-
-
2
-
1
Inspiration
We live in a world of video calls and remote pitches. Yet, the number one reason communication fails isn't what we say—it's how we say it. Psychological research suggests that up to 93% of communication is non-verbal. We noticed that many people (including ourselves) struggle with "Sentiment Congruency"—the alignment between facial expression and spoken words. Have you ever smiled nervously while delivering bad news? Or looked terrified while pitching an "exciting" startup idea? These mixed signals confuse audiences and kill credibility. We wanted to build a tool that acts as a non-judgmental, real-time mirror—not just showing you your reflection, but analyzing the impact of your delivery instantly.
What it does
Empathy Mirror is an AI-powered communication coach that runs entirely in your browser. It provides a real-time "Head-Up Display" (HUD) for your social interactions.
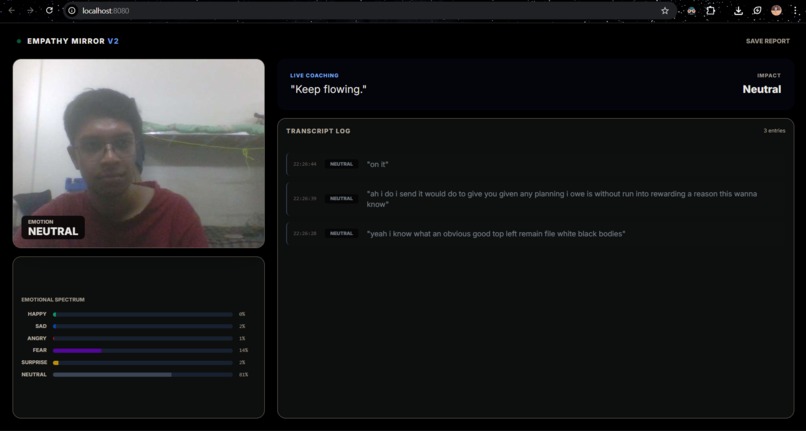
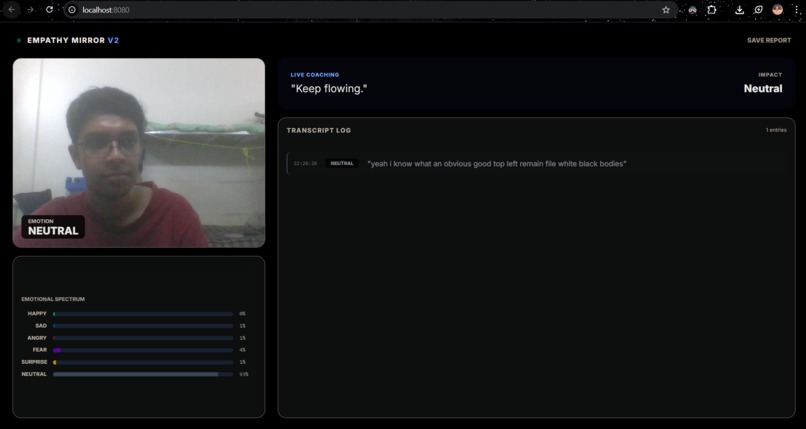
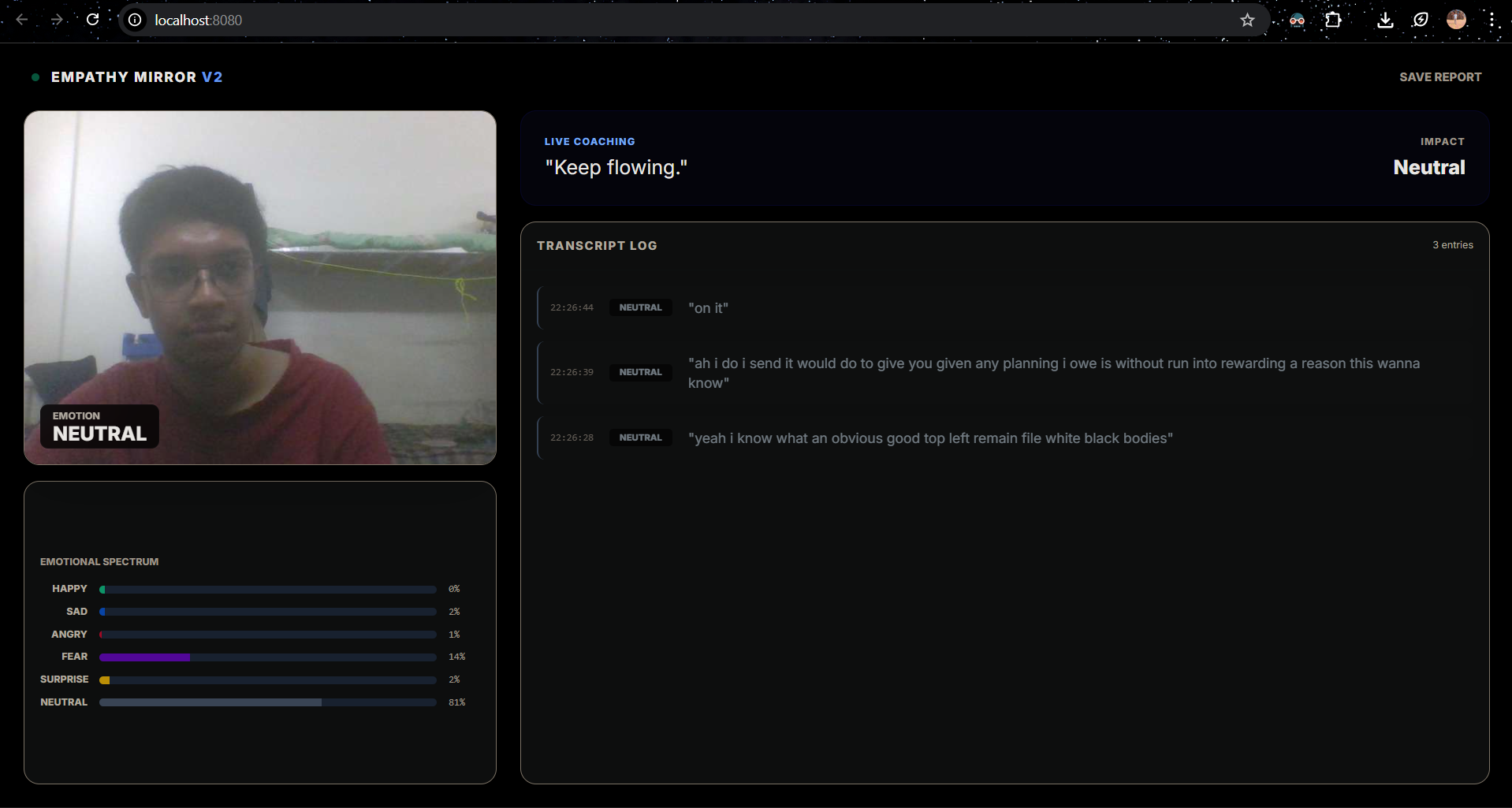
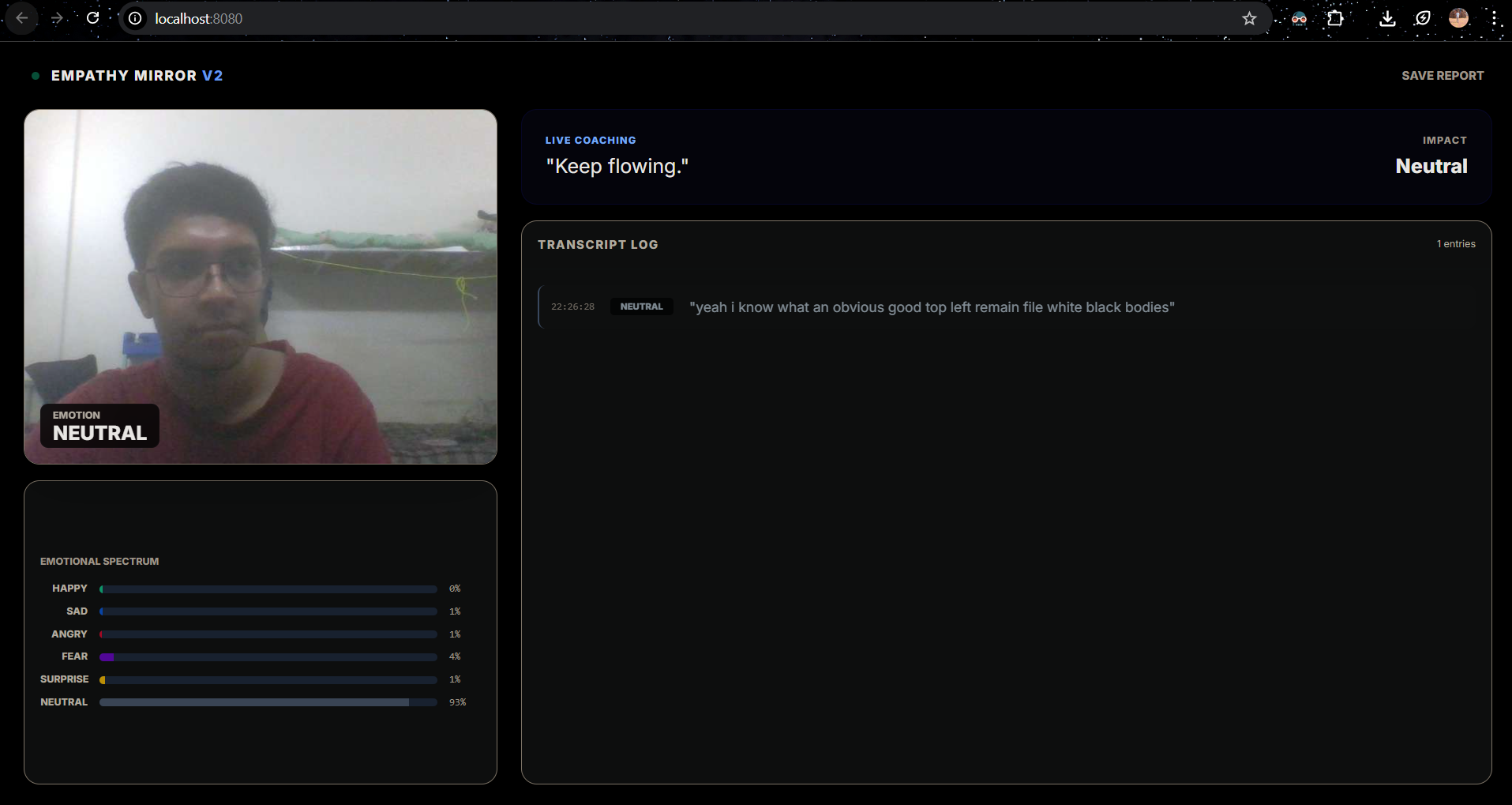
Visual Emotion Tracking: Uses computer vision to detect 7 distinct facial emotions (Happy, Sad, Neutral, Surprise, etc.) in real-time.
Live Transcription & Sentiment: Listens to your speech continuously and analyzes the emotional polarity of your words.
Congruency Engine: This is the core magic. It compares your visual state with your verbal sentiment.
High Resonance: When your face and words match (e.g., Happy Face + Positive Words).
Mixed Signals: When there is a disconnect (e.g., Fearful Face + Positive Words).
Masking: When you try to hide negative words with a smile.
