-
-
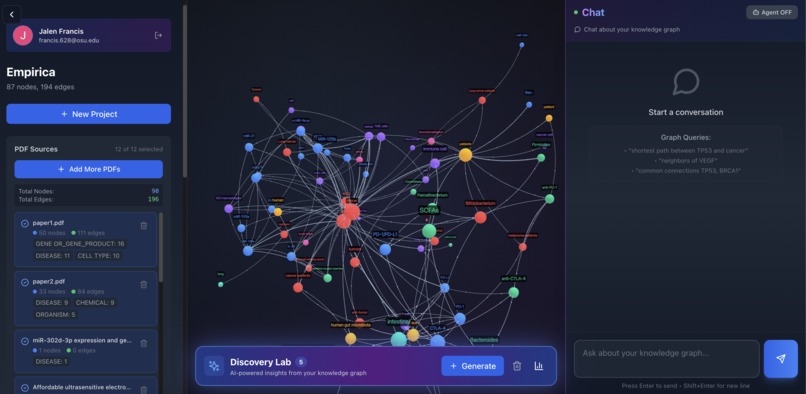
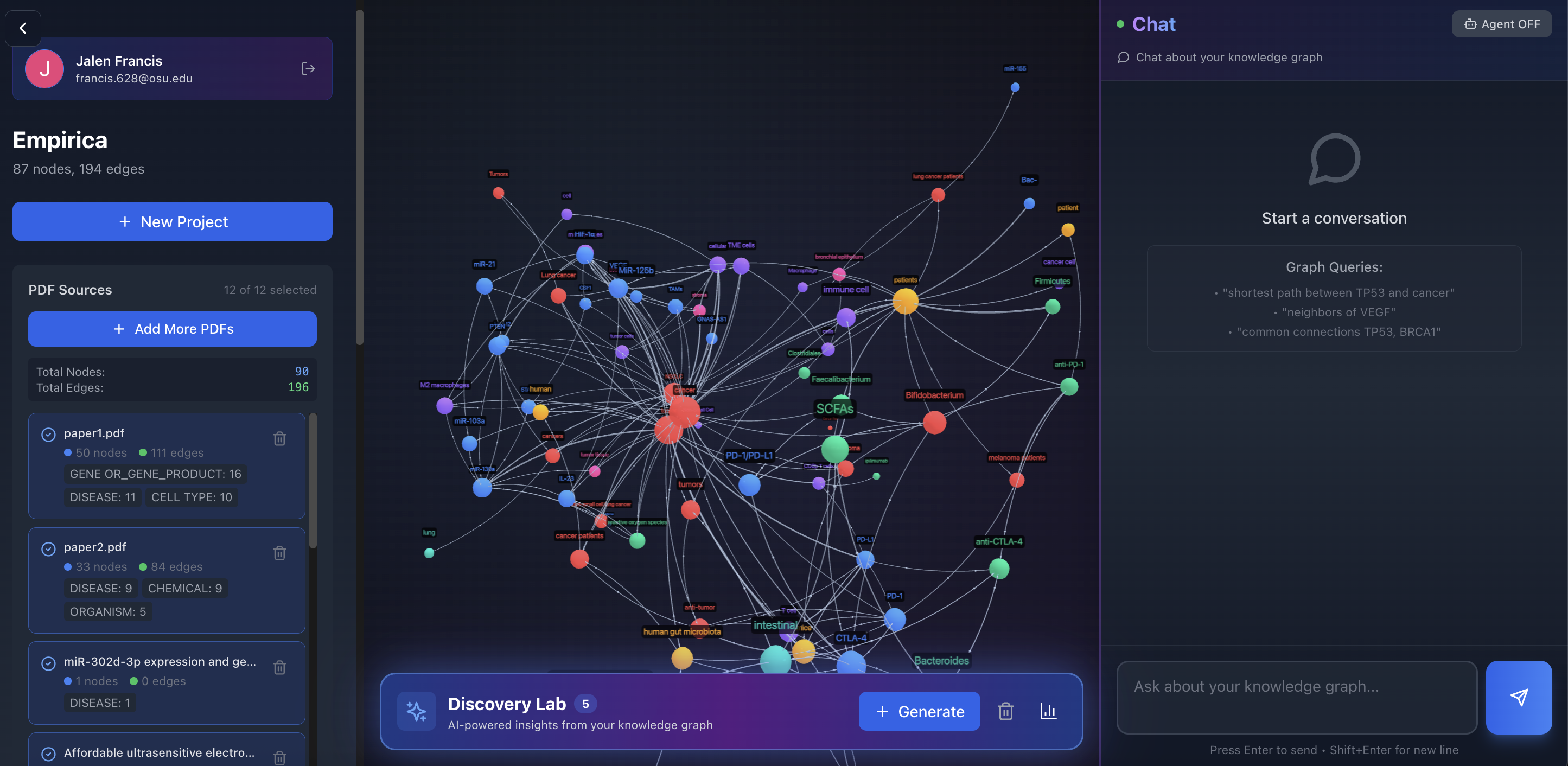
Interacting with 3D Graph
-
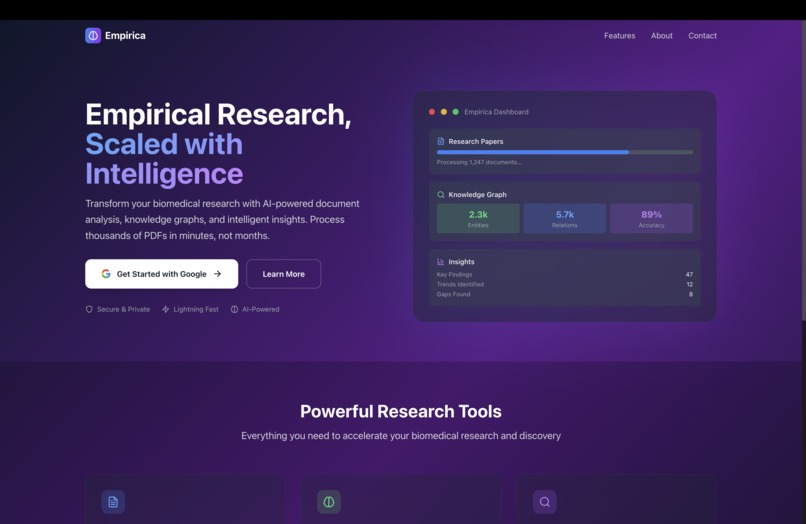
Launch page
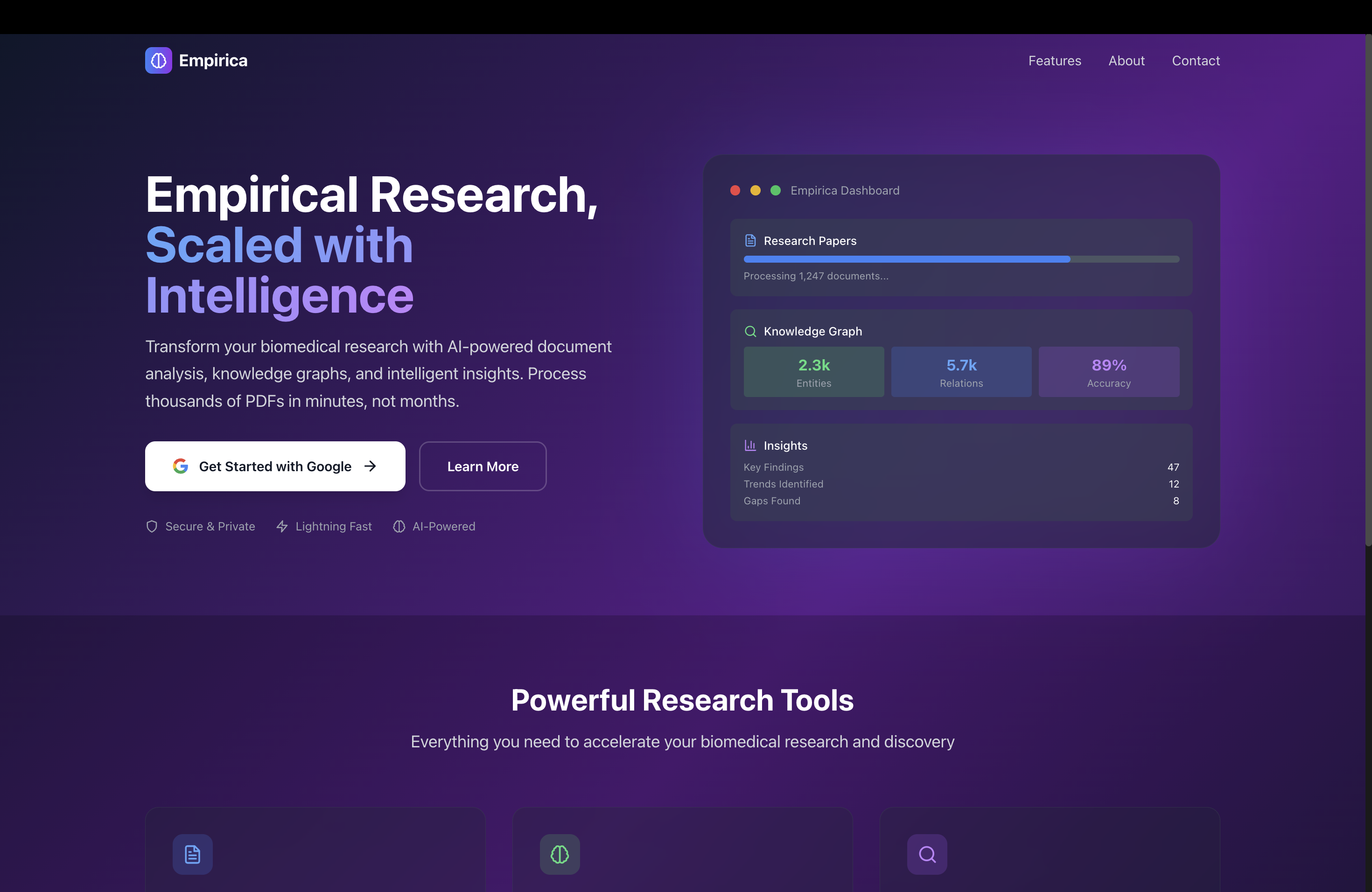
Inspiration
Biomedical researchers spend 15% of an average week up to 50% or more during intense periods of their time on literature review. When working on biomedical research, we realized finding connections across 50+ papers was nearly impossible manually. We needed a way to see the forest, not just the trees. What if AI could not only read papers but actively discover new ones, build knowledge networks, and generate research hypotheses automatically? That's why we built Empirica.
What it does
Empirica transforms biomedical research with three core capabilities:
1. Agentic Research Workflows: Turn on "Agent Mode" and watch Empirica autonomously search PubMed, discover papers via Google Scholar, download PDFs, extract entities, and build knowledge graphs—all while you focus on analysis.
