-

Emojipastafy on Slack
-

Emojipastafy on Telegram
-
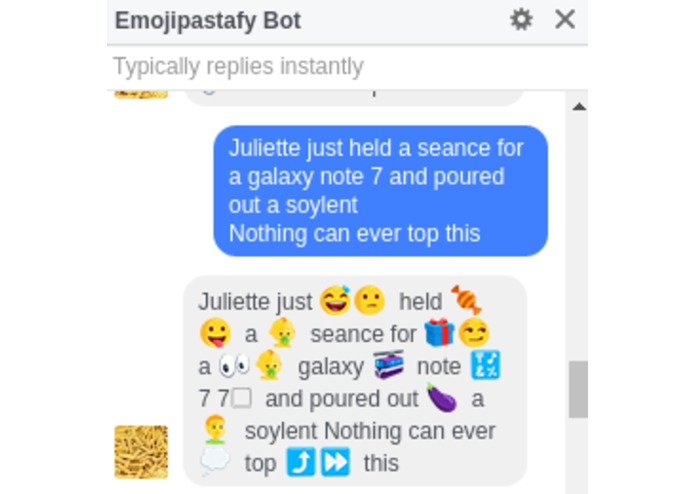
Emojipastafy on Messenger



Inspiration
Automation is gradually taking over more jobs and learning more social skills. Our dream is a future where all memes are 100% computer generated so we can devote more time to looking at memes.
What it does
Emojipastafier takes whatever text you give it and tries to intersperse meaningful emojis to make a beautiful emojipasta to copypasta wherever you like.
How we built it
TL;DR
Take data from reddit, make it lowercase and lemmatized, and train word2vec using this data. Then look up words in an input in a dictionary of emojis to try to find a match, then try to find the closest emoji in context using the word2vec model if that fails.
TL;R
The Emojipastafier — aka the Pasta Chef™ — is trained on a small corpus of posts and comments from the reddit community /r/emojipasta and a very small selection of tweets with emojis that could be scraped. The corpus is normalized using a preprocessing script that takes every token (i.e. words, emojis and other symbols), strips them of punctuation and converts them to a lemmatized, lowercase form. Each data entry is treated as a sentence and passed to gensim.word2vec to create a model for word embeddings that allows us to look up the similarity of two words in the vocabulary it's trained on.
When given text to emojify, the Chef slices the input by word and checks two sources for emojis:
A tagged database of emojis, significantly smaller than the NLP model. If the word is found here, it's treated as authoritative, any emojis found from it are used and no other searching is done.
The word2vec NLP model. This model attempts to find matching emojis by finding the top 75 most similar tokens to the word, then extracting tokens that are emojis.
The Chef picks a random number of times to show emojis for a given word. If suitable emojis were found and the bot didn't roll a zero, it'll randomly select emojis from the list it's given and put them after the word. After repeating this process for every individual word, the end result is a nice emojipasta that can be fed back to the user.
Challenges we ran into
A lot of time early on was spent trying to get word2vec to work and assembling a suitable corpus with emojis in it. A lot of time later on was spent waiting for Heroku deployments until realizing that heroku has a command for running stuff locally.
Accomplishments that we're proud of
It actually works and it's mostly funny, which is nothing short of incredible.
What we learned
- Assembling data from large datasets using big data processing, primarily Google BigQuery on a set of reddit comments and posts.
- Training basic sparse neural networks like word2vec to work with contexts of words and finding other similar tokens in that context.
- Using the Messenger, Slack and Telegram APIs.
- Deploying scalable and fault-tolerant web apps using services like Heroku.
What's next for Emojipastafier
Improved word-to-emoji detection would be nice and would probably require a larger corpus full of emojis.











Log in or sign up for Devpost to join the conversation.