-
-
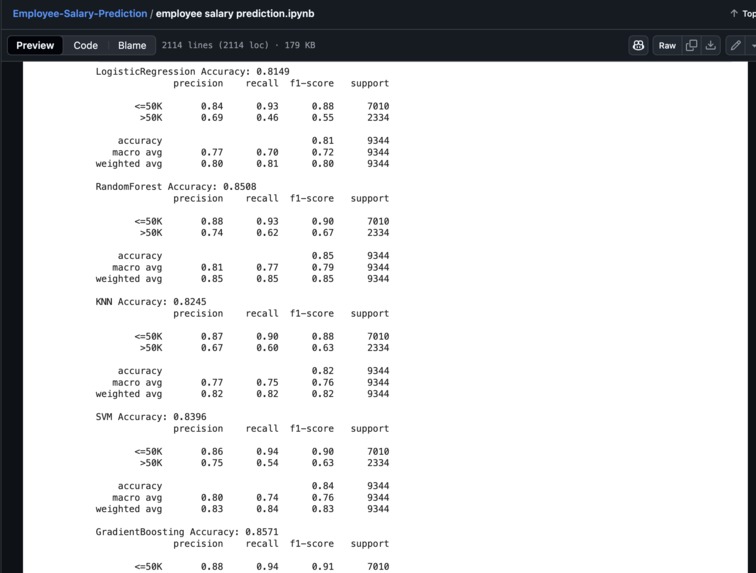
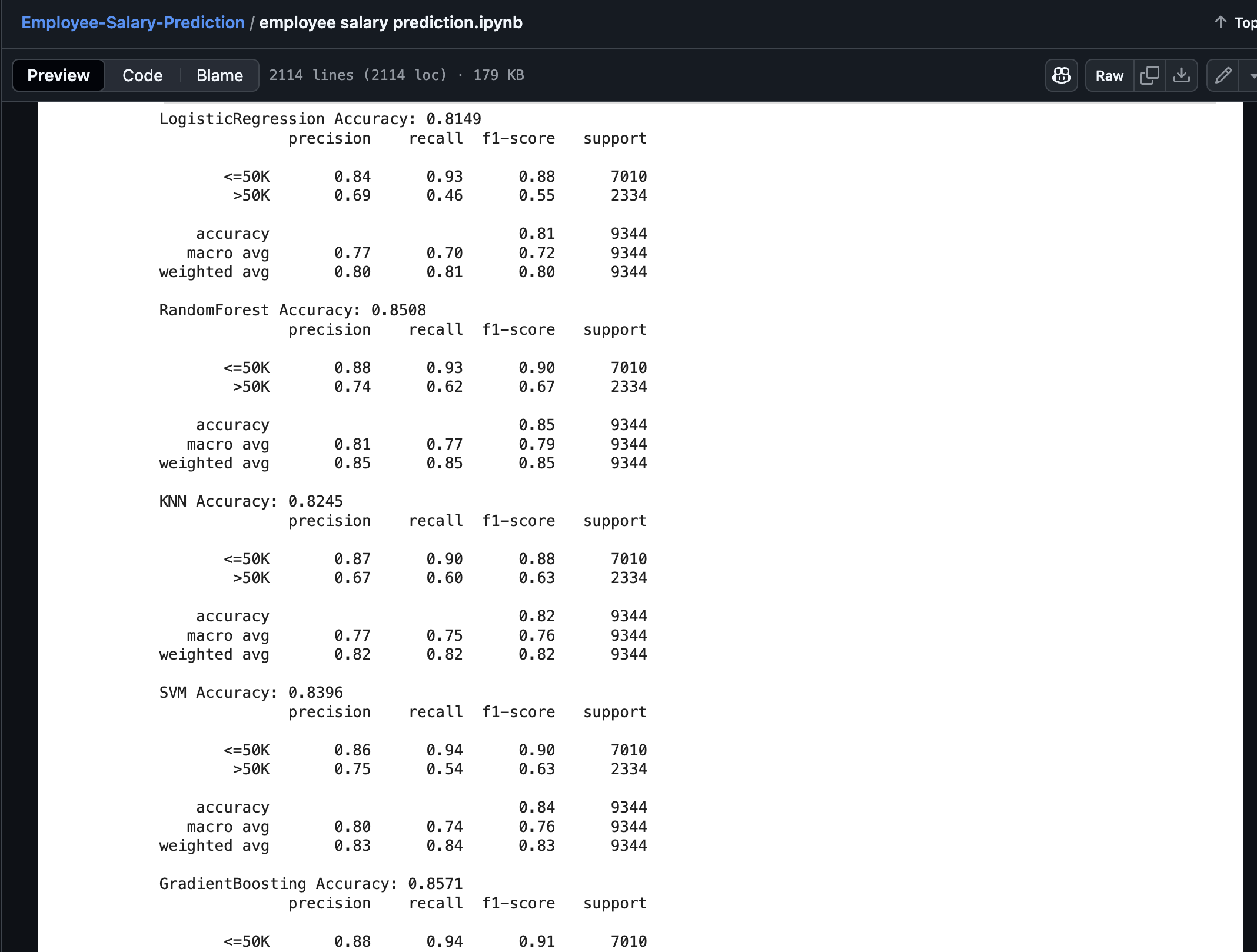
Accuracy of various ML Algorithms
-
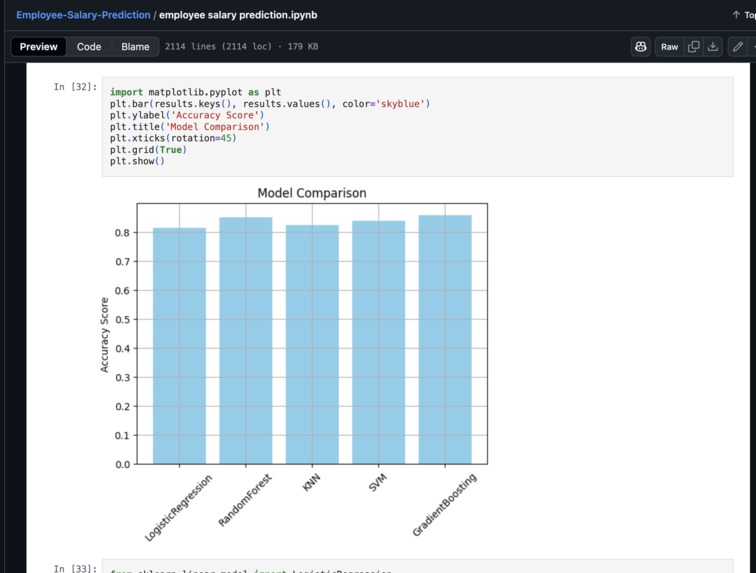
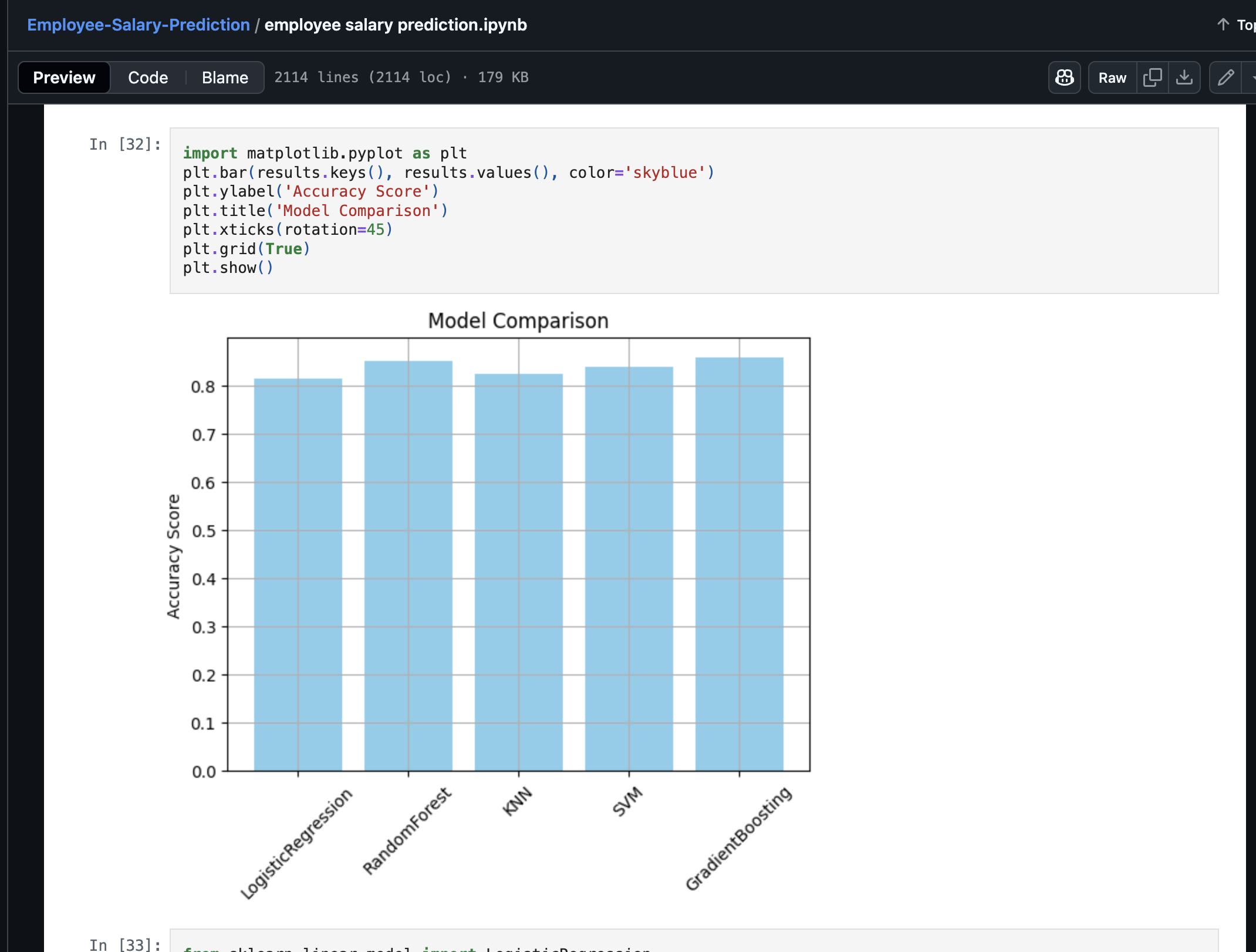
Model comparison using Matplotlib library
-
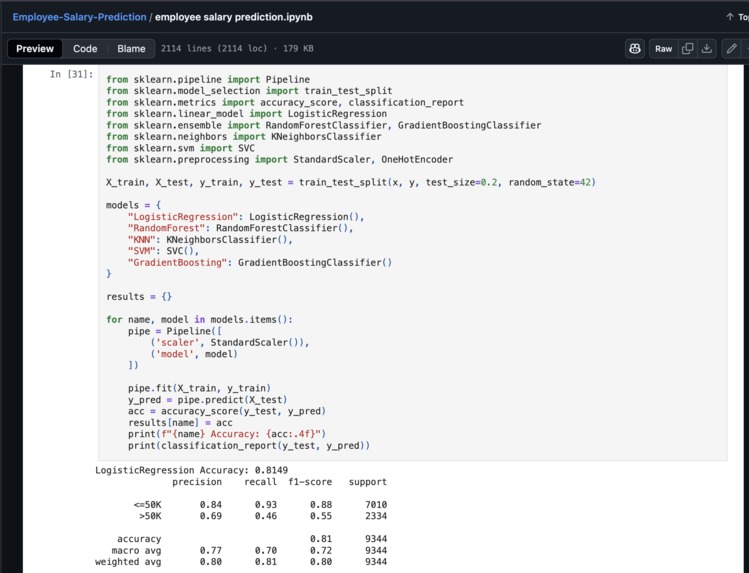
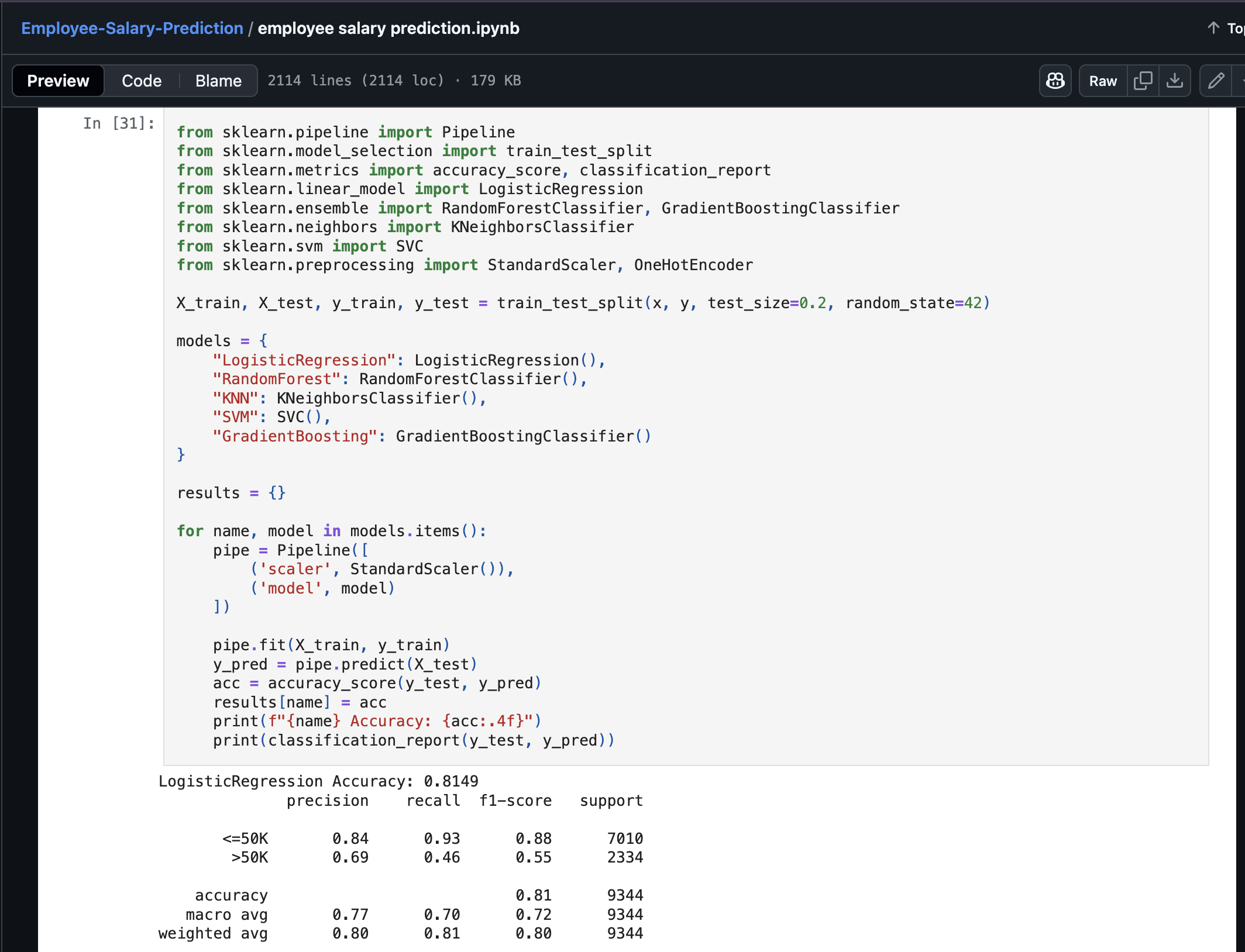
Code for various Machine learning Algorithms
-
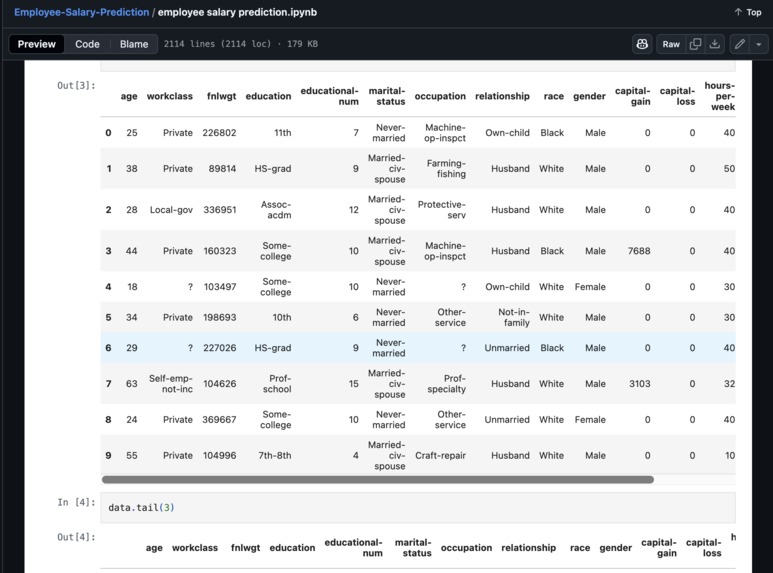
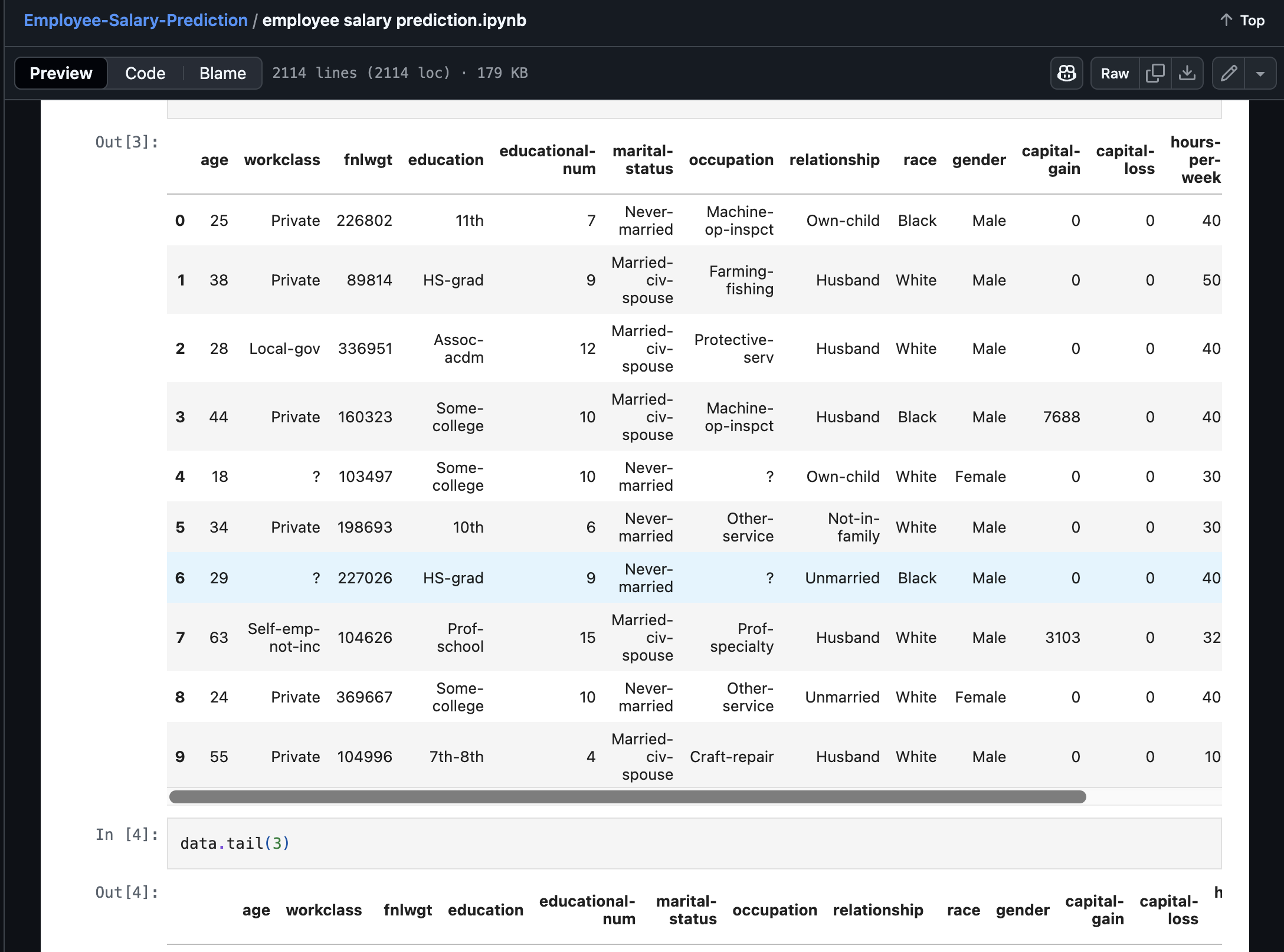
The data in which I have worked on.
Employee Salary Prediction using K-Nearest Neighbors
🚀 About the Project
What Inspired Me