Session Reports: At the end of a practice session, users can download a full transcript log with timestamped emotion tags to review their performance.
How we built it
We built Empathy Mirror as a high-performance Full-Stack Web Application.
The Backend (Python & Flask): We used Flask to serve the application. Crucially, we implemented Multithreading to handle two heavy data streams simultaneously:
video_loop(): Captures frames using OpenCV and analyzes them with DeepFace. We optimized this to run inference every ~300ms to maintain high FPS.
audio_loop(): Uses Vosk (an offline speech recognition engine) for zero-latency, privacy-focused transcription. We pair this with TextBlob for instant natural language sentiment analysis.
The Frontend (HTML5 & TailwindCSS): We designed a "Cyberpunk/Medical" interface using TailwindCSS. We avoided heavy charting libraries and built custom CSS-based Spectrum Bars that animate smoothly using DOM manipulation, ensuring the UI never lags behind the data.
Data Handling: We implemented a custom NumpyJSONProvider in Flask to handle complex data types (like float32 emotion scores) that standard JSON serializers usually crash on.
Challenges we ran into
The "Float32" Crash: One of our biggest headaches was a recurring TypeError: Object of type float32 is not JSON serializable. It turned out the DeepFace library returns NumPy types, which Flask's default JSON serializer can't handle. We had to write a custom serializer class to intercept and convert these values globally.
