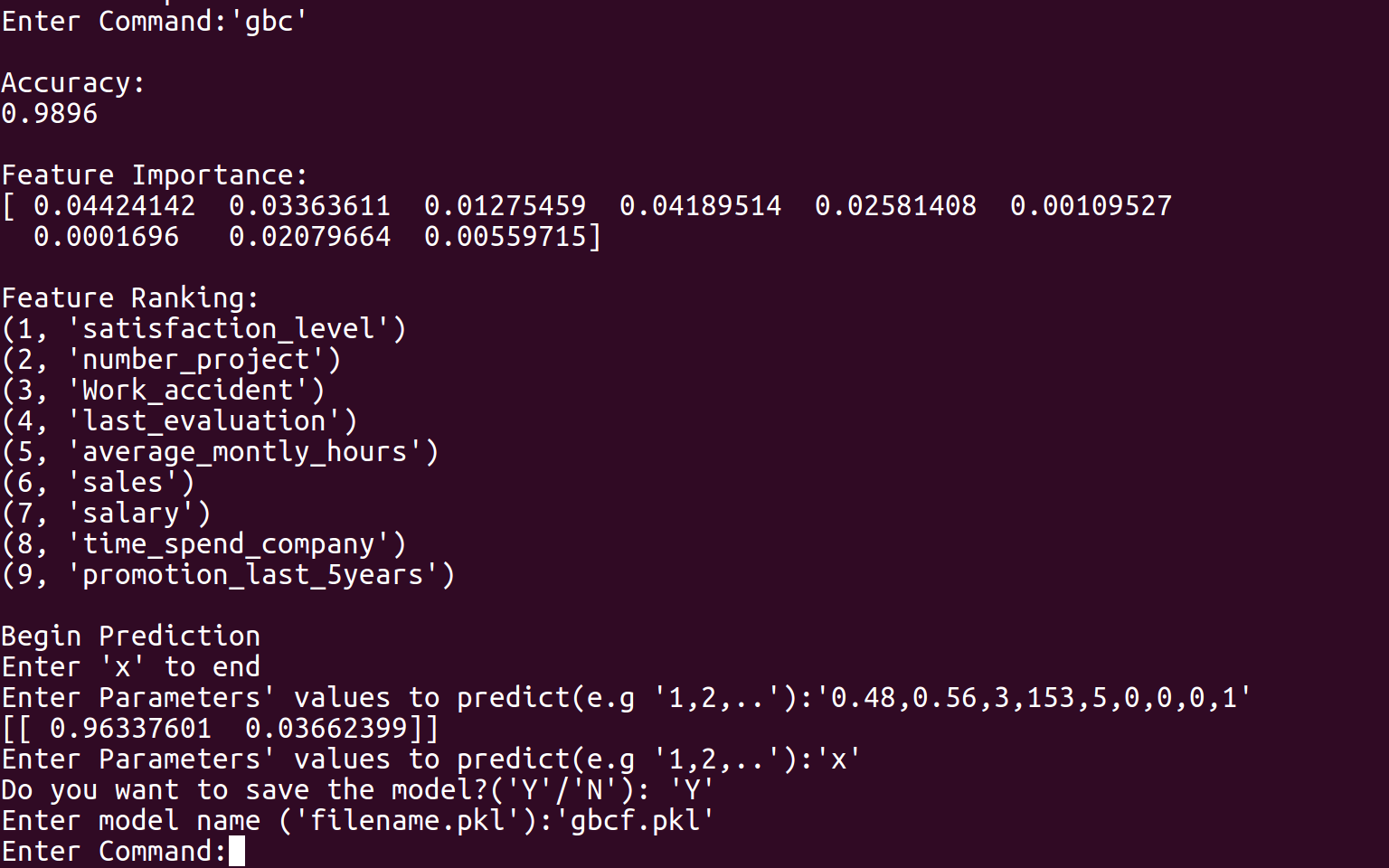
GBC
-


Inspiration
One of the main concerns of HR departments in companies is to retain critical talent within the companies. However, as most HR departments lack expertise in calculating risks, we aim to create a comprehensive and efficient model which allow users to calculate risk scores for individual employees leaving and evaluate significant factors leading to employees' dissatisfaction along with suggestions for improvements with certain constraints imposed. We also want to create a model which can be updated on a regular basis for optimal accuracy and relevance. With the presence of large numbers of predictor variables and complex non-linear variable interactions involved, we used various machine learning techniques to create our predictive model. The use of machine learning feeds to the flexibility of our model, as HR managers can pick any employee factors (e.g. salary, department, etc.) for this predictive analysis. We hope to facilitate employee engagement and retention plans within companies and ultimately achieve a win-win situation between employees and employers.