In today's competitive job market, understanding salary patterns has become crucial for both employers and job seekers. I was inspired by the challenge of creating a machine learning model that could predict whether an individual's income exceeds $50K based on demographic and employment characteristics. This project stemmed from my curiosity about income inequality and the factors that truly influence earning potential in modern society.
The Adult Census Income dataset provided the perfect opportunity to explore this socio-economic question through the lens of data science, making it both technically challenging and socially relevant.
What I Learned
This project was a deep dive into the complete machine learning pipeline, teaching me invaluable lessons:
Data Preprocessing is King: I discovered that nearly 70% of the work involves cleaning and preparing data. Handling missing values represented as
'?'strings taught me the importance of thorough data exploration.Feature Engineering Matters: The decision to drop the
educationcolumn while keepingeducation-numshowed me how redundant features can impact model performance.The Power of KNN: I learned that K-Nearest Neighbors, while simple conceptually, can achieve impressive results (81.68% accuracy) when properly tuned and scaled.
Scaling is Critical: Without
MinMaxScaler, the KNN algorithm would be dominated by features with larger scales likecapital-gainandcapital-loss.
How I Built the Project
1. Data Exploration & Understanding
# Initial exploration revealed the dataset structure
data.shape # (48842, 15) - substantial dataset for training
data.isna().sum() # No traditional NaN values, but '?' strings present
The Adult dataset contains 48,842 records with 15 features including age, work class, education, marital status, occupation, and more.
2. Data Cleaning & Preprocessing
My preprocessing strategy involved several key steps:
Missing Value Handling:
# Replaced '?' with 'Others' for categorical consistency
data.workclass.replace({'?':'Others'}, inplace=True)
data.occupation.replace({'?':'Others'}, inplace=True)
Outlier Management:
# Filtered age to realistic working range
data = data[(data['age']<=75) & (data['age']>=17)]
Data Quality Enhancement:
- Removed categories with minimal representation (
Without-pay,Never-worked) - Eliminated education levels with very low counts (
1st-4th,5th-6th,Preschool) - This reduced dataset from 48,842 to 47,619 records, improving data quality
3. Feature Engineering
Label Encoding for Categorical Variables:
from sklearn.preprocessing import LabelEncoder
encoder = LabelEncoder()
# Encoded all categorical features
categorical_features = ['workclass', 'marital-status', 'occupation',
'relationship', 'race', 'gender', 'native-country']
for feature in categorical_features:
data[feature] = encoder.fit_transform(data[feature])
Feature Scaling:
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
X = scaler.fit_transform(X) # Normalized all features to [0,1] range
4. Model Implementation
Train-Test Split with Stratification:
from sklearn.model_selection import train_test_split
xtrain, xtest, ytrain, ytest = train_test_split(
X, Y, test_size=0.2, random_state=23, stratify=Y
)
Using stratify=Y ensured balanced representation of income classes in both training and testing sets.
