-

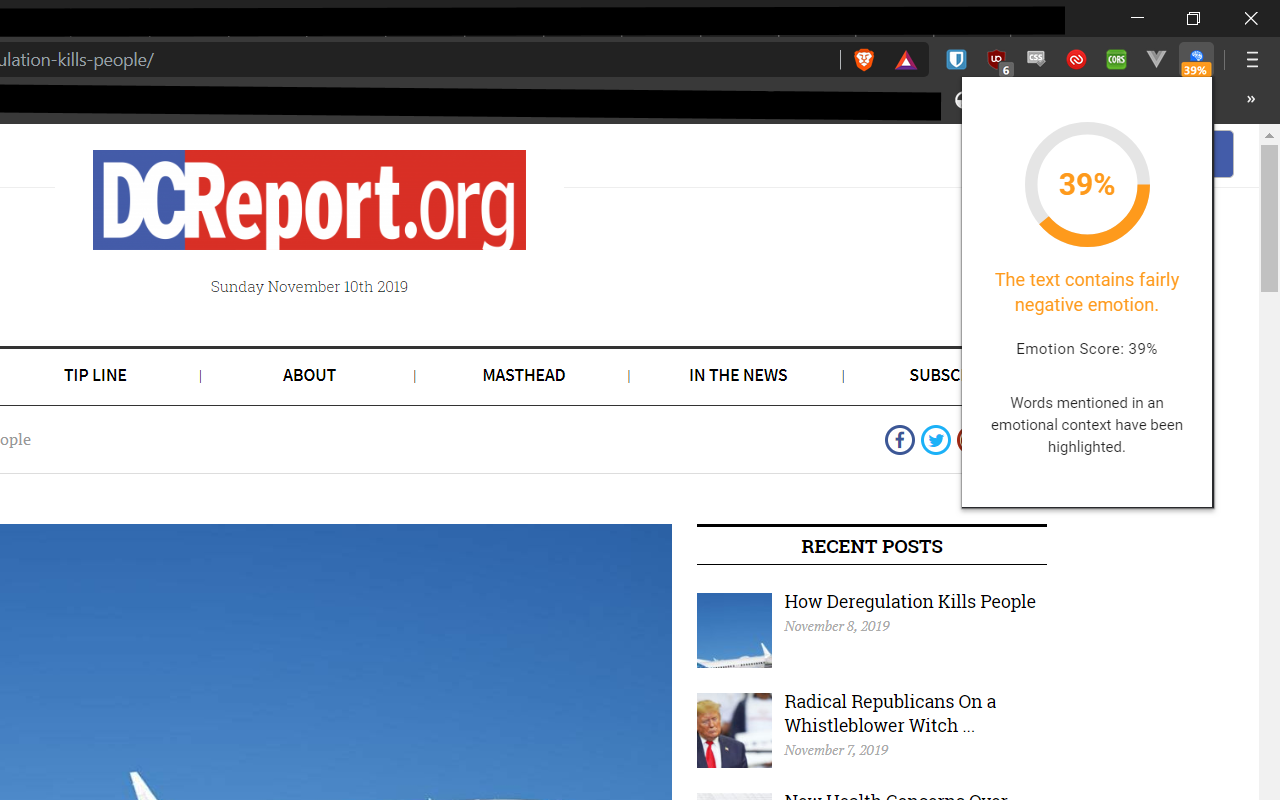
The extension rates the emotion of web pages from 0-100.
-

