

Inspiration
85% of employees experience workplace conflict, yet every coaching tool today helps only after the conversation is over - when the damage is already done. I asked: what if AI could coach you during the moment tension rises? Not a chatbot you type into, but an invisible mentor whispering in your ear, reading your body language, and grounding its advice in real conflict resolution research - all in real time.
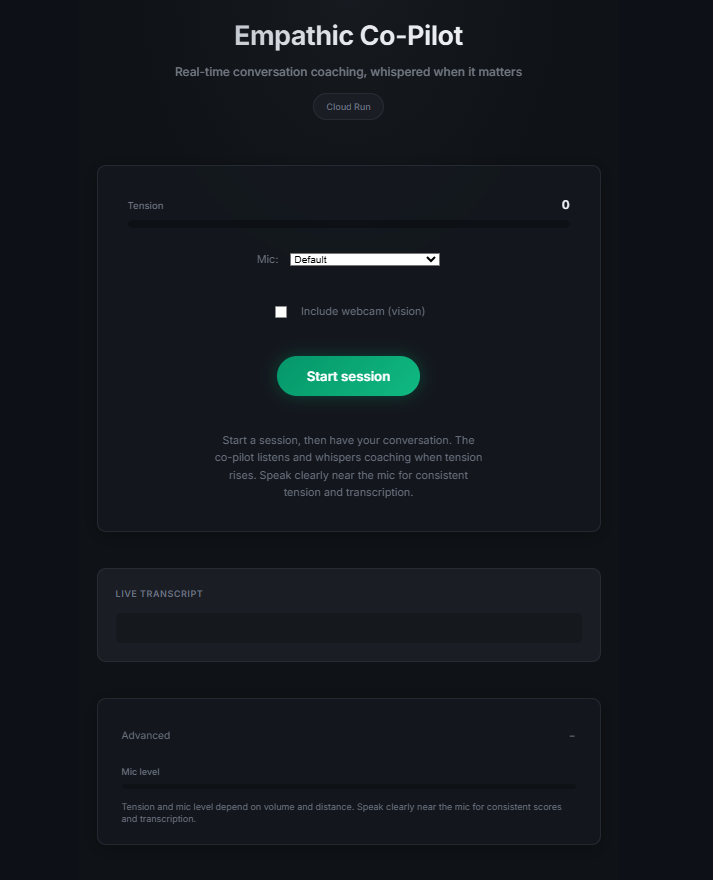
What it does
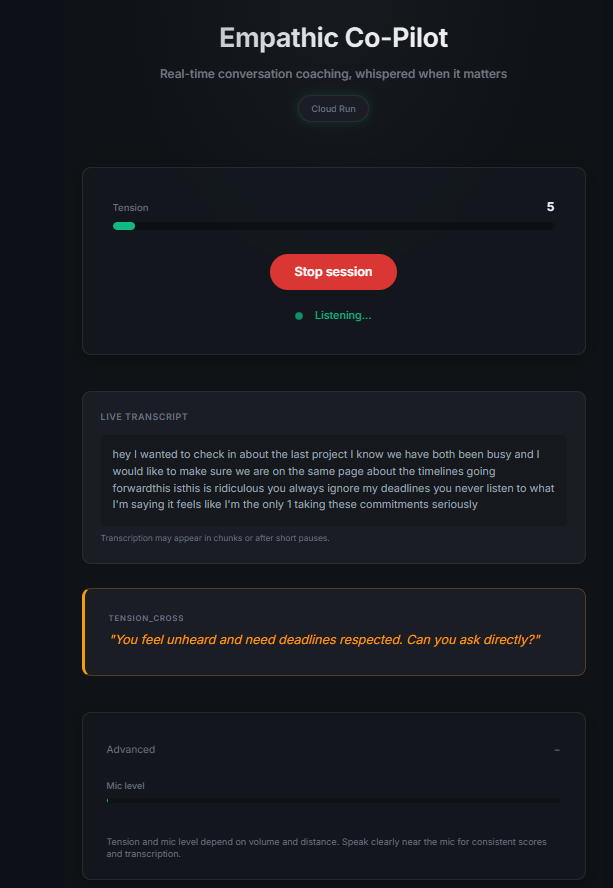
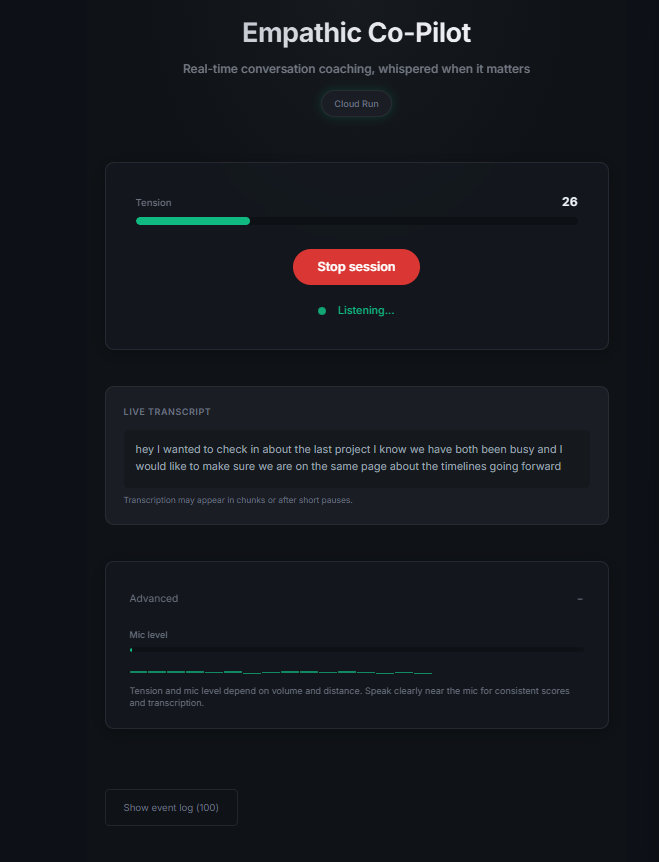
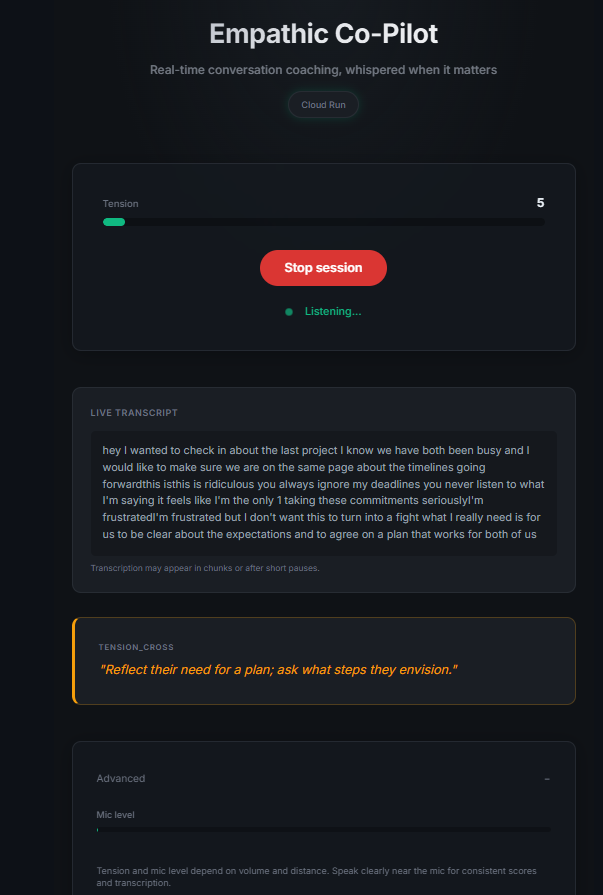
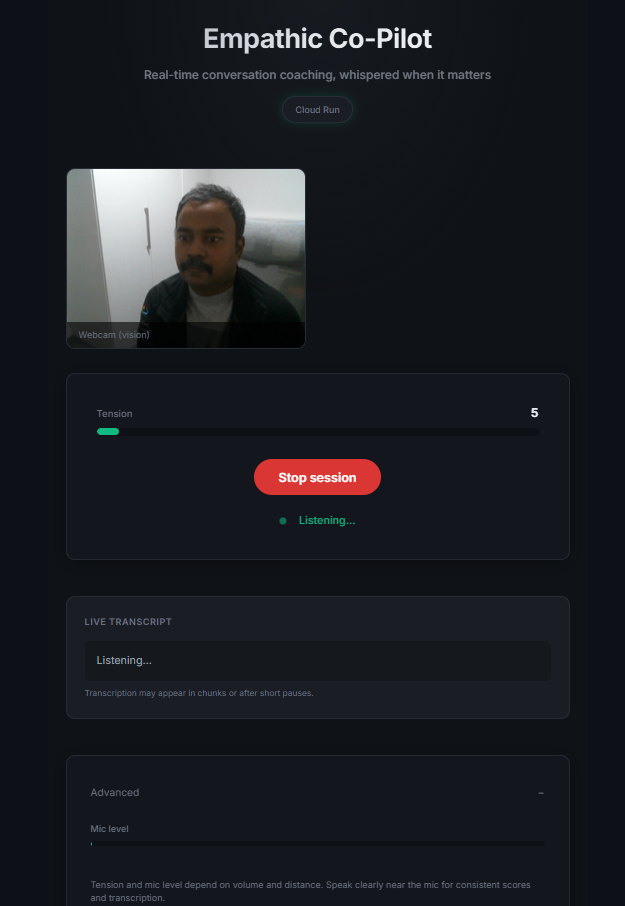
Empathic Co-Pilot is a real-time conversation coaching agent. It listens to your conversation through the microphone, detects rising tension through four signals (volume spikes, silence patterns, interruption frequency, and semantic escalation markers like "you always" or "you never"), and when tension crosses a threshold, "Sage" - your AI coaching persona - whispers calm, 8-12 word NVC-grounded guidance through your speakers. It also provides subtle empathetic backchannels ("Ok.", "I see.") so you feel heard while speaking. Optionally, it reads your body language via webcam - detecting clenched jaws, crossed arms, or pointing - and references these specifically in coaching ("Your jaw is tight - soften it").
How I built it
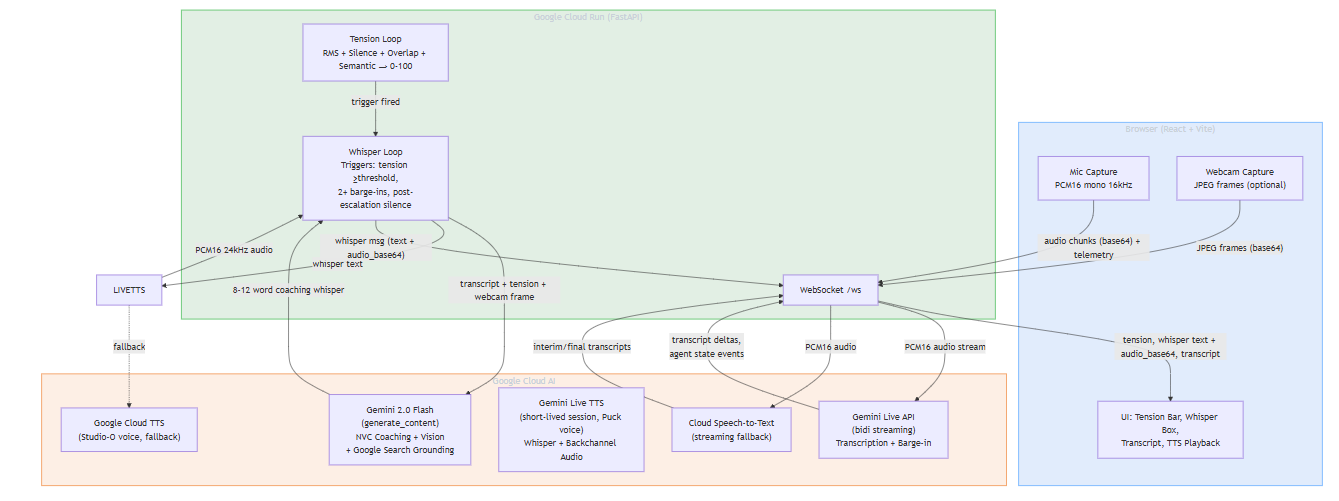
- Gemini Live API (Vertex AI) for real-time bidirectional audio streaming — handles transcription, barge-in detection, and is also used as a TTS engine for natural whisper audio (Puck voice)
- Gemini 2.0 Flash for generating contextual coaching whispers with optional webcam vision input and Google Search grounding for evidence-based NVC guidance
- Google Cloud Run hosts the FastAPI backend with WebSocket support
- Cloud Speech-to-Text provides streaming fallback transcription
- Google Cloud TTS (Studio-O voice) serves as fallback audio synthesis
- React/Vite frontend with Web Audio API for whisper playback
- google-genai SDK for all Gemini API interactions
The architecture uses a dual-loop design: a tension scoring loop (500ms cycle analyzing RMS, silence, overlap, and semantic markers) and a whisper loop (deterministic triggers with cooldown). When a trigger fires, coaching text is generated by Flash, then spoken by a short-lived Gemini Live session for natural human-like audio.
