-
-
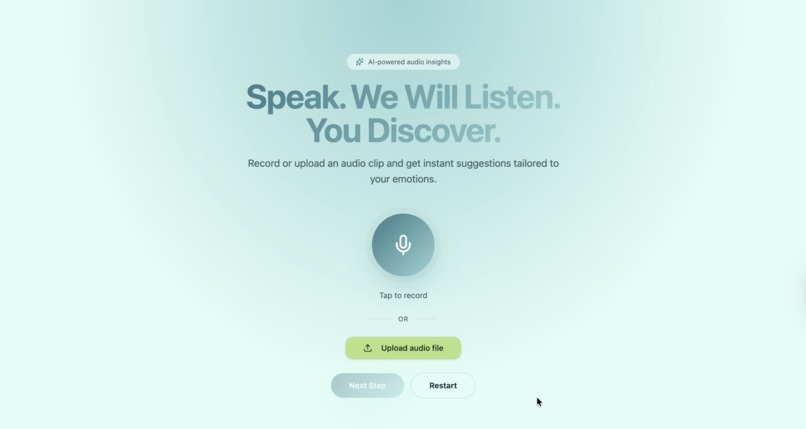
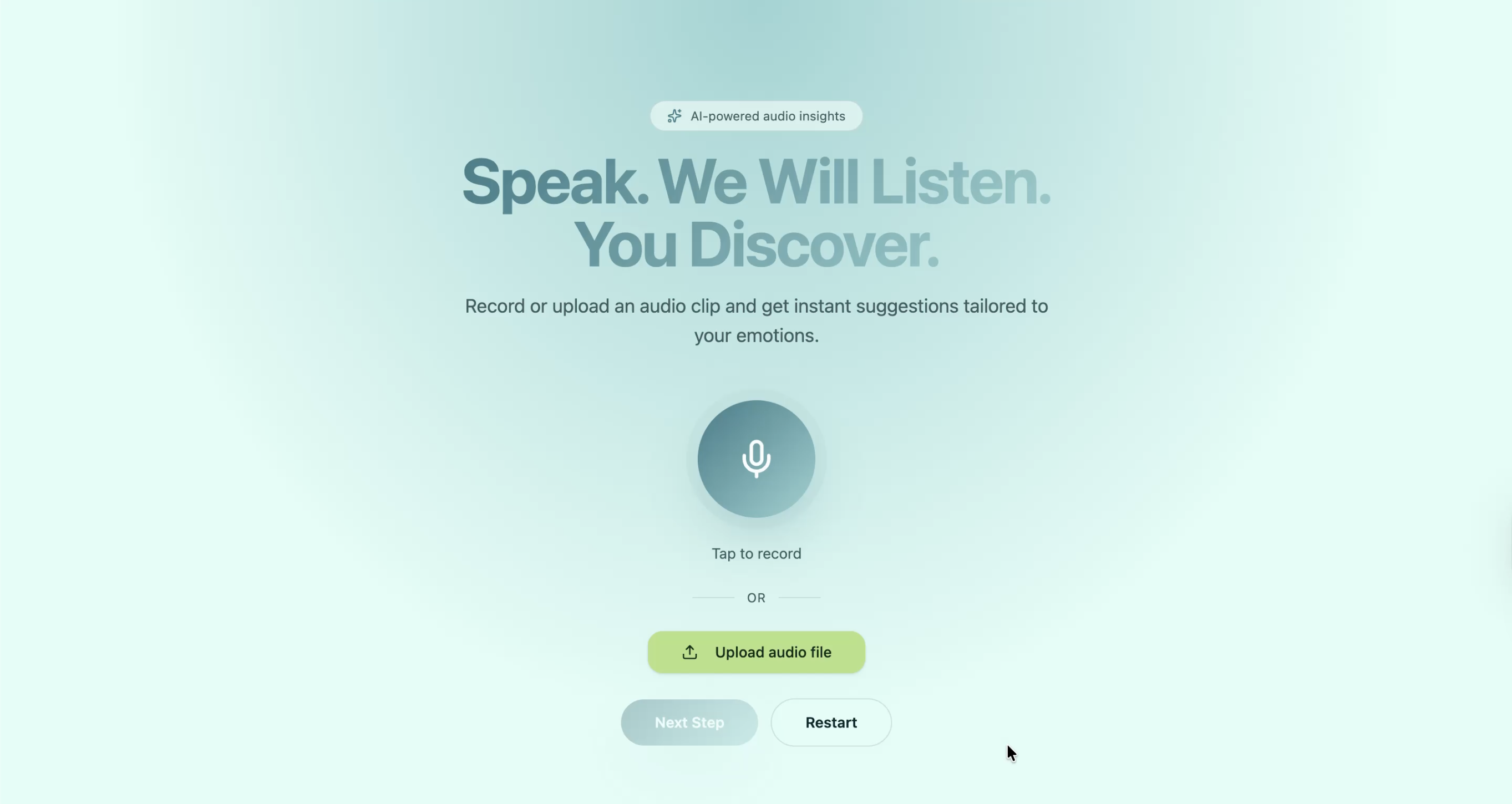
Home Page
-
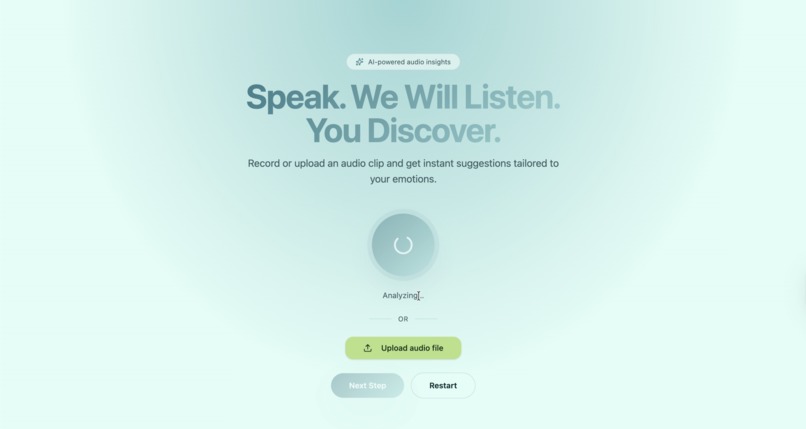
Cpatured the Audio Directly (Audio can also be uploaded)
-
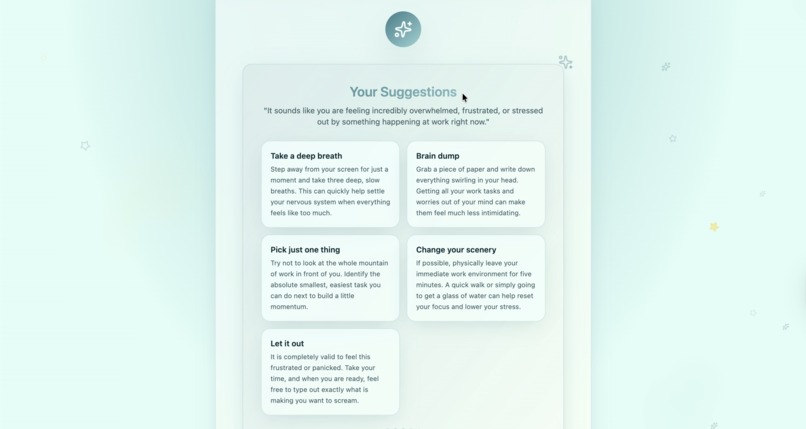
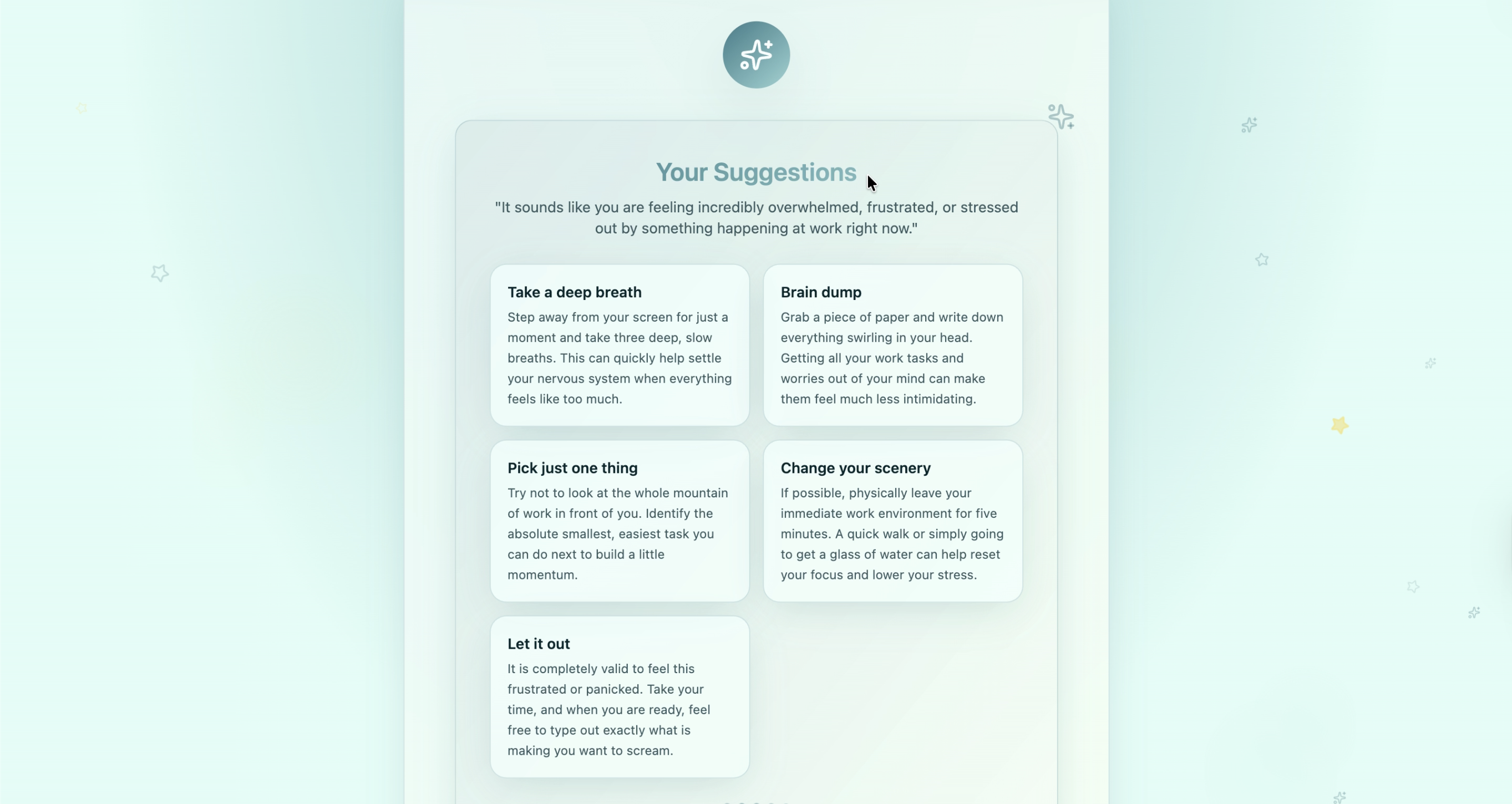
Suggestions according to the voice tone, and uploaded situation