The extension highlights text that is used in emotional context.
-



Inspiration
Today's media is increasingly becoming opinionated, emotional, and unreliable, as opposed to being backed by facts, data, and sources. Although we may not realize it, our thoughts are often being manipulated by appeals to emotion, rather than logic or credibility. We wanted to build something that offers readers a way to step back and see how much of an article is based on emotion, rather than facts.
Installation
Installation instructions are in README.md. Our Chrome Web Store submission is under review.
What it does
Emotilyze is a browser extension, soon to be available on the Chrome Web Store. When activated, the extension scans the contents of any web page or article and displays a "Emotion Score,' a percentage indicating how much of the page is based on emotion, shows a description of the overall emotional content of the page, and highlights words in the page that are used in a strong emotional context.
How we built it
The extension was built using JavaScript, the Chrome extension API, and Vue.js/Vuetify.js for the popup's UI. The extension extracts the primary text from the web page and makes a request to our server using axios, which returns information about the emotional contents of the text.
Our server was written using Node.js and Express.js. We used the Google Cloud Natural Language API to analyze the text. Before sending the data back to the extension, the server analyzes the data from Google Cloud and computes an overall "Emotion Score" for the site, as well as descriptions for emotional content within the article. We are hosting the server using Google App Engine.
Challenges we ran into
Extracting Article Content
Our first challenge was figuring out how to distinguish the important text in web pages from headers, links, ads, and other irrelevant contents.
Our first approach to this problem was to have the user highlight the text that should be analyzed with their cursor, then activate the extension through an option in the right-click menu. This worked, but we decided it was too inconvenient. We wanted a way to extract the article's contents without the help of the user.
We then decided to try and find an open-source library that could parse the web page for us. We tried a number of libraries, including boilerpipe and article-parser, but they did not work properly on many websites. We then found html-article-extractor, which seemed to work perfectly on nearly any site. We could simply feed the library the HTML contents of the page and it would return the article's text, ready to be analyzed by Google Cloud.
Highlighting text within web pages
One of the key features of our extension is to highlight words on a page that are used in a heavily emotional context. At first, this seemed like some fairly simple HTML manipulation. However, we quickly ran into issues. Our logic was the following: loop through the relevant HTML elements on the page, and replace the emotional words with a <span> that highlights it. However, this logic led to infinite loops, since the <span> contained the text that needs to be replaced. This led to nested <span>s, causing hundreds of tooltips to pop up when the user hovers over the highlighted text.
We tried to fix this by starting each loop at the end of the span that was previously inserted. However, this did not work because text on a web page can be spread throughout hundreds of different HTML elements. With a bit of creativity and the help of Stack Overflow, we were able to solve this using a Map and regular expressions.
Calibrating Google's Sentiment Analysis
Google's Natural Language API returns data in a somewhat convoluted format. The most relevant data for us is score and magnitude. In essence, score is a value from -1 to 1 that represents the strength of the negativity or positivity in the text, while magnitude is a value from 0 to infinity that represents how much emotional content the text contains. This data would be too confusing to show to the user, so we needed to figure out how to turn these numbers into a more friendly format.
In our server code, we decided to compute three indicators that would be shown to the user. Our first indicator is the "emotion score," a percentage designed to represent how emotional the text is. The second indicator is a description summarizing the emotional content of the page. Lastly, we generate descriptions for each highlighted text explaining why it is highlighted.
While the code for generating these indicators is fairly trivial, figuring out how to interpret Google's values posed a challenge. Interpreting score was not too bad, since it is always between -1 and 1. However, magnitude can be anywhere from 0 to infinity, and depends on how long the text is. We struggled to figure out a formula that would give us an accurate "emotion score." We settled on magnitude / 0.35 * length, but this is subject to change as we are still not totally satisfied with the "emotion scores." We combined the "emotion scores" with Google's scores to generate our descriptions (example: "The text contains clearly positive emotion"). However, we believe there are many improvements that can be made to our calculations.
Accomplishments that we're proud of
We are proud to have successfully built a working program within 24 hours, while using technology we were not familiar with (Google Cloud). We are also proud to have made something that tackles an issue in our society that we care about.
What we learned
We learned how to use Google Natural Language API and Google App Engine. We also learned about backend development and coding browser extensions.
What's next for Emotilyze
We hope to further improve Emotilyze's analysis of web pages, yielding more accurate results. We may look into AWS natural language processing or other platforms. We also hope to fix any bugs we may have missed while testing at HackUTD.
There a numerous server-side optimizations that could be done to improve Emotilyze's performance and reduce costs, such as storing results in a database so articles only need to be analyzed once.
Built With
- axios
- chrome
- express.js
- google-app-engine
- google-cloud
- google-natural-language
- javascript
- natural-language-processing
- node.js
- vue
- vuetify


Log in or sign up for Devpost to join the conversation.