Challenges I ran into
- Gemini Live session instability: The native-audio model generates audio responses despite "stay silent" instructions, causing 5-9 session drops per conversation. I built auto-reconnect (up to 20 retries) and fully suppressed model backchannel audio, replacing it with our own TTS-generated backchannels.
- SSML compatibility: Studio-O voices don't support
pitchin SSML prosody tags — discovered through production 400 errors. Had to separate pitch control between SSML (rate, volume only) and AudioConfig. - Async iteration patterns:
asyncio.wait_for()can't wrapasync foriterators - required manual deadline-based timeout for Gemini Live TTS audio collection. - Whisper audio quality: Went through multiple iterations - synthetic breath noise sounded like static, browser Web Speech API sounded robotic alongside Gemini Live TTS. Final solution: Gemini Live TTS only, with gentle post-processing (low-pass smoothing + amplitude reduction).
Accomplishments that I'm proud of
- Natural whisper audio: Using Gemini Live API as a TTS engine (opening short-lived sessions to speak coaching text) produces remarkably human-like whisper audio - the single biggest differentiator from robotic synthesis.
- Consistent voice persona: Both coaching whispers and empathetic backchannels use the same Gemini Live Puck voice, creating a unified "Sage" persona experience.
- Vision-aware body language coaching: Specific references to observable cues ("Your jaw is tight — soften it") rather than generic "you look tense."
- Evidence-grounded coaching: Google Search grounding means whispers reference real NVC and conflict resolution techniques, not hallucinated advice.
- Real-time performance: Coaching whispers fire within ~3 seconds of a trigger - fast enough to intervene before a conversation escalates further.
What I learned
- Gemini Live's native-audio model is powerful but unpredictable - designing for graceful degradation (auto-reconnect, fallback chains) is essential for production use.
- Using Gemini Live as a TTS engine (beyond its intended transcription use) unlocks natural speech quality that dedicated TTS services can't match for conversational coaching.
- Real-time tension detection works best with multiple signals combined - no single signal (volume, silence, overlap, or language) is reliable alone, but together they produce accurate escalation detection.
- Post-processing audio (smoothing + amplitude reduction) is more effective than SSML prosody for creating a whisper effect.
What's next for Empathic Co-Pilot
- Multi-party detection: Distinguish between speakers to provide role-specific coaching
- Longitudinal learning: Track conversation patterns across sessions to personalize coaching
- Mobile companion: Earpiece-based coaching for in-person conversations
- Enterprise integration: Connect with meeting platforms (Zoom, Meet) for professional coaching at scale
- Expanded modalities: Screen-sharing context for remote work conflicts about shared documents/code
Built With
- cloud-build
- fastapi
- gemini-2.0-flash
- gemini-live-api
- google-cloud-run
- google-cloud-speech-to-text
- google-cloud-text-to-speech
- google-genai-sdk-(google-genai)
- python
- react
- vertex-ai
- vite
- web-audio-api
- websockets

Log in or sign up for Devpost to join the conversation.