-
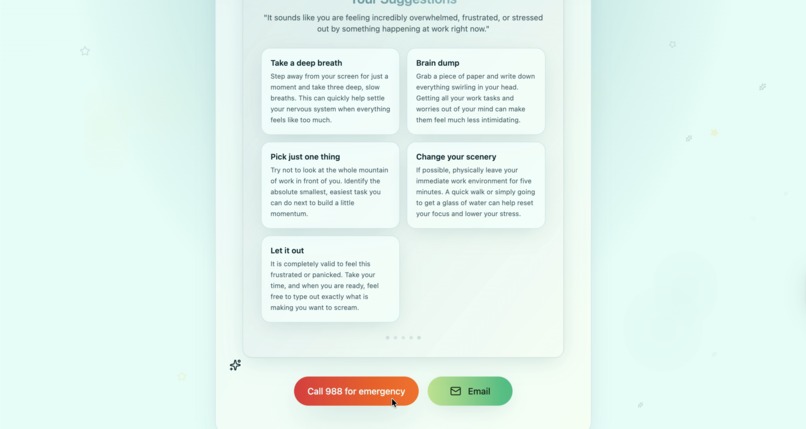
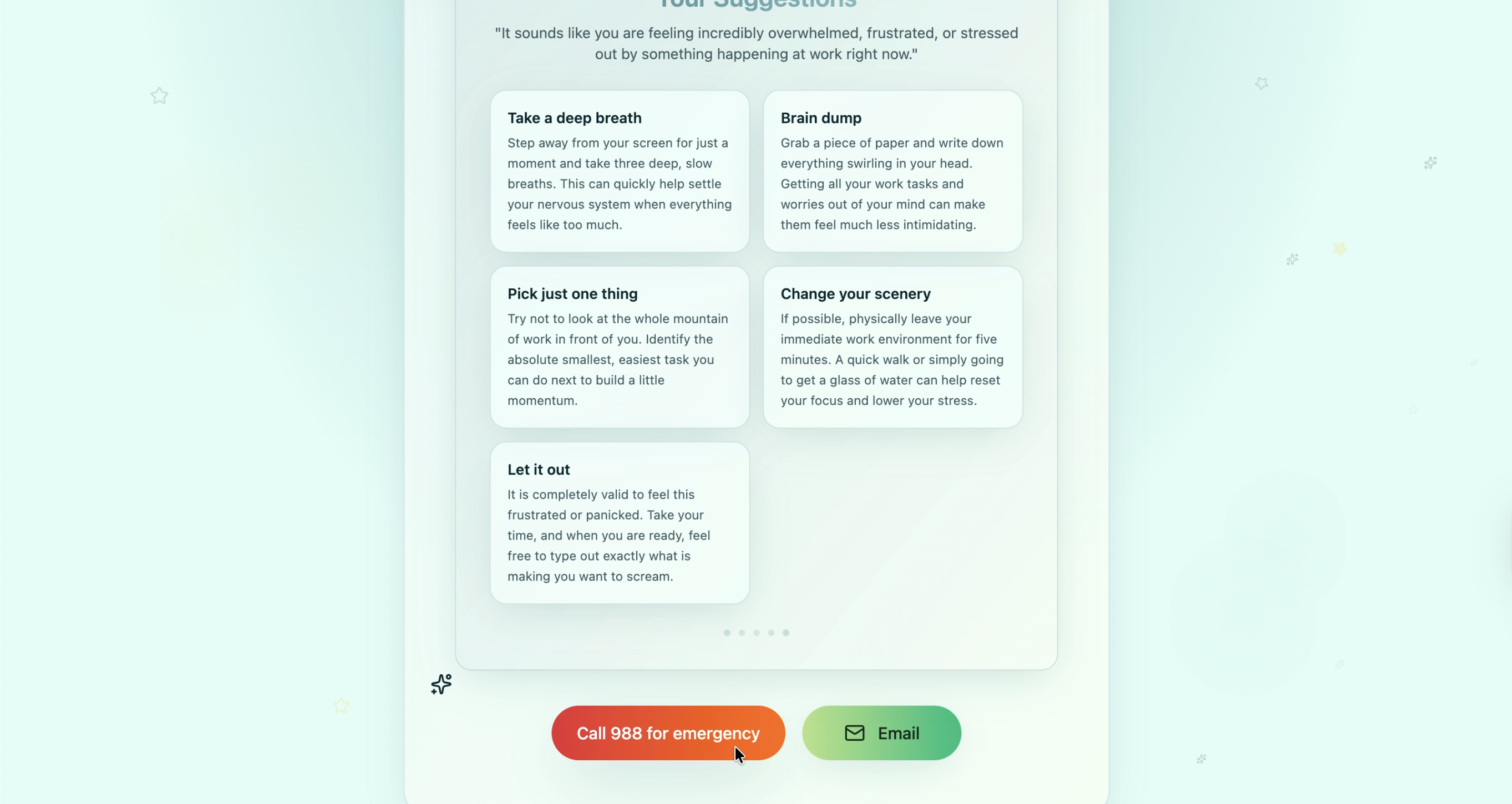
Emergency number for mental health is added, and will be able to to email the suggestions
Inspiration
As students who are currently in the middle of midterms, hackathons, extracurriculars, and major assignments that are due, we identified mental health as a core issue and battle for all university students. However, we soon realized that this is a widely faced issue by people of all ages, and with everything that is going on in the world, it can be very overwhelming to face everyday tasks.
One downside that we identified in most mental health applications is that the user often has to type their feelings or select how they feel from dropdown menus. When someone is so overwhelmed or burnt out, it is hard to find the energy to type out their feelings. Instead, talking or ranting about their situation may be more effortless and can also help the person unload their emotions.