KNN Model Training:
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier()
knn.fit(xtrain, ytrain)
predict = knn.predict(xtest)
The Math Behind KNN
The K-Nearest Neighbors algorithm works on the principle of distance-based classification:
For a test point \( x_{test} \), the algorithm:
- Calculates Euclidean distance: \( d(x_i, x_{test}) = \sqrt{\sum_{j=1}^{n}(x_{i,j} - x_{test,j})^2} \)
- Finds the k nearest neighbors
- Predicts class based on majority vote: \( \hat{y} = \text{mode}(y_{k-neighbors}) \)
The scaling step was crucial because without normalization, features like capital-gain (ranging 0-99999) would dominate the distance calculation over binary features.
Results & Performance
The final model achieved:
- Accuracy: 81.68% on the test set
- Dataset Reduction: From 48,842 to 47,619 samples (improved data quality)
- Feature Count: 13 features after preprocessing
$$\text{Accuracy} = \frac{\text{Correct Predictions}}{\text{Total Predictions}} = \frac{7,780}{9,524} = 0.8168$$
Challenges I Faced
1. Hidden Missing Values
The biggest challenge was discovering that missing values were encoded as '?' strings rather than traditional NaN values. This required careful string replacement strategies.
2. Feature Selection Dilemma
Deciding between education (categorical) and education-num (numerical) was tricky. I chose the numerical version for better KNN performance, but this meant losing interpretability.
3. Class Imbalance Considerations
The income distribution was imbalanced (≤50K vs >50K). Using stratify=Y in train-test split helped maintain this ratio across splits.
4. Hyperparameter Tuning
While I included GridSearchCV code for hyperparameter optimization:
# Comprehensive parameter grid for optimization
param_grid = {
'n_neighbors': [3, 5, 7],
'weights': ['uniform', 'distance'],
'algorithm': ['auto', 'ball_tree', 'kd_tree', 'brute'],
}
The computational cost was significant for a hackathon timeline, so I proceeded with default parameters.
Technical Insights
- KNN Sensitivity: The algorithm's performance heavily depends on the choice of k and distance metric
- Curse of Dimensionality: With 13 features, KNN still performed well, but higher dimensions could degrade performance
- Memory vs Speed Trade-off: KNN is a lazy learner, storing all training data but requiring distance calculations for each prediction
Future Enhancements
Given more time, I would explore:
- Advanced preprocessing: SMOTE for handling class imbalance
- Feature selection: Using techniques like Recursive Feature Elimination
- Model ensemble: Combining KNN with other algorithms like Random Forest
- Cross-validation: For more robust performance estimation
Conclusion
This project demonstrated that with careful preprocessing and feature engineering, even simple algorithms like KNN can achieve strong performance on real-world classification tasks. The 81.68% accuracy proves that demographic and employment factors can indeed predict income levels with reasonable confidence.
The journey from raw data to a working model reinforced the importance of understanding your data, making informed preprocessing decisions, and choosing appropriate algorithms for the problem domain. This hackathon project was not just about building a model—it was about understanding the story that data tells about economic opportunity and social mobility.
Built with ❤️ using Python, scikit-learn, and lots of coffee during the hackathon!
Built With
- matplotlib
- python
- scikitlearn

Log in or sign up for Devpost to join the conversation.