2. Interactive Knowledge Graphs: Visualize genes, diseases, drugs, and their relationships in stunning 2D/3D force-directed graphs. Click nodes to explore connections, filter by entity type, and navigate through your research visually.
3. AI-Powered Intelligence:
- RAG-Enhanced Chat: Ask questions and get answers with exact paper + page citations
- Discovery Lab: AI generates research hypotheses by analyzing graph structure and document content, showing confidence scores and supporting evidence
Every insight is traceable, persistent, and citation-backed.
How we built it
Backend (Python):
- FastAPI for async REST API with OAuth 2.0 authentication
- scispaCy for biomedical named entity recognition (80+ entity types)
- PyMuPDF for PDF text extraction
- NetworkX for graph construction and analysis
- sentence-transformers for semantic embeddings
- Custom RAG system with entity-aware chunking
- SQLite for persistence (projects, chat history, hypotheses)
Frontend (TypeScript):
- React 18 + Vite for blazing-fast development
- react-force-graph for 2D/3D WebGL visualization
- Three.js for advanced 3D rendering with particles and curved edges
- Tailwind CSS + Lucide icons for modern UI
- Axios for API communication
AI Integration:
- Claude 3.5 Sonnet for natural language processing
- Custom prompt engineering for hypothesis generation
- RAG architecture combining semantic search with graph context
External APIs:
- PubMed E-utilities for paper search
- Google Scholar scraping for PDF discovery
- PMC and DOI resolution for full-text access
Challenges we ran into
1. Graph Performance: Visualizing 500+ nodes with real-time physics simulation tanked performance. We optimized by implementing WebGL rendering, reducing particle counts, and adding smart chunking for large graphs.