What it does
We built SoulVoice as an app that people can rely on when they need to talk through a situation. SoulVoice allows users to rant about any topic and prioritizes mental health, providing calming and reassuring advice.
How we built it
At SoulVoice’s core, we have built a Machine Learning model that is trained using 3 separate audio datasets - CREMA-D, RAVDES, TESS. We are preprocessing the data with 4 main methods:
Uniform Resampling (16,000Hz): converts all audio files by removing very high-frequency detail above what 16 kHz can represent
Why: To prepare the data for a Convolutional Neural Network, which requires every input to be the exact same size.
Peak Normalization: divides the entire audio waveform by its maximum volume peak, normalizing the loudest point in every file
Why: ignore raw loudness and instead learn the actual acoustic textures and pitch variations (prevent CNN from cheating
Silence Trimming (Voice Activity Detection): chops off the dead silence at the beginning and end of the audio clip
Why: To clean up unnecessary silence, which doesn’t contribute at all to the ML model’s results.
Fixed-Length Padding & Truncating: tune the length of each audio clip to exactly 3 seconds by clipping them or extending them
Why: enables it to be converted to a Mel Spectrogram
After preprocessing, we convert our data into a Mel Spectrogram, turning the audio into a visual style grid. This makes it easier for our Convolutional Neural Network (CNN) to process the data and to train our model. Then, we split our data into an 80% training and 20% validation split. Finally, CNN learns which patterns are associated with emotions.
Lastly, the model outputs a predicted emotion based on the user’s input. This emotion, along with topics that the user can choose (ex. family, school, work, etc.) are fed into Gemini API. Then, Gemini API takes all of this as information and outputs sympathetic and helpful advice that prioritizes the student’s wellbeing.
Challenges we ran into
Creating the model and debugging it was the most challenging part because it took so long for our model to run, making it a necessity to have good GPU stats. It was hard to train the model especially because of our hardware constraints and this made it even harder to debug any issues. Furthermore, our original dataset was 25GB, but we we're only able to train on 500MB of data because of the training runtime. To try and get around this issue, we switched between Google Collab and local training to test different training methods and train our ML model faster, but we still had to hugely restrict the size of our dataset. As a result of a combination of these challenges, our model does Overfit to the data.
But in the future, with a better infrastructure to train the model on even more diverse data, would hugely improve it's performance.
Accomplishments that we're proud of
We're proud of tackling such a daunting project and actually building and training our own ML model. Furthermore, working with the audio files and weaving in each of the separate components of our project (ML Model, Frontend, and Gemini API) to make an application that works and gives the user advice.
What we learned
We're proud of tackling such a daunting project and actually building and training our own ML model. Furthermore, working with the audio files and weaving in each of the separate components of our project (ML Model, Frontend, and Gemini API) to make an application that works and gives the user advice.
What's next for SoulVoice
- Doing training on datasets that include longer audio inputs to improve responses when students need to rant for a longer period of time
- Possible New Feature: Identifying key words in speech and feed those words as more information for the API to gather all data and generate a response. This would provide a more tailored and personalized response.
- Incorporating a way for users to look back on chat history and a calendar view color coded based on user’s emotions
Another further application of our model could be related to Voice AI. Voice AI models are often created with a linguistics point of view, trying to emulate human speech through emotion, pauses and tone. Our model is trained to identify a user’s emotion by their speech and has a lot of potential to be expanded and applied in coordination with these Voice AI models. For example, SoulVoice could be used in coordination with these voice AI models to improve accessibility of AI products. People who are visually impaired or who have a mobility impairment may not be able to type out long prompts to an AI model and Voice AI models provide a solution to this by responding with audio. However, Voice AI is still restricted by non detecting true emotion behind the user's input speech. Our model could allow the user to talk to these Voice AI models, in turn detecting the true emotion behind the user’s response. Then, the Voice AI can respond with the user’s feelings in mind, matching the user’s energy.
As a result, the Voice AI response would provide Enthusiastic responses when the user is excited. When the user is feeling down, the model would instead switch to a sympathetic mode, avoiding enthusiastic responses.
Overall, our ML model behind this application could be even applied to various other AI applications, especially voice AI, and enhancing AI’s responses.
Built With
- figma
- gemini-api
- javascript
- python
- pytorch
- react
- sklearn
 Thant")
Log in or sign up for Devpost to join the conversation.