-
-
NeuroSync 3.0
-
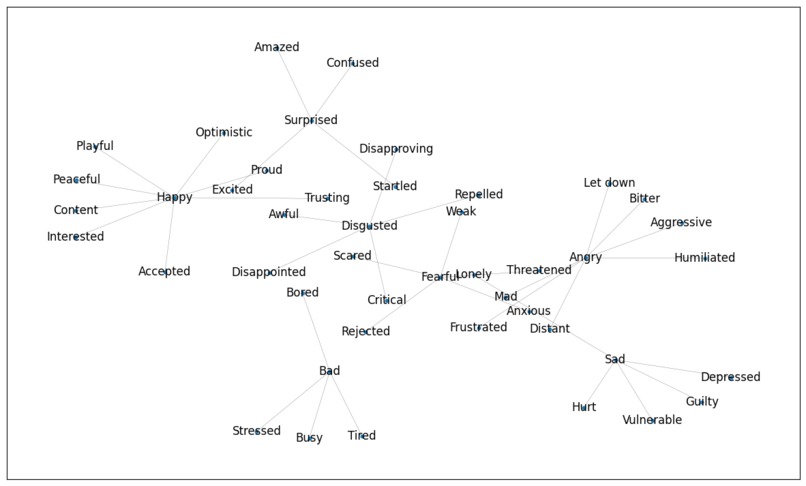
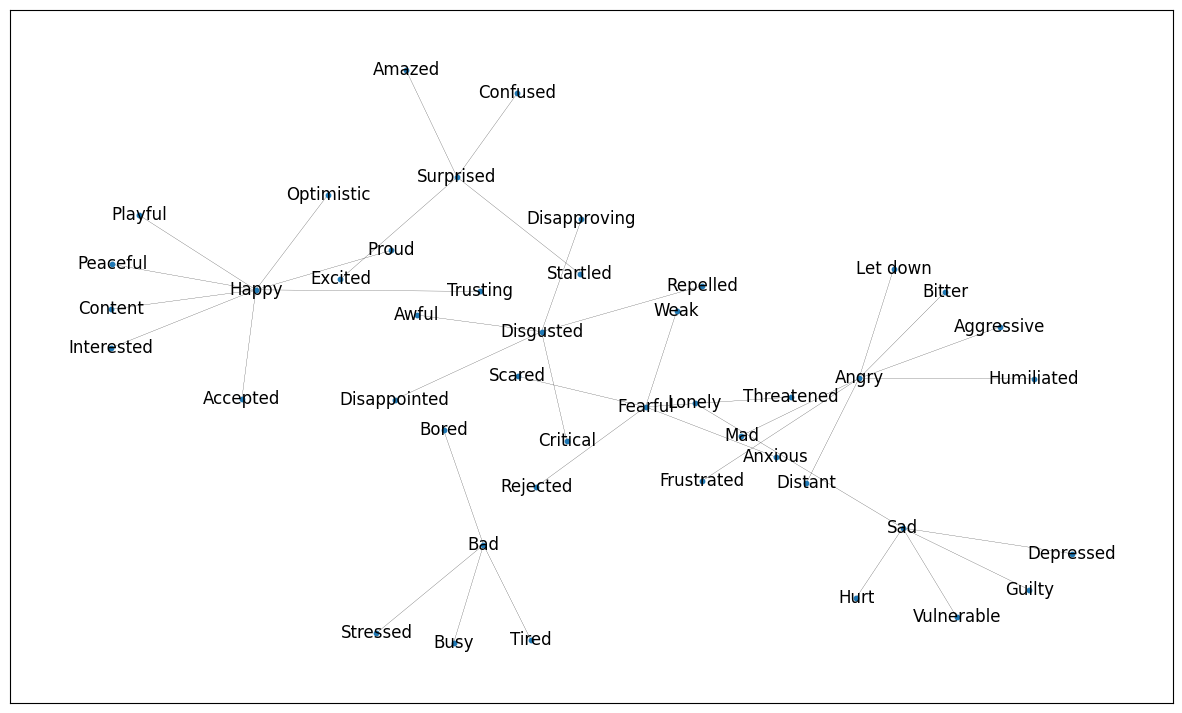
EmoRAG Graph
-
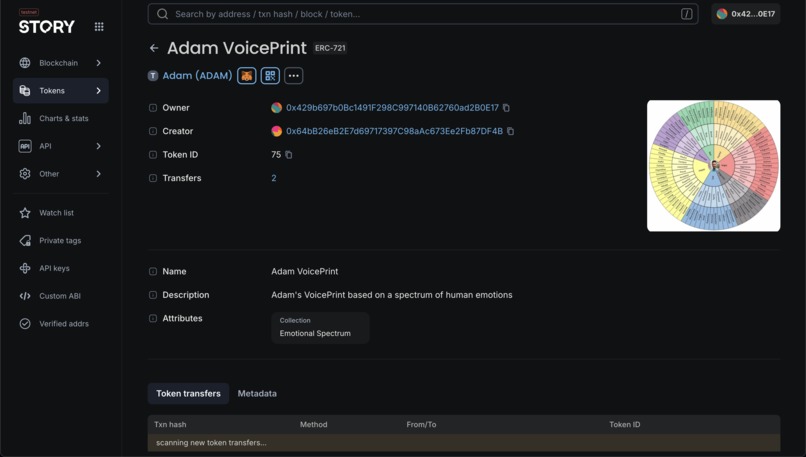
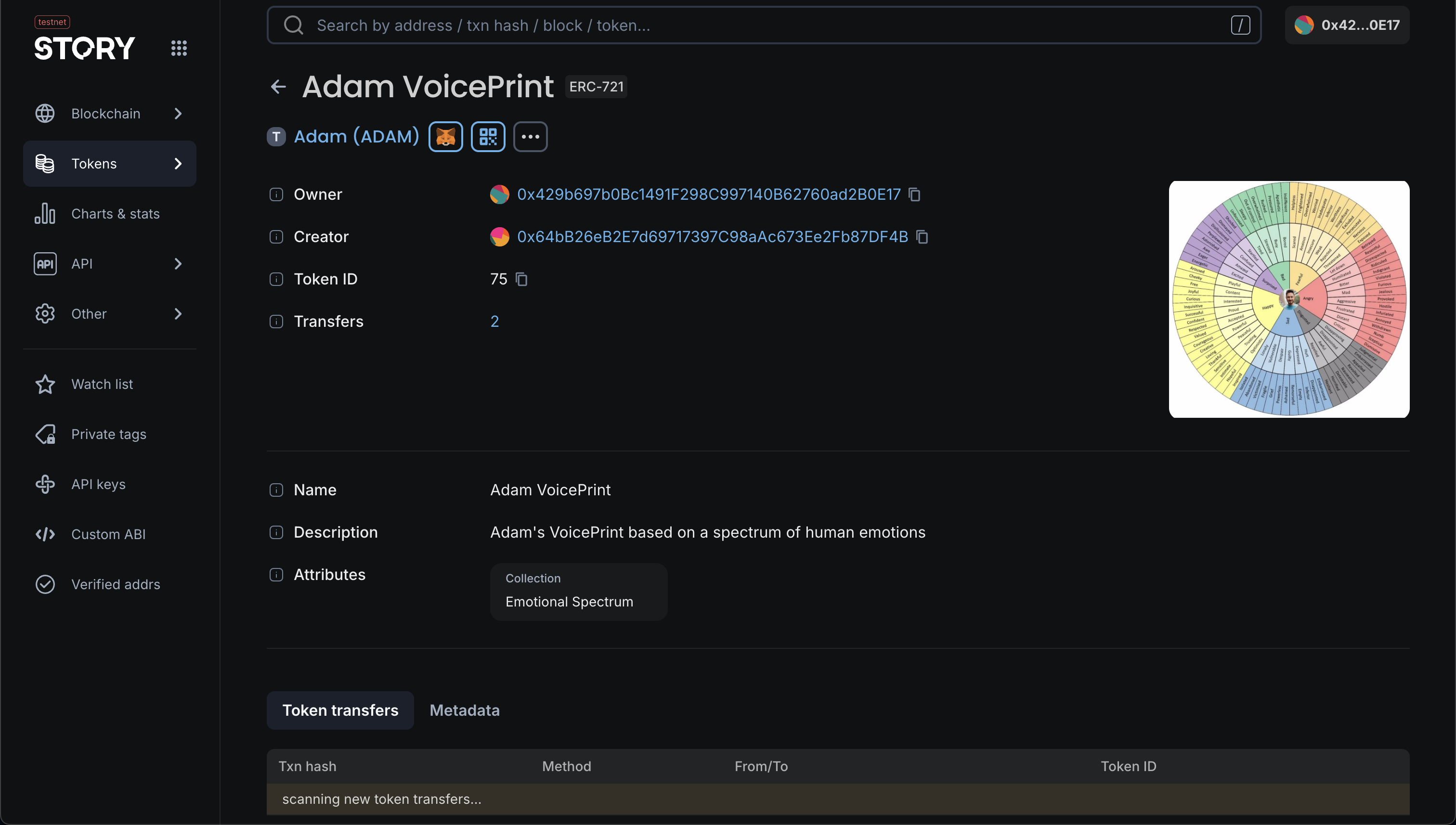
VoicePrint IP Asset
-

NeuroSync 3.0 Analyzing Emotional Patterns

Test EmoRAG now!
Inspiration
AI Voice technology is rapidly advancing, a proliferation of both open and closed source voice models, from ElevenLabs or OpenAI to research institutions, along with a flurry of start-ups are flooding the market with low cost solutions. Estimates suggest the global AI voice market reached $5.4billion last year, a 25% increase on 2023... and no wonder, voice is a very frequent form of communication, hell even the 1-800-CHATGPT hotline was a hit! Despite this heat, AI voices still struggle to completely emulate real human voices, which are made-up of unpredictable and irregular micro-variations that remain difficult to model computationally, in other words, many of us know whether we are talking to a robot or a real person.
 In 'Her' (2013) the protagonist falls in love with OS¹, a voice-based AI Operating System voiced by Scarlett Johansson
In 'Her' (2013) the protagonist falls in love with OS¹, a voice-based AI Operating System voiced by Scarlett Johansson
On the flip side, there are millions of voice actors around the world, many of whom struggle to make a sustainable income from their talent (just take a look at the r/VoiceActing sub-reddit). We thought, rather than having AI continue to attempt to perfectly replicate the human voice and ultimately replace humans completely, let's establish the foundation of a creator economy that allows real human voice actors to contribute to their own RAG dataset, which can be used to generate realistic responses from an AI agent, assistant or reader application. One of the fundamental things missing from an AI voice is the subtle variation of tone, inflection and pacing that communicates authentic human emotion, therefore we set out to create a structured emotional dataset of human speech that can be interpreted during agentic discourse in real time.
