
Inspiration
We were inspired by yesterday’s keynote on storytelling, particularly the idea that influence begins with stories. Great stories are not just about words, but about emotion, expression, and shared feeling. This made us reflect on how much of communication is visual, and how many people are unintentionally excluded from that layer of meaning. This led us to ask how we might make emotional expression more accessible, especially for blind and neurodivergent users who may struggle with reading facial cues.
What it does
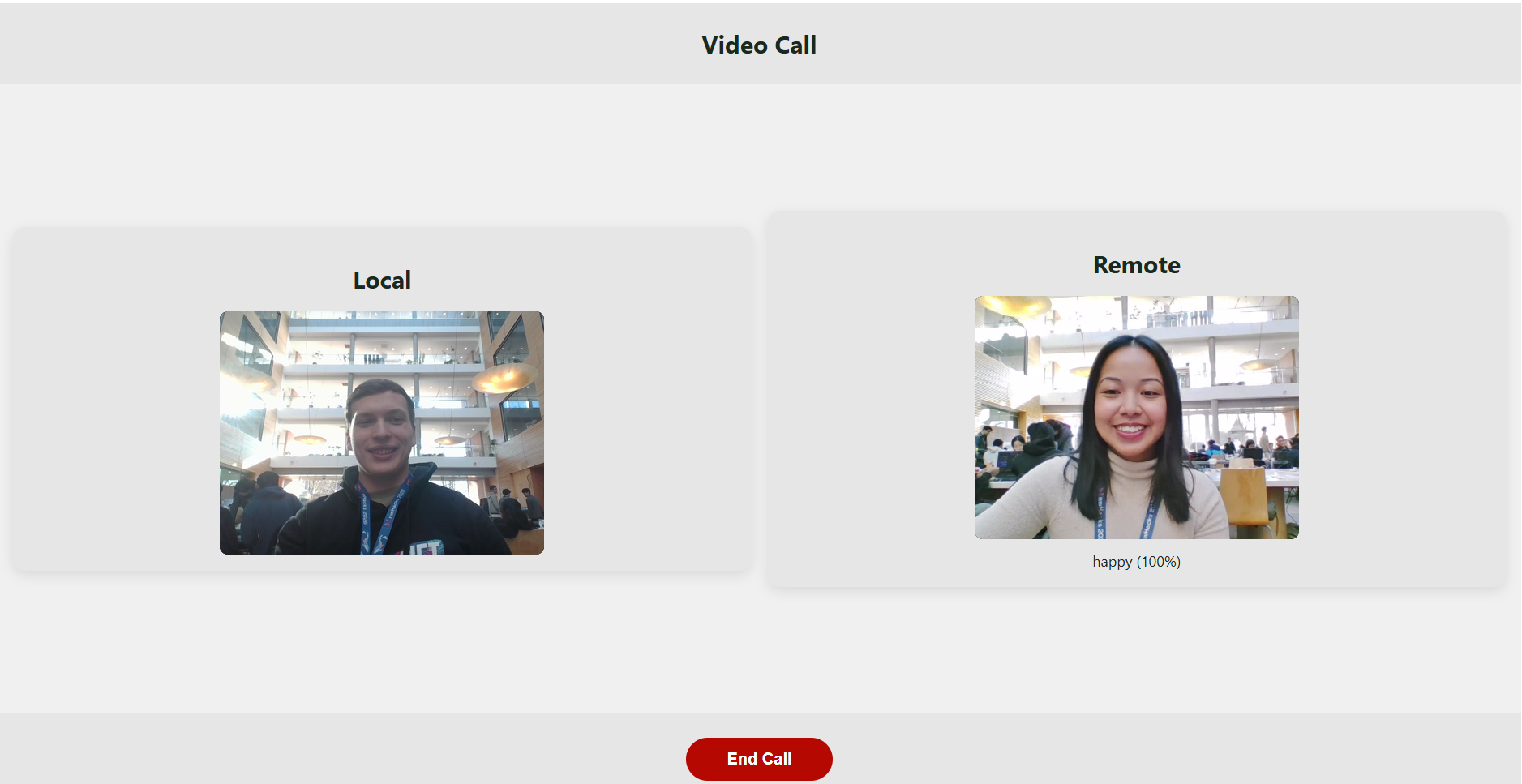
EmotiSound is an accessibility-first video tool that translates basic facial expression cues into non-verbal sensory feedback using sound. Instead of relying on sight to interpret emotions, users can sense emotional context through a consistent, learnable audio language. The system detects one face at a time and classifies four expressions: happy, neutral, sad, and angry, mapping each to a distinct tone and visual signal.
How we built it
We built the frontend using React to create an accessible and responsive user interface, including a live video preview. For facial expression detection, we integrated face-api.js, which processes video frames in real time within the browser. Our backend was developed with Node.js and Express to handle authentication and sessions. We also incorporated WebRTC for camera access and designed a clear separation between detection, feedback, and data handling. Throughout development, we prioritized local processing and minimal data storage to respect user privacy.
Challenges we ran into
A challenge we ran into was integrating the face-api into the browser and displaying the emotions, as well as setting up webRTC for peer to peer video connections because our team has never used or encountered webRTC and it was a very big learning curve with the time constraints we had.
Accomplishments that we're proud of
We’re proud of creating a functional end-to-end system that meaningfully integrates computer vision, web technologies, and accessibility design. We successfully implemented real-time facial expression detection with clear, interpretable sensory feedback. We also built a clean, usable interface that centers user control and privacy. Most importantly, we’re proud of developing a concept that thoughtfully addresses an overlooked accessibility gap and encourages more inclusive communication.
What we learned
We learned that building for accessibility is as much about empathy and communication as it is about technology. Collaborating as a team required clear dialogue, patience, and openness to different perspectives. Technically, we gained experience with real-time video processing, WebRTC, and full-stack application architecture but just as importantly, we strengthened our teamwork, problem-solving, and design thinking skills.
What's next for Emotisound
Looking ahead, we want to expand EmotiSound beyond facial expressions by incorporating real-time sign language interpretation with automatic captioning, making conversations even more accessible for Deaf and hard-of-hearing users. We also plan to introduce private rooms where users can securely connect with friends, family, or colleagues using EmotiSound features in a controlled space. Longer term, we hope to refine our emotion-to-sound mappings through user feedback.
Built With
- face-api
- javascript
- netlify
- react
- render
- sqlite
- tech-domain
- typescript
- webrtc
- websocket




Log in or sign up for Devpost to join the conversation.