-
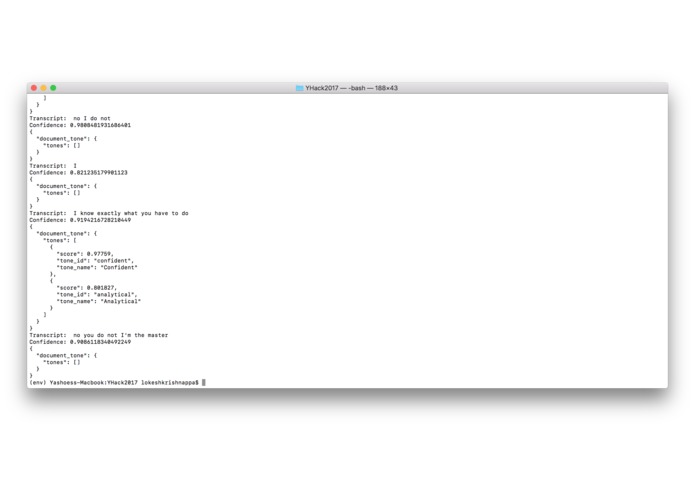
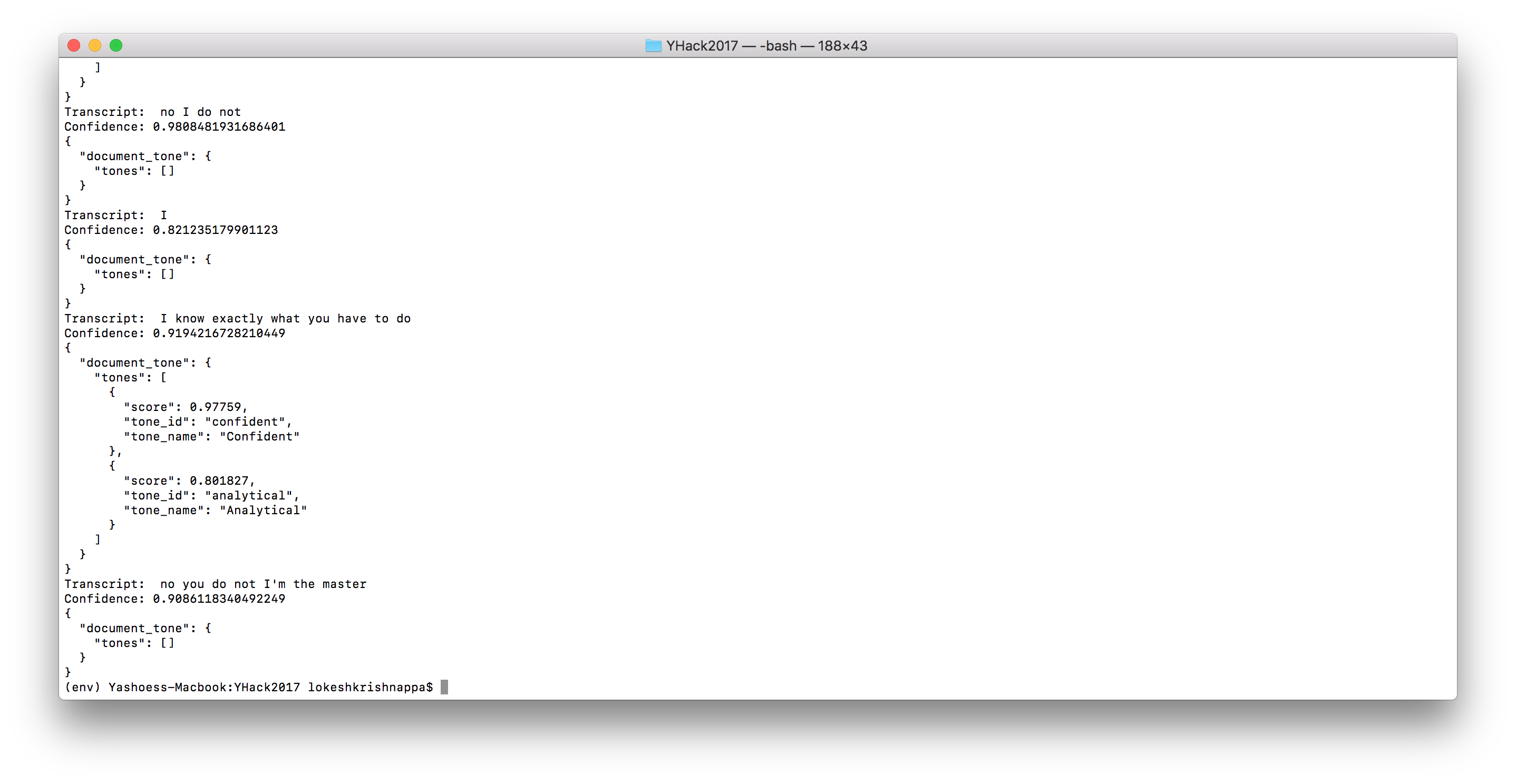
The command line prompt with the transcript and the outputs.
Inspiration
I got the inspiration from the Mirum challenge, which was to be able to recognize emotion in speech and text.
What it does
It records speech from people for a set time, separating individual transcripts based on small pauses in between each person talking. It then transcribes this to a JSON string using the Google Speech API and passes this string into the IBM Watson Tone Analyzer API to analyze the emotion in each snippet.
How I built it
I had to connect to the Google Cloud SDK and Watson Developer Cloud first, and learn some python that was necessary to get them working. I then wrote one script file, recording audio with pyaudio and using the APIs for the other two to get JSON data back.
Challenges I ran into
I had trouble making a GUI, so I abandoned trying to make it. I didn't have enough practice with making GUIs in Python before this hackathon, and the use of the APIs were time-consuming already. Another challenge I ran into was getting the google-cloud-sdk to work on my laptop, as it seemed that there were conflicting files or missing files at times.
Accomplishments that I'm proud of
I'm proud that I got the google-cloud-sdk set up and got the Speech API to work, as well as get an API which I had never heard of to work, the IBM Watson one.
What I learned
To keep trying to get control of APIs, but ask for help from others who might've set theirs up already. I also learned to manage my time more effectively. This is my second hackathon, and I got a lot more work done than I did last time.
What's next for Emotional Talks
I want to add a GUI that will make it easy for viewers to analyze their conversations, and perhaps also use some future Speech APIs to better process the speech part. This could potentially be sold to businesses for use in customer care calls.
Built With
- google-speech
- ibm-watson
- python

Log in or sign up for Devpost to join the conversation.