2. RAG Context Windows: Initially, RAG retrieved too much context, hitting Claude's token limits. We implemented entity-aware chunking that prioritizes relevant sections and semantic ranking to surface the best 7 chunks.
3. Real-time Progress Updates: Background jobs ran asynchronously, making it hard to show live progress. We implemented a polling system with granular status updates and persistent job tracking.
4. OAuth Token Expiration: During long research sessions (10+ minutes), Google OAuth tokens would expire mid-process, crashing the workflow. We implemented optional authentication for status endpoints and graceful error handling.
Accomplishments that we're proud of
✅ End-to-end autonomous research pipeline - From query to knowledge graph in minutes, fully automated
Production-quality RAG system - Semantic search + entity-aware retrieval with precise citations (paper + page)
Stunning visualizations - 3D graphs with colored edges, animated particles, proper lighting, and smooth interactions rival commercial tools
Full persistence layer - Chat history and hypotheses survive across sessions, making research continuity seamless
Citation transparency - Every AI-generated answer links back to exact source documents and pages
Graph-aware hypothesis generation - Discovery Lab analyzes both document content AND network structure to find insights humans might miss
Real-time updates - Live progress tracking during agentic research (papers found, analyzed, entities extracted)
Clean architecture - Modular, typed codebase with clear separation between services, ready for scale
What we learned
Technical:
- scispaCy's biomedical NER capabilities are incredible but require careful prompt engineering to maximize extraction quality
- WebGL force-directed graphs need careful optimization—curved edges, particles, and lighting all impact frame rates
- RAG isn't just "throw everything at the LLM"—entity-aware chunking and semantic ranking dramatically improve answer quality
- Background job management in FastAPI requires thoughtful state management and polling strategies
- Three.js lighting models make a huge difference in 3D visualization readability
Research Domain:
- Biomedical research has VERY specific entity types (genes, proteins, diseases, drugs, pathways)
- PubMed's API is powerful but Google Scholar often has better PDF availability
- Relationship extraction is hard—co-occurrence is a decent baseline but pattern matching catches many more connections
- Researchers care deeply about citations and provenance—"trust but verify" is critical
Product:
- Visual feedback is everything—users want to SEE progress, not just wait
- Persistence matters more than we thought—researchers return to projects over days/weeks
- The "magic moment" is when Discovery Lab surfaces a hypothesis the user hadn't considered
- Autonomous workflows need to show their work—users want to understand what the AI did
What's next for Empirica
Expand Research Domains:
- Multi-domain NER models - Integrate specialized models for chemistry, physics, computer science, and social sciences beyond biomedicine
- Domain-adaptive entity extraction - Let users choose research domain (clinical, genomics, drug discovery) for optimized NER performance
- Custom entity training - Allow researchers to fine-tune models on their specific subdomain
Enhanced Collaboration:
- Real-time multi-user editing - Multiple researchers annotating and discussing the same graph simultaneously via WebSockets
- Export to academic formats - BibTeX, RIS, EndNote, and auto-generated literature review sections with proper citations
- Author network analysis - Visualize collaboration patterns and identify key researchers in your field
Smarter AI:
- Fine-tuned biomedical LLM - Train domain-specific model for better entity extraction and more accurate hypothesis generation
- Literature review generator - Auto-compose structured academic review sections from your knowledge graphs
- Experiment suggestions - Recommend methodologies and protocols based on successful papers in your graph
Scale & Performance:
- PostgreSQL migration - Handle concurrent access and larger datasets efficiently
- Graph versioning - Track how your knowledge evolves over time with diff visualization
- Handle 10,000+ paper graphs - Streaming processing and smart pagination for massive research projects
Our vision: Make AI-accelerated research accessible to every scientist, turning months of literature review into hours of insight discovery.
Built With
- amazon-web-services
- axios
- claude
- fastapi
- networkx
- pymupdf
- python
- rag
- react
- scispacy
- sentence-transformers
- sqlalchemy
- sqlite
- typescript






Log in or sign up for Devpost to join the conversation.