What it does
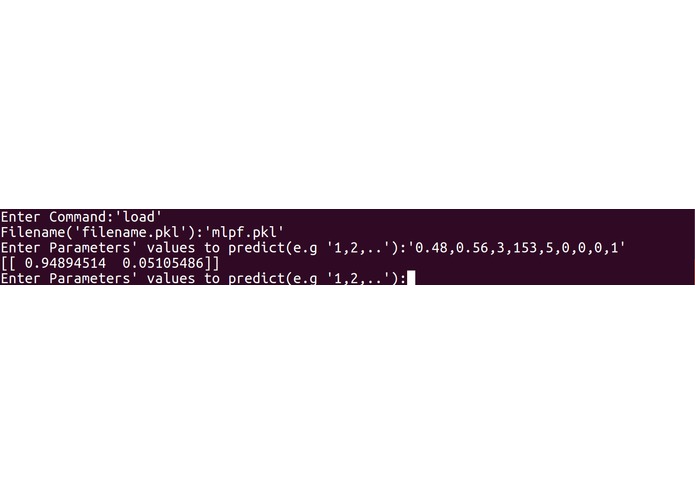
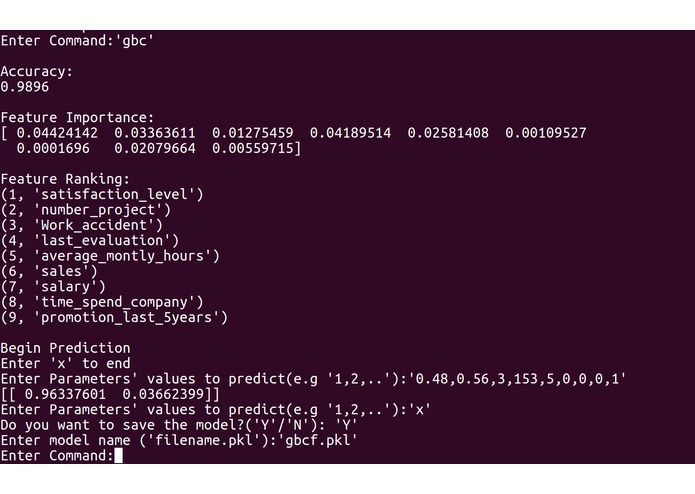
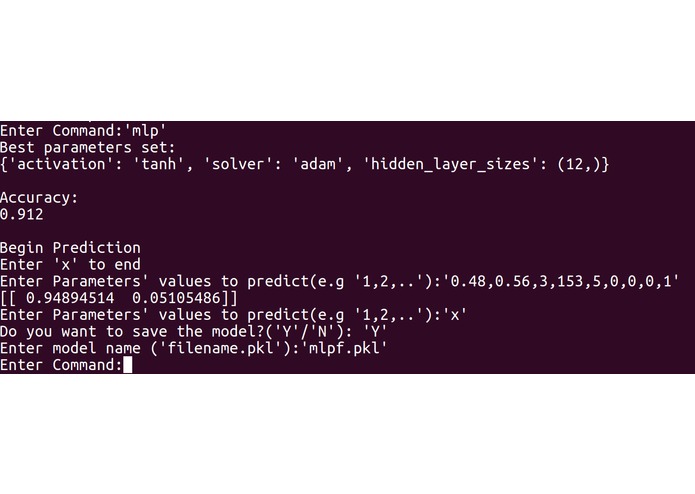
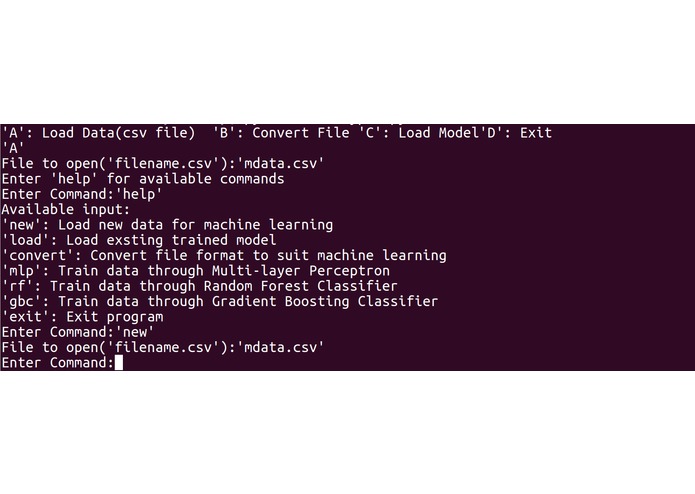
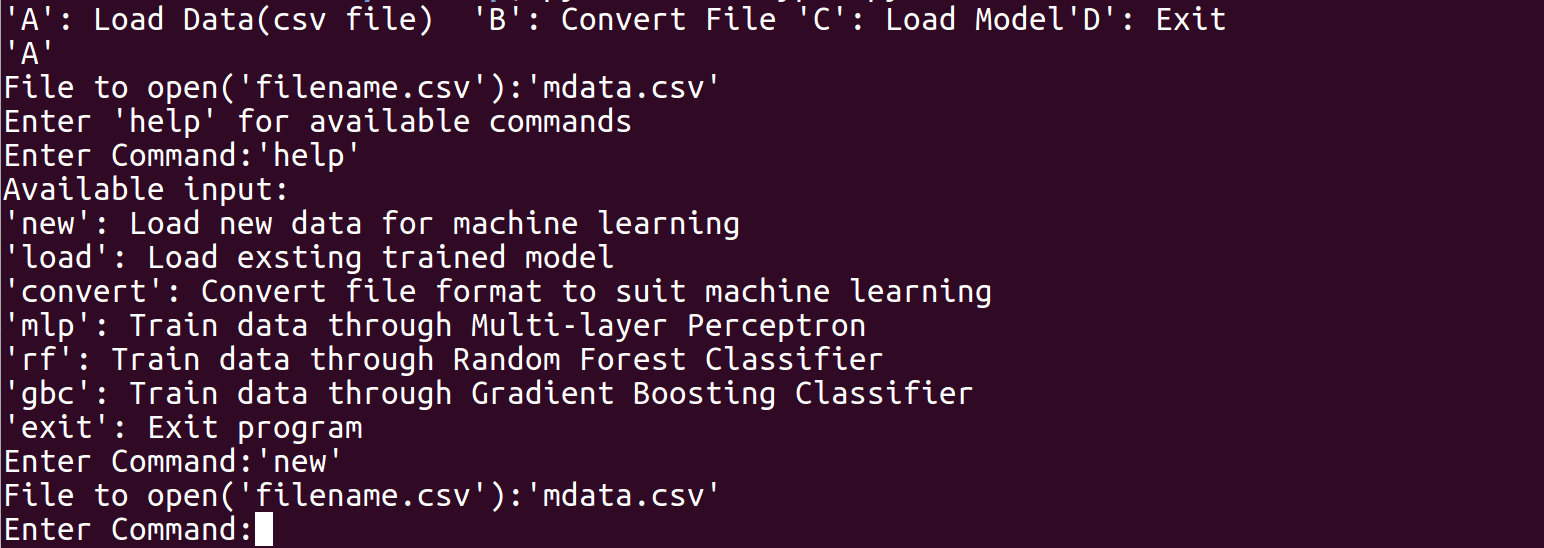
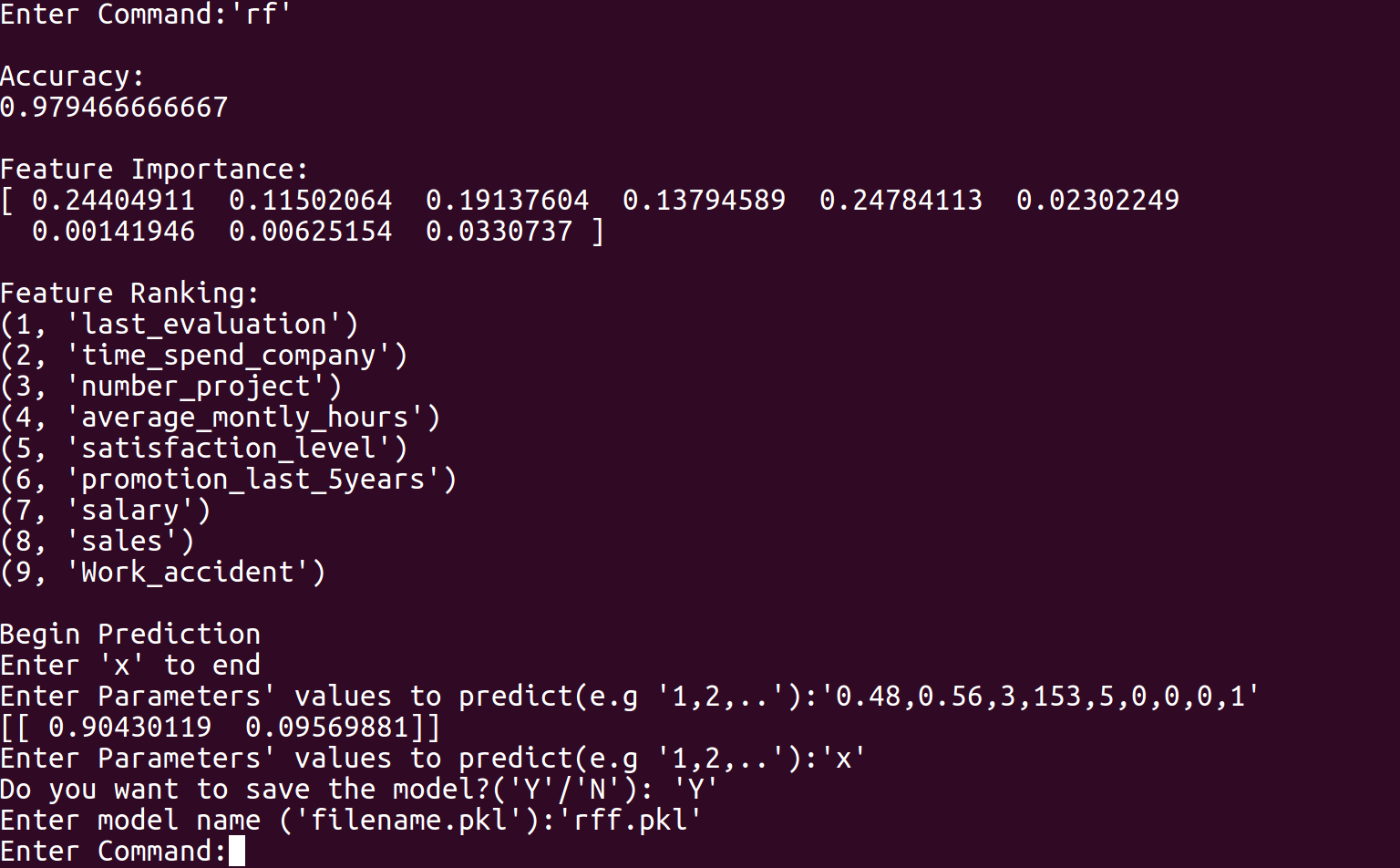
Our program first requires the input of past companies data from the user in a spreadsheet (.csv) file. The spreadsheet does not necessarily have to be in numerical form as our program converts strings to numbers. The program then requests user to choose one out of three modelling techniques, namely MultiLayer Perceptron (MLP), Random Forest (RF) and Gradient Boosting Classifier (GBC). Each model will output its precision, while the rf and gbc allows feature ranking, which finds the more important employee factors. The user can then choose the model to use based on accuracy and need for feature ranking, and conduct further predictive analysis with the chosen model. In order to produce suggestions for employees to maximize chance of employees to say, Genetic Algorithm (GA) was tested but not implemented into the final program, due to lack of consistency and reproducibility, and was thus added to future plans.