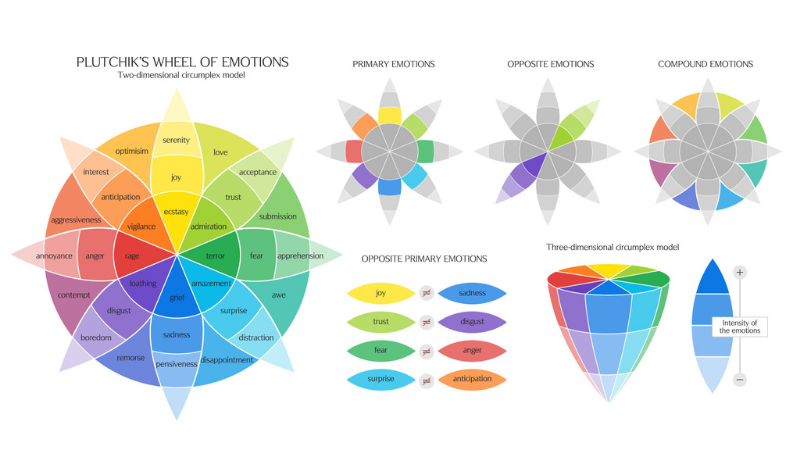 Plutchik's Wheel of Emotions
Plutchik's Wheel of Emotions
We took inspiration from Robert Plutchik's Wheel of Emotions as the underlying structure of speech dataset, and created a rough corpus from scratch to load into a NetworkX package to test it's performance as a graph within ArangoDB. Our goal is to validate EmoRAG as an emotion classification system by having an AI agent analyze and assign appropriate affective states to discrete speech components using multimodal sentiment analysis techniques. Additionally, to establish verifiable attribution of a voice dataset to its respective human owners, we leveraged Story, the next generation blockchain protocol to enable the immutable registration and certification of these granular voice datasets as digital intellectual property.
What it does
EmoRAG
A structured speech dataset built up of a catalog of audio recordings of different phrases representing different emotions. The dataset organizes emotions into primary, secondary and tertiary emotions. There are seven primary emotions included in this version, and varying numbers of secondary and tertiary emotions, examples of each primary emotion with one secondary and tertiary emotion included below:
| Primary Emotion | Secondary Emotion | Tertiary Emotion |
|---|---|---|
| Happy | Optimistic | Inspired |
| Surprised | Amazed | Awed |
| Sad | Lonely | Abandoned |
| Bad | Bored | Indifferent |
| Fearful | Scared | Helpless |
| Angry | Let down | Betrayed |
| Disgusted | Critical | Skeptical |
NeuroSync 3.0
A web portal where EmoRAG can be tested, fine tuned and onchain data can be administered. Dataset is invoked with text-to-speech request, sentiment analysis is ran to determine appropriate emotion using data and libraries set-up in ArangoDB.

How we built it
EmoRAG
Dataset is made up of 76 wav files recorded in house with phrases matching the represented emotion, wavs administered via url & hosted on Firebase. Created as Vertex Collection and the Edge collection was defined when creating the graph.

NeuroSync 3.0
ArangoDB endpoint run into GCP server and TTS handled with Llasa a zero-shot voice cloning library forked from Llama. ERC-721 NFTs instantiated onto Story's Aeneid Testnet and metadata hosted on Pinata.

Challenges we ran into
We only discovered and entered this hackathon last week, so time was in short supply, rapidly getting up to speed with creating a custom audio dataset and combining it with existing emotional classification datasets proved to be too much of a challenge for this time period, meaning that the results are currently limited to some more generalized LLM inferences.
We found that it was difficult to get the Arango LLM chain to give a response in a JSON or other specified format, it always gives an NLP response which means the data is difficult to parse into a format which can be useful, for example, it might suggest a range of different emotions in an order or style it has never used before. Creating AQL queries from the classification as the input queries are directly used to find the values in the collection, a chain of execution between the LLM and the AQL would be really helpful.
Accomplishments that we're proud of
Taking on this hackathon gave us the chance to:
- Create a structured audio dataset from scratch and persist that to ArangoDB
- Run sentiment analysis on said dataset and test with text-to-speech
- Roll a frontend for testing, fine-tuning and setting-up IP Assets on Story Protocol
All of these have opened-up a lot of possibilities, laying the ground for further research and development.
What we learned
There is an abundance of RAG data available that could be used to improve sentiment analysis and develop richer and more accurate emotional responses from user generated speech datasets.
What's next for EmoRAG
Develop EmoRAG to include more parameters which can enable accurate emotional responses when speech is generated. Rolling out a gamified data retrieval system could be a good way to build the dataset at high velocity and scale. Implementing WavRAG should help to achieve a seamless hybrid audio-text experience.










Log in or sign up for Devpost to join the conversation.