Audio Latency vs. Video FPS: Initially, the video feed would freeze whenever the AI was listening for audio. We solved this by decoupling the audio and video engines into separate daemon threads and using a shared mirror_state dictionary for state management.
Real-Time "Flow": Traditional speech APIs wait for silence to process text. This felt clunky. We switched to Vosk to capture partial results, allowing the transcript to appear as the user speaks, creating a true "streaming" experience.
Accomplishments that we're proud of
Offline Capability: By switching to Vosk, we removed the dependency on Google's API, meaning the app works offline and has zero network latency.
The UI/UX: We managed to fit a live video feed, real-time coaching, 7 distinct emotion bars, and a scrolling transcript into a clean, single-screen dashboard.
Robustness: The system handles noise, silence, and camera interruptions gracefully without crashing the server.
What we learned
Multimodal AI Fusion: Combining Computer Vision and NLP is powerful but requires careful synchronization. A mismatch of even 500ms allows the user to see a "lag," breaking the illusion of a smart mirror.
Thread Safety: Managing shared state between three independent loops (Audio, Video, Server) taught us valuable lessons in Python concurrency.
What's next for Empathy Mirror
Eye Contact Tracking: Using gaze detection to warn users if they are reading from a script too much.
Tone Analysis: Integrating librosa to detect vocal pitch and volume (e.g., detecting "uptalk" or monotone delivery).
VR Integration: Bringing this HUD into a VR headset for immersive public speaking practice in virtual auditoriums.


Log in or sign up for Devpost to join the conversation.