How I built it
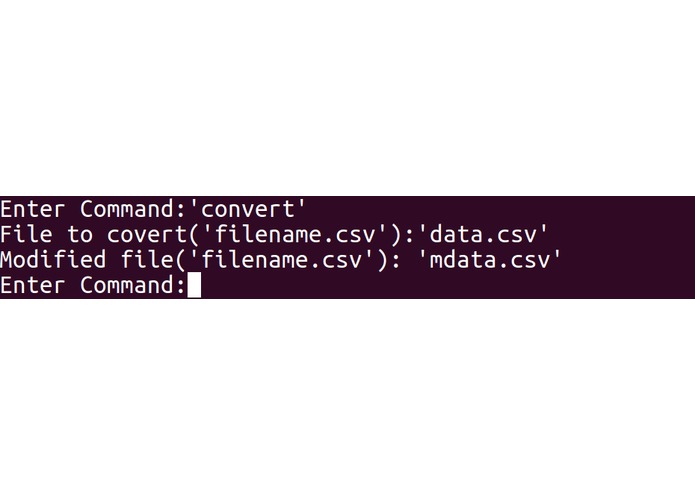
Our modelling program is built based on Python and constructed in a Read-Eval-Print Loop (REPL) style. The program was decomposed into three main segments: input processing, modelling and user interface. For input processing, the csv file inputted by the user is first modified in which string values are converted to float values for processing purposes. The input data are then split into two tests, one for training and the other for testing. If the training data is skewed by a certain degree, Synthetic Minority Over-Sampling Technique (SMOTE) is used to balance the data to correct oversampling. For modelling, three training machine learning models were created: MLP, RF and GBC. In MLP, to find the best activation function, solver and estimate number of hidden layers, an exhaustive approach was taken. In both RF and GBC, with the help of machine learning modules, we carried out data training and accuracy calculation of models based on testing data. By carrying out simple comparisons using values obtained from feature importance, we managed to rank features by their importance. Lastly, regarding user interface, we adhered to a REPL style of coding, as users can choose which models to use and save, and conduct other useful features. Snippets of our codes and our python code are attached for more details.
Challenges I ran into
While our main goal was to create a program which efficiently trains models for predictive analysis, we were also hoping to design a user-interface that is more user-friendly and simpler to interact especially for users who lack knowledge in coding. However, due to time constraints, we were unable to complete that.
As our team had minimal experience in machine learning, we initially had problems fully grasping the idea of various machine learning techniques such as genetic algorithm. Instead of immediately delving into the coding part of our project at the start, we spent an hour browsing the web and YouTube videos to have a deeper understanding in machine learning.
As this is our team's first hackathon, we were not used to the long period of brainstorming and coding, leading to fatigue and lost of concentration throughout the hackathon. However, with proper time management and task delegation, we are satisfied with our end product and also had fun throughout the process.
We also wanted to implement plot.ly in our program, to plot graphs which acts as visual aids for more comprehensive understanding of our models results. Due to lack of knowledge and time, we decided that it is not a significant feature to be implemented in our prototype.
Accomplishments that I'm proud of
Completed our first hackathon project!! Designed a solution that may possibly contribute to bigger projects. Stayed awake for 20+ hours!
What I learned
How to use a variety of machine learning modules in Python. How to use pandas instead of csv modules to modify csv files in a more modern and efficient way. How to work together as a team and delegate tasks based on one's strength and interest.
Future plans
Implement Genetic Algorithm (GA) to provide suggestions for optimal parameters to reach satisfactory threshold for probability of employees to stay in their companies. Also, user can choose which parameter to alter. User-friendly interface for aesthetic and convenience purposes. Implementation of UI graphs for visualizing purposes.


Log in or sign up for Devpost to join the conversation.